本文主要是介绍AI学习(5):PyTorch-核心模块(Autograd):自动求导,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.介绍
在深度学习中,自动求导是一项核心技术,它使得我们能够方便地计算梯度并优化模型参数。
PyTorch提供了一个强大的自动求导模块(Autograd),它可以自动计算张量的导数得出梯度信息,同时也支持高阶导数计算。
1.1 概念词
在学习PyTorch的过程中,经常会看到这些词汇: 自动求导、梯度计算、前向传播、反向传播、动态计算图等,下面是一些简单介绍:
- 自动求导:
PyTorch的Autograd模块负责自动计算张量的梯度。当我们在PyTorch中定义了一个张量,并设置了requires_grad=True时,PyTorch会自动跟踪对该张量的所有操作,并构建一个动态计算图。 - 梯度计算:梯度是函数在某一点上的导数,表示函数在该点的变化率。在深度学习中,梯度可以告诉我们在参数空间中,哪些方向可以使得损失函数值减小最快。
PyTorch的Autograd模块通过构建计算图并使用反向传播算法,自动计算张量的梯度。 - 前向传播:前向传播是指数据从输入层经过隐藏层传递到输出层的过程。在前向传播过程中,每一层的输入经过权重和偏置的线性变换,然后经过激活函数计算得到输出。
- 反向传播:反向传播是训练神经网络时使用的一种优化算法。它利用链式法则计算损失函数对模型参数的梯度,从而实现模型参数的更新。在
PyTorch中,反向传播算法通过计算动态计算图的梯度来实现。 - 动态计算图:动态计算图是
PyTorch中的一个重要特性,它与静态计算图不同,可以根据代码的执行情况动态构建计算图。动态计算图使得PyTorch更加灵活,可以处理各种动态的模型结构和数据流动。
他们之间的依赖关系:
- 自动求导依赖于动态计算图,因为动态计算图记录了张量之间的依赖关系,从而使得
PyTorch能够跟踪对张量的操作; - 梯度计算依赖于自动求导和动态计算图,因为梯度是通过自动求导和反向传播算法在动态计算图中计算得到的。
- 前向传播和反向传播是损失函数优化的过程,依赖于梯度计算和动态计算图。
2.导数
2.1 导数定义
在学习自动求导模块(Autograd)之前,我们先简单回忆下高数中是如何定义导数的:

2.2 导数作用
从导数的定义上来看,不但理解起来比较费劲,也很难看出导数在深度学习中有什么作用,针对大部分场景的求导,本质上都是求某个函数在某一点的切线。如下图是一个经典的切线模型,求的是 x 0 x_0 x0处的导数:
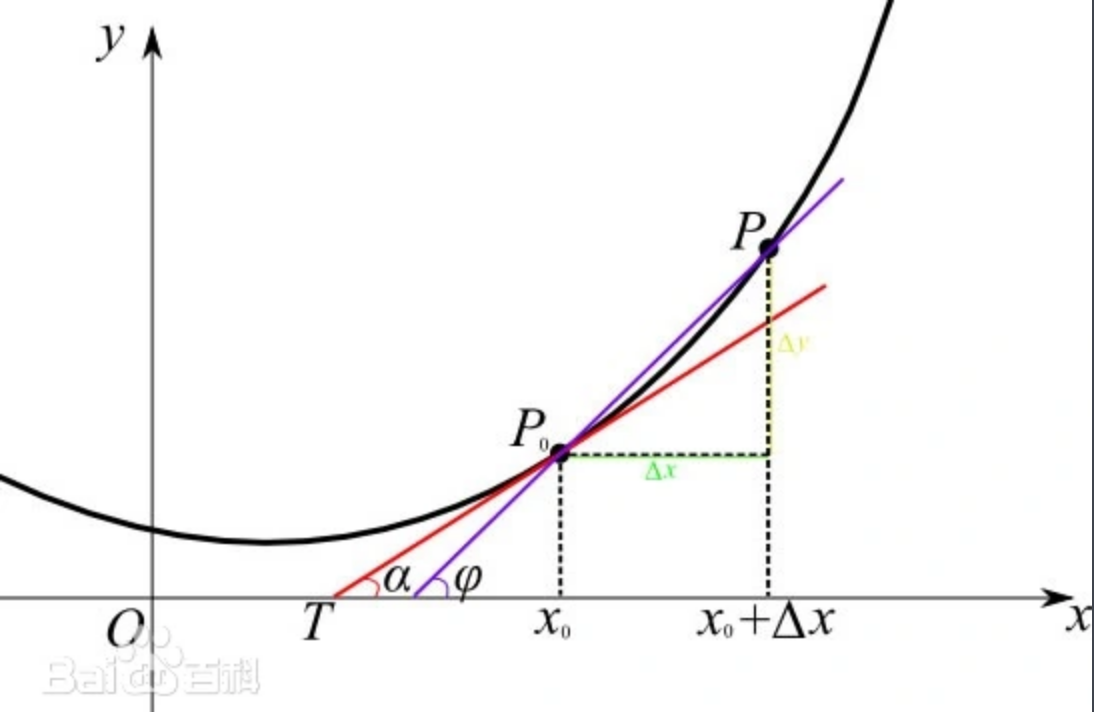
看到这里,可能还是没有想明白,导数在深度学习中到底有什么作用?在学习AI时,经常会听到道士下山的故事,故事里最后抛出的问题是: 怎么样让道士快速下山? 最快的办法就是顺着坡度最陡峭的地方走下去。那么怎么样找到最陡峭的地方呢? 答案就是: 求导; 上面说了求导的本质就是某点的切线,切线则有斜率,斜率越大的地方也就是越陡峭的点,然后沿着相反的方向进行,这也是梯度下降算法的原理。
3.梯度计算
@注: 求导后得到的结果,在深度学习中,被称为梯度。
只有体会到复杂操作后的过程,才能真实感受到工具的便捷性,下面分别使用两种方式对函数 f ( x ) = 3 x 2 + 2 x + 1 f(x) = 3x^2+2x+1 f(x)=3x2+2x+1进行求导;下图是列举一些常见函数对应的的求导函数公式,方便后续手动计算时,进行参考

更多常见函数的求导函数示例:https://baike.baidu.com/item/导数/579188#3
3.1 手动计算

3.2 自动计算
import torch# 定义函数
def myfunction(x):return 3 * x ** 2 + 2 * x + 1if __name__ == '__main__':# 定义变量,并为其指定需要计算梯度t = torch.tensor(2.0, requires_grad=True)# 计算函数的值result = myfunction(t)# 反向传播,进行梯度计算result.backward()# 打印梯度print('打印梯度:', t.grad)# 打印梯度:tensor(14.)
调用 backward() 方法时,PyTorch会从张量的节点开始,沿着计算图反向传播,计算所有叶子节点相对于该张量的梯度。需要特别注意的是: 在每次调用 backward() 方法之后,PyTorch 会自动清空计算图中的梯度信息。因此,多次调用 backward() 方法会尝试在没有梯度信息的情况下进行反向传播,从而导致运行时错误。
@注: 从上面示例可以看出
Autograd便捷性,如果没有自动求导包Autograd的存在,想想当函数变的复杂时,该怎么去计算某点的导数…
4.梯度累积
在 PyTorch 中,反向传播函数 backward() 只能在一个张量(或者一系列张量)对应的图中被调用一次,因为它会计算当前图中所有叶子节点的梯度。如果多次调用backward(),会发生梯度累积,导致数据不准确;
4.1 错误示例
修改【3.2】代码示例:
def doBackward(var: torch.tensor):# 计算函数的值result = myfunction(var)# 反向传播,进行梯度计算result.backward()print('打印梯度:', var.grad)if __name__ == '__main__':# 定义变量,并为其指定需要计算梯度t = torch.tensor(2.0, requires_grad=True)# 请求多次for i in range(3):doBackward(t)"""
打印梯度: tensor(14.)
打印梯度: tensor(28.)
打印梯度: tensor(42.)
"""
通过上面运行输出,发现自动求导的结果(梯度)进行了累积,为了避免这种问题的出现,通常需要我们在模型训练过程中,手动清除之前计算的梯度。
4.2 清除梯度
通常情况下,在每次进行反向传播之前,需要调用 optimizer.zero_grad() 来清空之前计算的梯度。这样可以避免梯度累积,确保每次反向传播都是基于当前的梯度计算。修改上面示例中的部分代码:
def doBackward(var: torch.tensor):# 计算函数的值result = myfunction(var)# ------- 假设有个优化器:optimizer -------# 在每次迭代之前清零梯度optimizer.zero_grad()# 反向传播,进行梯度计算result.backward()print('计算结果:', var.grad)
4.3 累积影响
为什么梯度不能累积呢?根据资料查询可以发现,梯度累积可能会导致几个问题,尤其是在训练深度神经网络时:
- 减慢收敛速度:梯度累积会导致每个参数的梯度在多次迭代中被累积起来。如果梯度一直累积而不进行更新,可能会导致收敛速度减慢,因为参数更新的幅度变小了。
- 数值不稳定性:梯度累积可能导致数值不稳定性,尤其是在使用较大的学习率时。由于梯度的累积,更新的幅度可能会变得非常大,导致数值溢出或梯度爆炸的问题。
- 内存占用:梯度累积会增加内存的占用,因为需要保存多次迭代中的梯度信息。在内存受限的情况下,梯度累积可能导致内存不足的问题,从而无法完成训练。
- 局部最优解陷阱:梯度累积可能会导致模型陷入局部最优解,而无法跳出。由于梯度的累积,模型可能会固定在一个局部最优解附近,无法继续搜索更好的解决方案。
因此,在训练深度神经网络时,通常建议避免梯度累积,确保每次迭代都使用当前的梯度进行更新,以保证训练的稳定性和收敛速度。
5.局部禁用
- 什么场景用: 当需要在训练过程中固定某些参数或者临时关闭梯度计算时;
- 怎么使用: 可以使用
torch.no_grad()上下文管理器或者在张量上调用.detach()方法来实现局部禁用梯度计算。
下面列举一些情况下,可能需要使用局部禁用梯度计算的具体示例:
5.1 固定模型参数禁用
在迁移学习或者模型微调中,通常会冻结预训练模型的一部分参数,只更新其中的部分参数。为了实现这一目的,可以使用 torch.no_grad() 上下文管理器来禁用梯度计算。
# 示例:冻结预训练模型的一部分参数
with torch.no_grad():for param in model.parameters():param.requires_grad = False# 只对新添加的层的参数进行训练optimizer = torch.optim.SGD(model.fc.parameters(), lr=0.001)
5.2 模型推断时禁用
在模型推断时,不需要计算梯度,因此可以使用 torch.no_grad() 上下文管理器来禁用梯度计算,以提高推断速度和减少内存占用。
# 示例:在前向推断时禁用梯度计算
with torch.no_grad():output = model(input)
5.3 计算某些指标时禁用
在计算模型的性能指标(如准确率、损失值等)时,不需要计算梯度,因此可以使用 torch.no_grad() 上下文管理器来禁用梯度计算,以提高计算效率。
# 示例:在计算指标时禁用梯度计算
with torch.no_grad():loss = criterion(output, target)
通过局部禁用梯度计算,可以灵活地控制梯度计算的范围,提高训练和推断的效率,并且可以避免不必要的梯度计算和内存消耗。
本文由mdnice多平台发布
这篇关于AI学习(5):PyTorch-核心模块(Autograd):自动求导的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




