本文主要是介绍【postgresql】数据表id自增与python sqlachemy结合实例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求:
postgresql实现一个建表语句,表名:student,字段id,name,age,
要求:每次添加一个数据id会自动增加1
在PostgreSQL中,您可以使用SERIAL或BIGSERIAL数据类型来自动生成主键ID。以下是一个创建名为student的表的SQL语句,该表包含id、name和age字段,其中id字段会自动递增:
sql
CREATE TABLE student (id SERIAL PRIMARY KEY,name VARCHAR(255) NOT NULL,age INT NOT NULL
);
在这个建表语句中:
- id字段被设置为SERIAL类型,这意味着每当您向表中插入新行时,id字段的值会自动增加1。
PRIMARY KEY约束表示id字段是表的主键,它在表中是唯一的,并且不能为NULL。 - name字段被设置为VARCHAR(255)类型,这是一个可变长度的字符串,最大长度为255个字符。
- age字段被设置为INT类型,用于存储整数值。
请注意,SERIAL类型是一个整数类型,它会在插入新行时自动增加,但它的值有上限。如果您需要一个更大的数字范围,可以使用BIGSERIAL类型,它与SERIAL类型类似,但可以存储更大的数字。
要向student表中插入数据,您可以使用以下INSERT语句:
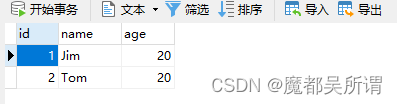
INSERT INTO student (name, age) VALUES ('John Doe', 20);
INSERT INTO student (name, age) VALUES ('Tom', 20);
在这个INSERT语句中,您不需要指定id字段,因为它会自动生成。
ORM操作
# -- coding:utf-8 --
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerBase = declarative_base()class User(Base):__tablename__ = 'student'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(50), nullable=False)age = Column(Integer, nullable=False)# 创建引擎和会话
engine = create_engine('postgresql://admin:admin@192.168.1.1/post')
Session = sessionmaker(bind=engine)
session = Session()# 创建一个新用户
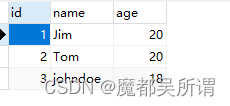
new_user = User(name='johndoe', age=18)
session.add(new_user)
session.commit()数据插入成功:
SERIAL数据类型
如果您的表已经创建,但使用的是INT类型作为主键,并且您想要修改它成为一个自动递增的SERIAL类型,您可以使用ALTER TABLE语句来修改列的数据类型并将其设置为主键。以下是一个例子,展示了如何将现有表users中的id列修改为SERIAL类型:
ALTER TABLE users
MODIFY id SERIAL PRIMARY KEY;
这个命令会改变users表中id列的数据类型为SERIAL,并且将其设置为表的主键。如果id列已经包含数据,这个操作会自动为现有的每个id值分配一个唯一的序列值。
如果您想要保留id列的现有数据并仅为新插入的行生成序列值,您可以使用ALTER TABLE ... ALTER COLUMN ... RESTART命令:
ALTER TABLE users
ALTER COLUMN id RESTART WITH 1;
这个命令会将id序列重新启动,设置下一个插入的行的id值为1。这将不会影响表中已经存在的行。
请注意,这些命令应该在数据库服务器上直接执行,而不是通过应用程序。如果您正在使用SQLAlchemy或其他ORM框架,您可能需要先迁移现有的数据,然后再修改表结构。
案例:
如果之前建表语句中id 用的int类型,怎么修改成SERIAL类型:
如果您的表已经创建,但使用的是INT类型作为主键,并且您想要修改它成为一个自动递增的SERIAL类型,您可以使用ALTER TABLE语句来修改列的数据类型并将其设置为主键。以下是一个例子,展示了如何将现有表users中的id列修改为SERIAL类型:
ALTER TABLE users
MODIFY id SERIAL PRIMARY KEY;
这个命令会改变users表中id列的数据类型为SERIAL,并且将其设置为表的主键。如果id列已经包含数据,这个操作会自动为现有的每个id值分配一个唯一的序列值。
如果您想要保留id列的现有数据并仅为新插入的行生成序列值,您可以使用ALTER TABLE ... ALTER COLUMN ... RESTART命令:
ALTER TABLE users
ALTER COLUMN id RESTART WITH 1;
这个命令会将id序列重新启动,设置下一个插入的行的id值为1。这将不会影响表中已经存在的行。
请注意,这些命令应该在数据库服务器上直接执行,而不是通过应用程序。如果您正在使用SQLAlchemy或其他ORM框架,您可能需要先迁移现有的数据,然后再修改表结构。
SERIAL 与BIGSERIAL的区别
SERIAL和BIGSERIAL是PostgreSQL中用于自动递增整数键的数据类型,它们之间的主要区别在于可以存储的数值范围:
SERIAL:它是INTEGER类型的一个别名,用于自动递增的整数。SERIAL类型的取值范围与INTEGER类型相同,理论上限是2^31 - 1(2147483647),但实际上由于系统限制,可能会有所不同。BIGSERIAL:它是BIGINT类型的一个别名,用于自动递增的更大范围的整数。BIGSERIAL类型的取值范围与BIGINT类型相同,理论上限是2^63 - 1(9223372036854775807)。
在选择SERIAL和BIGSERIAL时,您应该根据您的应用程序所需的ID范围来决定。如果您预计ID值会非常大,或者有可能达到INTEGER类型的上限,那么应该使用BIGSERIAL。如果您确信ID值会在INTEGER类型的范围内,那么SERIAL将是更高效的选择,因为它在存储和处理上消耗的资源更少。
例如,如果您正在构建一个可能会有数百万或更多用户的大规模应用程序,并且用户ID需要有很大的范围,那么使用BIGSERIAL会是更合适的选择。如果您构建的是一个小型应用程序,用户数量有限,那么SERIAL可能就足够了。
在创建表时,您可以这样定义这两个类型:
CREATE TABLE users (id SERIAL PRIMARY KEY,-- ...
);
CREATE TABLE large_users (id BIGSERIAL PRIMARY KEY,-- ...
);
在SQLAlchemy中,您可以这样指定这些类型:
from sqlalchemy import Column, Integer, BigInteger
class SmallUser(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True)# ...
class LargeUser(Base):__tablename__ = 'large_users'id = Column(BigInteger, primary_key=True)# ...
在这个例子中,SmallUser类使用Integer类型,而LargeUser类使用BigInteger类型,后者可以存储更大的数值。在SQLAlchemy中,BigInteger类型对应于PostgreSQL中的BIGINT类型。
这篇关于【postgresql】数据表id自增与python sqlachemy结合实例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



