本文主要是介绍RK3568笔记十八:MobileNetv2部署测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
若该文为原创文章,转载请注明原文出处。
记录MobileNetv2训练测试
一、环境
1、平台:rk3568
2、开发板: ATK-RK3568正点原子板子
3、环境:buildroot
4、虚拟机:正点原子提供的ubuntu 20
二、MobileNetv2简介
MobileNet ,它是谷歌研究人员于 2017 年开发的一种 CNN 架构,用于将计算机视觉有效地融入 手机和机器人等小型便携式设备中,而不会显著降低准确性。后续进一步为了解决实际应用中的
一些问题,推出了 v2,v3 版本。
MobileNet 提出了一种深度可分离卷积(Depthwise Separable Convolutions),该卷积不同于标准卷
积,可以大幅度减小模型规模的同时保证模型性能下降很小。
深度可分离卷积分为两个操作:深度卷积 (DW) 和逐点卷积 (PW)。
• 深度卷积 (DW) 和标准卷积的不同之处在于,对于标准卷积,其卷积核是应用于所有的输
入通道,而 DW 卷积针对每个输入通道采用不同的卷积核,也就是说,一个卷积核对应一
个输入通道。
• 逐点卷积 (PW) 实际上就是普通的卷积,只不过其采用 1x1 的卷积核。
MobileNet 设计了两个控制网络大小全局超参数(宽度乘系数和分辨率乘系数),通过这两个超参
数来进行速度和准确率的权衡,使用者可以根据设备的限制调整网络。
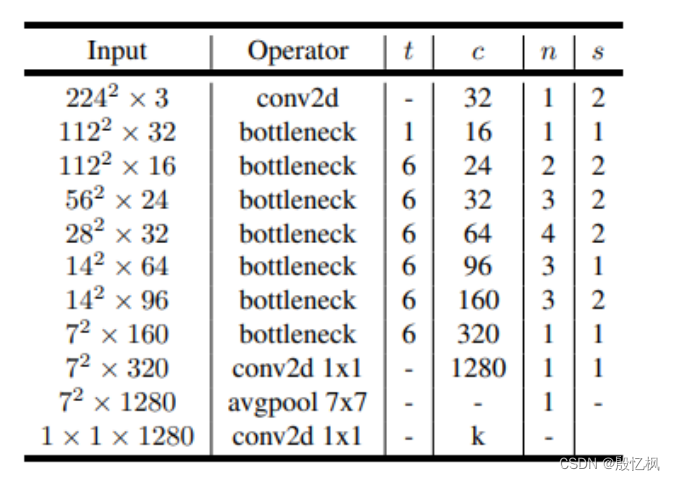
具体参考该论文
三、环境搭建
1、创建环境
conda create -n MobileNetv2_env python=3.82、激活环境
conda activate MobileNetv2_env3、安装pytorch
pip install torch==1.13.1+cpu torchvision==0.14.1+cpu torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cpu -i https://pypi.tuna.tsinghua.edu.cn/simplepip install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple3、下载数据
https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz下载需要APN,需要数据评论留言
数据集下载后解压到同组目录
4、train
直接上代码
import os
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from tqdm import tqdm
from PIL import Image
from torch.utils.data import DataLoader,Datasetfrom model import MobileNetV2# 自定义数据集FlowerData
# 读取的数据目录结构:
"""directory/├── class_x│ ├── xxx.jpg│ ├── yyy.jpg│ └── ... └── class_y├── 123.jpg├── 456.jpg└── ...
"""
class FlowerData(Dataset):def __init__(self, root_dir, transform=None):self.root_dir = root_dirself.transform = transformclasses = sorted(entry.name for entry in os.scandir(self.root_dir) if entry.is_dir())class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}self.classes = classesself.class_to_idx = class_to_idxself.images = self.get_images(self.root_dir, self.class_to_idx)def __len__(self):return len(self.images)def __getitem__(self,index):path, target = self.images[index]with open(path, "rb") as f:img = Image.open(f)image = img.convert("RGB")if self.transform:image = self.transform(image) #对样本进行变换return image,targetdef get_images(self, directory, class_to_idx):images = []for target_class in sorted(class_to_idx.keys()):class_index = class_to_idx[target_class]target_dir = os.path.join(directory, target_class)if not os.path.isdir(target_dir):continuefor root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):for fname in sorted(fnames):path = os.path.join(root, fname)item = path, class_indeximages.append(item)return images# 训练和评估
def fit(epochs, model, loss_function, optimizer, train_loader, validate_loader, device):t0 = time.time()best_acc = 0.0save_path = './MobileNetV2.pth'train_steps = len(train_loader)model.to(device)for epoch in range(epochs):# 训练model.train()running_loss = 0.0train_acc = 0.0train_bar = tqdm(train_loader, total=train_steps) # 进度条for step, (images, labels) in enumerate(train_bar):optimizer.zero_grad() # grad zero logits = model(images.to(device)) # Forwardloss = loss_function(logits, labels.to(device)) # lossloss.backward() # Backwardoptimizer.step() # optimizer.step_, predict = torch.max(logits, 1)train_acc += torch.sum(predict == labels.to(device))running_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)train_accurate = train_acc / len(train_loader.dataset)# 验证model.eval()val_acc = 0.0with torch.no_grad():val_bar = tqdm(validate_loader, total=len(validate_loader)) # 进度条for val_data in val_bar:val_images, val_labels = val_dataoutputs = model(val_images.to(device))_, val_predict = torch.max(outputs, 1)val_acc += torch.sum(val_predict == val_labels.to(device))val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1, epochs)val_accurate = val_acc / len(validate_loader.dataset)print('[epoch %d] train_loss: %.3f - train_accuracy: %.3f - val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, train_accurate, val_accurate))# 保存最好的模型if val_accurate > best_acc:best_acc = val_accuratetorch.save(model.state_dict(), save_path)print("\n{} epochs completed in {:.0f}m {:.0f}s.".format(epochs,(time.time() - t0) // 60, (time.time() - t0) % 60))def main():# 有GPU,就使用GPU训练device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))# 超参数batch_size = 32epochs = 10learning_rate = 0.0001data_transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 初始化自定义FlowerData类,设置数据集所在路径以及变换flower_data = FlowerData('./flower_photos',transform=data_transform)print("Dataset class: {}".format(flower_data.class_to_idx))# 数据集随机划分训练集(80%)和验证集(20%)train_size = int(len(flower_data) * 0.8)validate_size = len(flower_data) - train_sizetrain_dataset, validate_dataset = torch.utils.data.random_split(flower_data, [train_size, validate_size])print("using {} images for training, {} images for validation.".format(len(train_dataset),len(validate_dataset)))nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])print('Using {} dataloader workers every process \n'.format(nw))train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=nw)validate_loader = DataLoader(validate_dataset, batch_size=1, shuffle=True, num_workers=nw)# 实例化模型,设置类别个数num_classesnet = MobileNetV2(num_classes=5).to(device)# 使用预训练权重 https://download.pytorch.org/models/mobilenet_v2-b0353104.pthmodel_weight_path = "./mobilenet_v2-b0353104.pth"assert os.path.exists(model_weight_path), "file {} dose not exist.".format(model_weight_path)pre_weights = torch.load(model_weight_path, map_location=device)# print("The type is:".format(type(pre_weights)))pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)# 通过requires_grad == False的方式来冻结特征提取层权重,仅训练后面的池化和classifier层for param in net.features.parameters():param.requires_grad = False# 使用交叉熵损失函数loss_function = nn.CrossEntropyLoss()# 使用adam优化器, 仅仅对最后池化和classifier层进行优化params = [p for p in net.parameters() if p.requires_grad]optimizer = optim.Adam(params, lr=learning_rate)# 输出网络结构#print(summary(net, (3, 224, 224)))# 训练和验证模型fit(epochs, net, loss_function, optimizer, train_loader, validate_loader, device)if __name__ == '__main__':main()
开始训练,执行命令
python train.py
电脑是CPU版本,大概等待1小时,训练完成。会在当前目录下生成MobileNetV2.pth模型
四、pt模型转换
训练后保存了 MobileNetV2.pth 模型权重文件,部署需要导出 torchscript 的模型。
export.py
import torch
import os
from model import MobileNetV2if __name__ == '__main__':# 模型model = MobileNetV2(num_classes=5)# 加载权重model.load_state_dict(torch.load("./MobileNetV2.pth"))model.eval()# 保存模型trace_model = torch.jit.trace(model, torch.Tensor(1, 3, 224, 224))trace_model.save('./MobileNetV2.pt')执行上面程序会导出MobileNetV2.pt模型
五、部署
1、RKNN模型转换
使用 RKNN Toolkit2 工具,将导出的模型转换出 rknn 模型,并进行简单模型测试。
RKNN Toolkit2 工具环境安装,参考正点原子手册。
pt2rknn.py
import numpy as np
import cv2
from rknn.api import RKNNclass_names = ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']def show_outputs(output):output_sorted = sorted(output, reverse=True)top5_str = '\n class prob\n'for i in range(5):value = output_sorted[i]index = np.where(output == value)topi = '{}: {:.3}% \n'.format(class_names[(index[0][0])], value*100)top5_str += topiprint(top5_str)def show_perfs(perfs):perfs = 'perfs: {}\n'.format(perfs)print(perfs)def softmax(x):return np.exp(x)/sum(np.exp(x))if __name__ == '__main__':model = './MobileNetV2.pt'input_size_list = [[1, 3, 224, 224]]# Create RKNN objectrknn = RKNN()# Pre-process config, 默认设置rk3588print('--> Config model')rknn.config(mean_values=[[128, 128, 128]], std_values=[[128, 128, 128]], target_platform='rk3568')print('done')# Load modelprint('--> Loading model')ret = rknn.load_pytorch(model=model, input_size_list=input_size_list)if ret != 0:print('Load model failed!')exit(ret)print('done')# Build modelprint('--> Building model')# ret = rknn.build(do_quantization=True, dataset='./dataset.txt')ret = rknn.build(do_quantization=False)if ret != 0:print('Build model failed!')exit(ret)print('done')# Export rknn modelprint('--> Export rknn model')ret = rknn.export_rknn('./MobileNetV2.rknn')if ret != 0:print('Export rknn model failed!')exit(ret)print('done')#Set inputsimg = cv2.imread('./sun.jpg')img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = cv2.resize(img, (224,224))img = np.expand_dims(img, 0)# Init runtime environmentprint('--> Init runtime environment')ret = rknn.init_runtime()if ret != 0:print('Init runtime environment failed!')exit(ret)print('done')# Inferenceprint('--> Running model')outputs = rknn.inference(inputs=[img])# np.save('./MobileNetV2.npy', outputs[0])print(outputs[0][0])show_outputs(softmax(np.array(outputs[0][0])))print('done')rknn.release()
在虚拟机下执行
python pt2rknn.py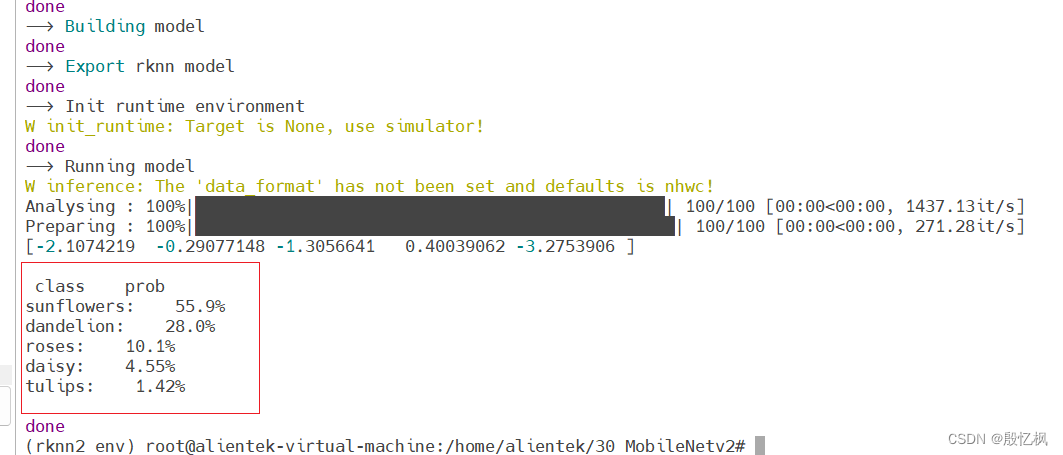
模型转换成功,并测试正常。有点要注意,平台是RK3568.
2、部署测试
把MobileNetV2.rknn test.py tulips.jpg这三个文件通过adb上传到开发板,打开开发板终端
执行测试程序。
test.py
import cv2
import numpy as np
from rknnlite.api import RKNNLiteINPUT_SIZE = 224RK3566_RK3568_RKNN_MODEL = 'MobileNetV2.rknn'
RK3588_RKNN_MODEL = 'MobileNetV2.rknn'class_names = ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']def softmax(x):return np.exp(x)/sum(np.exp(x))def show_outputs(output):output_sorted = sorted(output, reverse=True)top5_str = '\n Class Prob\n'for i in range(5):value = output_sorted[i]index = np.where(output == value)topi = '{}: {:.3}% \n'.format(class_names[(index[0][0])], value*100)top5_str += topiprint(top5_str)if __name__ == '__main__':rknn_lite = RKNNLite()# load RKNN modelprint('--> Load RKNN model')ret = rknn_lite.load_rknn(RK3566_RK3568_RKNN_MODEL)if ret != 0:print('Load RKNN model failed')exit(ret)print('done')ori_img = cv2.imread('./tulips.jpg')img = cv2.cvtColor(ori_img, cv2.COLOR_BGR2RGB)img = cv2.resize(img, (224,224))# init runtime environmentprint('--> Init runtime environment')# run on RK356x/RK3588 with Debian OS, do not need specify target.#ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0)ret = rknn_lite.init_runtime()if ret != 0:print('Init runtime environment failed')exit(ret)print('done')# Inferenceprint('--> Running model')outputs = rknn_lite.inference(inputs=[img])print(outputs[0][0])show_outputs(softmax(np.array(outputs[0][0])))print('done')rknn_lite.release()
测试结果正常,部署成功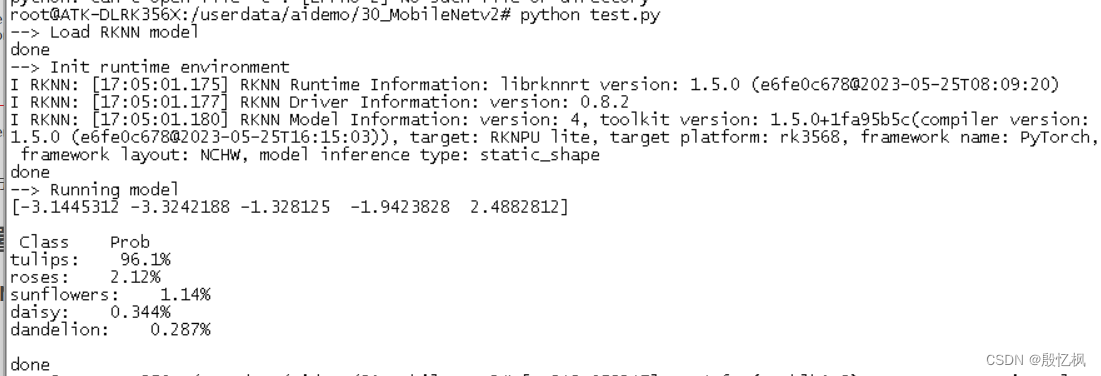
六、参考链接
https://pytorch.org
https://arxiv.org/abs/1801.04381
https://arxiv.org/pdf/1704.04861
https://github.com/rockchip-linux/rknn-toolkit2如有侵权,或需要完整代码,请及时联系博主。
这篇关于RK3568笔记十八:MobileNetv2部署测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








