本文主要是介绍数据结构——lesson5栈和队列详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
hellohello~这里是土土数据结构学习笔记🥳🥳

💥个人主页:大耳朵土土垚的博客
💥 所属专栏:数据结构学习笔记
💥对于顺序表链表有疑问的都可以在上面数据结构的专栏进行学习哦~感谢大家的观看与支持🌹🌹🌹
有问题可以写在评论区或者私信我哦~
前言:
之前的博客我们学习了数据结构中的顺序表和链表,现在我们一起回顾一下它们各自的优缺点。
首先是顺序表:
✨优点:
1.支持下标的随机访问(因为是数组的形式);
2.尾插尾删比较方便,效率不错;
3.CPU高速缓存命中率较高;
✨ 缺点:
1.前面部分插入删除数据需要挪动数据,时间复杂度为O(n);
2.空间不够需要扩容——一方面扩容需要付出代价例如异地扩容, 另一方面扩容一般还伴随着空间的浪费;
其次是链表:
✨优点:
1.任意位置插入删除数据都比较方便高效,时间复杂度为O(1);
2.按需申请释放空间
✨缺点:
1.不支持下标的随机访问;
2.CPU高速缓存命中率较低;
我们发现顺序表的优点和缺点恰好对应着链表的缺点和优点,顺序表和链表各自都有它们独特的作用与优势,不存在优劣之分。大家在使用的时候要根据自己的需求去选择哦~
一、栈
1.1栈的概念及结构
栈: 一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
1.2栈的实现
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小。

如图所示,左边是栈尾,右边是栈顶(进行出栈也就是删除操作);
以下是栈的实现:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>typedef int STDataType;// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack//定义一个结构体表现栈
{STDataType* a;int top; // 栈顶int capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回true,如果不为空返回false
bool StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
栈实现包括初始化,入栈,出栈,获取栈顶元素,获取栈中有效元素个数,判断栈是否为空以及销毁栈这7个函数。
下面我们来具体实现栈:
(1)初始化栈
void StackInit(Stack* ps);
// 初始化栈
void StackInit(Stack* ps)
{assert(ps);ps->a = NULL;ps->capacity = 0;ps->top = 0;//指向栈顶的下一个数据//ps->top = -1; //则指向栈顶数据
}
这里要注意ps->top = 0 代表的是栈顶元素的下一个;ps->top = -1才指向栈顶元素,因为后面的函数每增加一个元素,ps->top++,如果初始化top = 0,加一个元素后,top=1;表示的位置是下标为1(其本质是数组,下标为1的位置表示第二个元素),但确间接表明了栈中元素的个数刚好为1,所以为了后续方便,我们选择初始化top=0;当然你也可以自由选择。
(2)入栈
void StackPush(Stack* ps, STDataType data);
void StackPush(Stack* ps, STDataType data)
{assert(ps);if (ps->top == ps->capacity)//判断空间是否满了{//空间capacity满了就需要扩容STDataType newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;//判断是否扩容过,如果capacity为0就增加4//个单位空间,否则开辟capacity的2倍空间ps->capacity = newcapacity;//扩容后capacity要等于newcapacityps->a = (STDataType*)realloc(ps->a, newcapacity * sizeof(STDataType));if (ps->a == NULL){perror("realloc fail");return;}}ps->a[ps->top] = data;//入栈ps->top++;//栈顶+1}
这里入栈要注意判断栈的容量是否满了,满了需要使用realloc函数扩容,对于realloc函数有疑问的小伙伴可以查看土土的博客——C语言动态内存函数介绍
(3)出栈
void StackPop(Stack* ps)
// 出栈
void StackPop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//判断非空ps->top--;
}
出栈就比较简单,只需将top–即可,但是同时也要注意判断栈不为空哦~判空函数StackEmpty(ps)将在后面实现
(4)获取栈顶元素
STDataType StackTop(Stack* ps)
// 获取栈顶元素
STDataType StackTop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//判断非空return ps->a[ps->top-1];
}
是时候考验你们的专注力了,这里返回栈顶元素用的是top-1;有小伙伴知道为什么不直接用top吗?答案我们放在下一个获取栈中有效元素个数函数中揭晓。
(5)获取栈中有效元素个数
int StackSize(Stack* ps)
// 获取栈中有效元素个数
int StackSize(Stack* ps)
{assert(ps);return ps->top;
}上一个函数获取栈顶元素我们使用的是top-1,是因为在初始化函数时我们就介绍过将top初始化为0,指向栈顶元素的下一个,所以要获取栈顶元素我们要将top-1;依此类推栈中有效元素个数就恰好是top了。
(6)检测栈是否为空
bool StackEmpty(Stack* ps)
// 检测栈是否为空,如果为空返回true,如果不为空返回false
bool StackEmpty(Stack* ps)
{assert(ps);/*if (ps->top == 0)return true;elsereturn false;*/return ps->top == 0;
}
这里可以使用if语句来判断,也可以如上面代码所示直接使用return返回。
(7)销毁栈
void StackDestroy(Stack* ps)
// 销毁栈
void StackDestroy(Stack* ps)
{assert(ps);free(ps->a);ps->capacity = 0;ps->a = NULL;ps->top = 0;
}
这里就不过多赘述,使用free销毁即可;因为数组时地址连续的一段物理空间,所以只要数组首元素地址即可free整个数组与链表需要遍历不同。
栈实现可视化如下图所示:
代码如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include"stack.h"
void Sttest()
{Stack ST;StackInit(&ST);StackPush(&ST, 1);StackPush(&ST, 2);StackPush(&ST, 3);StackPush(&ST, 4);while (ST.top)//打印栈{printf("%d", StackTop(&ST));StackPop(&ST);//打印一个出一个}StackDestroy(&ST);}
int main()
{Sttest();return 0;
}
二、队列
2.1队列的概念及结构
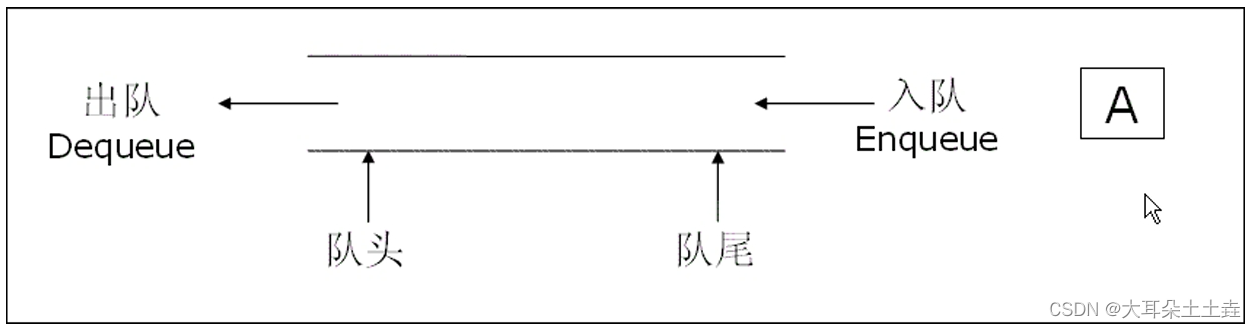
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)
入队列:进行插入操作的一端称为队尾
出队列:进行删除操作的一端称为队头
发现进行删除操作的都是队头,无论栈还是队列;
队列根据其名字,我们不难发现类似于我们生活中的排队,先排队的肯定会先出去;
2.2队列的实现
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数组头上出数据,效率会比较低。
// 链式结构:表示队列
typedef int QDataType;
typedef struct QListNode
{ struct QListNode* pNext; QDataType data;
}QNode; // 队列的结构
typedef struct Queue
{
QNode* front;
QNode* rear;
}Queue;
// 初始化队列
void QueueInit(Queue* q);
// 队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队头出队列
void QueuePop(Queue* q);
// 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列中有效元素个数
int QueueSize(Queue* q);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q);
// 销毁队列
void QueueDestroy(Queue* q);
队列相较于栈定义了两个结构体来表示,一个结构体QNode表示节点,另一个结构体Queue则用来表示队列的头尾指针,展示队列的结构。
队列也包含了初始化,队尾入队列,队头出队列,获取队列头部元素,获取队列尾部元素,以及有效元素个数,判空,销毁这八个函数。
(1)初始化队列
void QueueInit(Queue* q);
// 初始化队列
void QueueInit(Queue* q)
{assert(q);q->front = NULL;q->rear = NULL;
}
将Queue结构体初始化即可
(2)队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队尾入队列
void QueuePush(Queue* q, QDataType data)
{assert(q);QNode* newnode = (QNode*)malloc(sizeof(QNode));//创建新节点if (newnode == NULL){perror("malloc fail");return;}newnode->data = data;newnode->pNext = NULL;//队列为空的情况入队列if (QueueEmpty(q)){q->front = newnode;q->rear = newnode;return;}//队列不为空的情况入队列else{q->rear->pNext = newnode;q->rear = newnode;return;}
}
队尾入队列首先要记得malloc一个新节点,然后要记得判断队列是否为空,分为两种情况。判空函数将在后面实现。
(3)队头出队列
void QueuePop(Queue* q);
// 队头出队列
void QueuePop(Queue* q)
{assert(q);assert(!QueueEmpty(q));//判断队列非空QNode* tmp = q->front;//先保存队头指针q->front = tmp->pNext;free(tmp);
}
队头出队列要记得free释放出去节点的空间。
(4)获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列头部元素
QDataType QueueFront(Queue* q)
{assert(q);assert(!QueueEmpty(q));//判断队列非空return q->front->data;}通过结构体Queue的front指针可以直接找到头返回即可。
(5)获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q)
{assert(q);assert(!QueueEmpty(q));//判断队列非空return q->rear->data;
}
同样通过结构体Queue的rear指针可以直接找到尾返回即可。
(6) 获取队列中有效元素个数
int QueueSize(Queue* q)
// 获取队列中有效元素个数
int QueueSize(Queue* q)
{assert(q);assert(!QueueEmpty(q));//判断队列非空int count = 0;//记录元素个数QNode* cur = q->front;while (cur){cur = cur->pNext;count++;}return count;
}
这里队列用的是链表的结构,所以需要使用循环遍历来获取有效元素的个数。
(7)检测队列是否为空
bool QueueEmpty(Queue* q);
// 检测队列是否为空,如果为空返回true,非空返回false
bool QueueEmpty(Queue* q)
{assert(q);return q->front == NULL;}
队列头指针为空即没有元素进入队列。
(8)销毁队列
void QueueDestroy(Queue* q);
// 销毁队列
void QueueDestroy(Queue* q)
{assert(q);while (q->front){QueuePop(q);}
}QueuePop()函数将元素从队头删除的同时也使用了free释放空间,所以这里直接使用该函数即可。
队列实现可视化如下图所示:

实现代码如下:
#include"queue.h"void Qtest()
{Queue QT;QueueInit(&QT);QueuePush(&QT, 1);QueuePush(&QT, 2);QueuePush(&QT, 3);QueuePush(&QT, 4);while (QT.front){printf("%d", QueueFront(&QT));QueuePop(&QT);}QueueDestroy(&QT);
}
int main()
{Qtest();return 0;
}
三、练习题
1.一个栈的初始状态为空。现将元素1、2、3、4、5、A、B、C、D、E依次入栈,然后再依次出栈,则元素出
栈的顺序是( )。
A 12345ABCDEB EDCBA54321C ABCDE12345D 54321EDCBA2.若进栈序列为 1,2,3,4 ,进栈过程中可以出栈,则下列不可能的一个出栈序列是()
A 1,4,3,2B 2,3,4,1C 3,1,4,2D 3,4,2,13.以下( )不是队列的基本运算?
A 从队尾插入一个新元素
B 从队列中删除第i个元素
C 判断一个队列是否为空
D 读取队头元素的值答案:BCB
四、结语
栈和队列有很多的相似之处,尽管栈是队头进入删除数据(后进先出),队列是队尾入数据,队头删数据(先进后出),但其本质是一样的。熟悉了栈和队列后,相信大家对于顺序表和链表的理解也会更上一层楼。以上就是栈和队列的学习啦~ 完结撒花~🥳🥳🎉
这篇关于数据结构——lesson5栈和队列详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





