本文主要是介绍DNS-正反向解析 包含排错过程:2h的排错不负所望,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
yigiao
- ----域名系统----
- -----域名结构----
- DNS-----服务器类型
- 构建DNS域名解析服务器步骤
- 构建域名服务器反向解析的详细步骤
- 实验错误指出:2小时排错的结果。。根本看不出来的小细节如下指出 不看一定后悔。
----域名系统----
1、DNS定义:DNS是“域名系统”的英文缩写。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
2、DNS使用端口:DNS服务使用TCP和UDP的53端口,TCP的53端口用于连接DNS服务器,UDP的53端口用于解析DNS。
3、DNS域名长度限制:每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符
4、DNS作用:正向解析:根据域名查找对应的IP地址;反向解析:根据IP地址查找对应的域名
-----域名结构----
根域:位于树状结构最顶层,用"."表示
顶级域:一般代表一种类型的组织机构或国家地区;
如.net(网络供应商)、.com(工商企业)、.org(团体组织)、.edu(教育结构)、.gov(政府部门)、.cn(中国国家域名)
二级域:用来标明顶级域内的一个特定的组织,国家顶级域下面的二级域名由国家部门统一管理
子域:二级域下所创建的各级域统称为子域,各个组织或用户可以自由申请注册自己的域名
主机:主机位于域名空间最下层,就是一台具体的计算机
域名与IP地址之间是多对一的关系,一个IP地址不一定只对应一个域名,且一个域名只可以对应一个IP地址
DNS-----服务器类型
主域名服务器:负责维护一个区域的所有域名信息,是特定的所有信息的权威信息源,数据可以修改。构建主域名服务器时,需要自行建立所负责区域的地址数据文件。
从域名服务器:当主域名服务器出现故障、关闭或负载过重时,从域名服务器作为备份服务提供域名解析服务。从域名服务器提供的解析结果不是由自己决定的,而是来自于主域名服务器。构建从域名服务器时,需要指定主域名服务器的位置,以便服务器能自动同步区域的地址数据库。
缓存域名服务器:只提供域名解析结果的缓存功能 目的在于提高查询速度和效率,但没有域名数据库。
它从某个远程服务器取得每次域名服务器查询的结果,并将它放在高速缓存中,以后查询相同的信息时用它予以响应。缓存域名服务器不是权威性服务器,因为提供的所有信息都是间接信息。构建缓存域名服务器时,必须设置根域或指定其他DNS服务器作为解析来源。
转发域名服务器:负责所有非本地域名的本地查询。转发域名服务器接到查询请求后,在其缓存中查找,如找不到就将请求依次转发到指定的域名服务器,直到查找到结果为止,否则返回无法映射的结果。
构建DNS域名解析服务器步骤
安装bind软件包



添加正向区域配置


配置正向区域数据文件


启动服务,关闭防火墙

指向本机ip

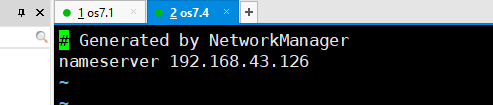
测试


构建域名服务器反向解析的详细步骤
第一步:修改/etc/named.rfc1912.zones配置文件,添加反向区域配置

图2:

图3:

第四步 解析测试

实验错误指出:2小时排错的结果。。根本看不出来的小细节如下指出 不看一定后悔。
图2:错误在于 add 应该是 addr
图3:错误弄了2个小时,做了3遍,博客查遍了 最后百度查到的

正确案例:
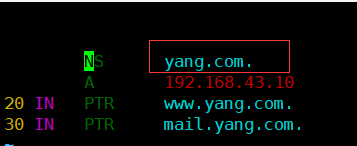
这篇关于DNS-正反向解析 包含排错过程:2h的排错不负所望的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







