本文主要是介绍自定义神经网络一之Tensor和神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- Tensor
- 神经网络
- 深度神经网络DNN
- 卷积神经网络CNN
- 卷积神经网络有2大特点
- 循环神经网络RNN
- 残差网络ResNet
- Transformer
- 自我注意力机制
- 并行效率
- 总结
前言
神经网络是AI界的一个基础概念,当下火热的神经网络例如RNN循环神经网络或者CNN卷积神经网络,都是从基础的神经网络发展而来的。
本系列博客的主要目标是自定义一个神经网络,并把训练结果保存到模型文件。想要完成这个目标,了解基础的概念必不可少。
本章主要是介绍Tensor和神经网络基础概念,以及常见的神经网络特点和应用场景等。
Tensor
参考:张量(Tensor):神经网络的基本数据结构
具体的内容可以参考知乎大佬的文章,我们在自定义神经网络的时候,一般用numpy的ndarray类型即可,也就是自己定义多维数组来作为"Tensor"。 相比于Pytorch等训练框架的Tensor来说,ndarray只能在CPU侧进行运算,且没有自动微分等高级特性,不过也足够用了。
Tensor张量是可以说是神经网络运算的基石,一方面是可以代表多维的数据,例如我们常用的二维数组,三维数组,另一方面当下火热的训练框架pytorch和tensorflow都重新定义了Tensor对象,使Tensor对象可以利用GPU的并行计算能力,以及拥有自动微分等特性。
神经网络
参考:什么是神经网络? - 知乎
神经网络模型–数学建模_建立基于神经网络的数学模型-CSDN博客
现在网络上关于神经网络的文章已经很多了,大家根据参考链接学习即可。
简单来说,神经网络就是模拟人的大脑神经进行信息处理的数学模型。
单层神经网络: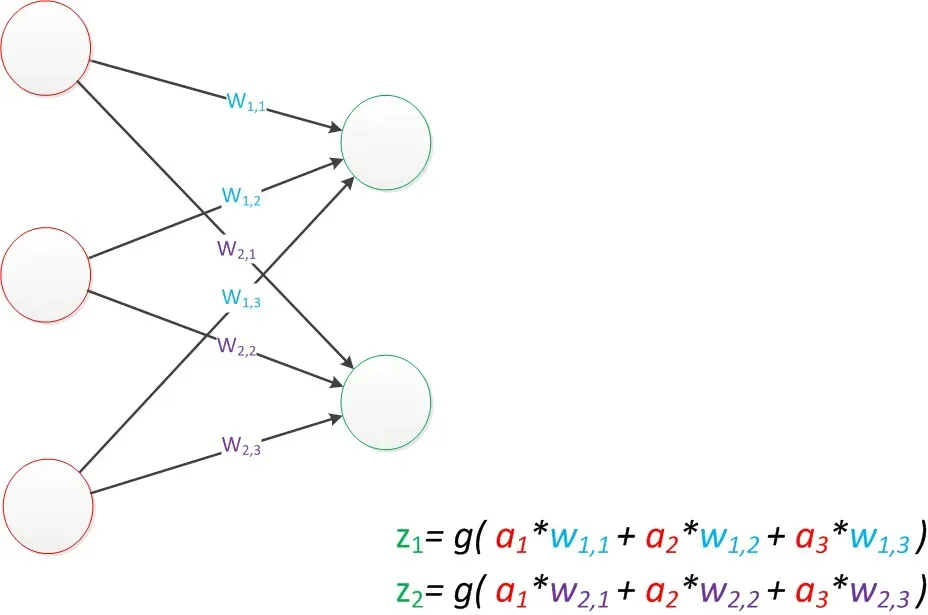
多层神经网络: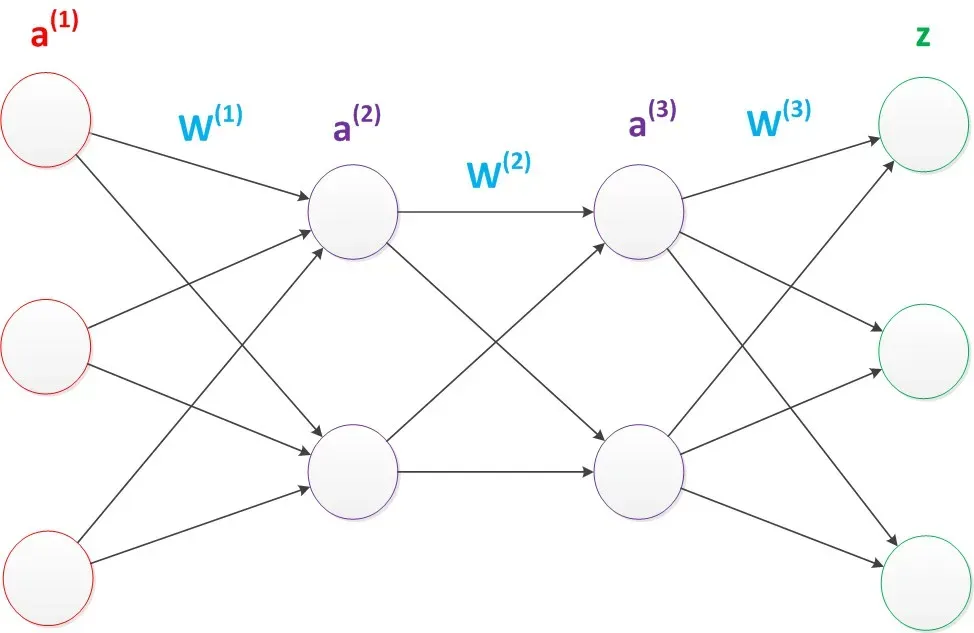
深度神经网络DNN
2006年,Hinton利用预训练方法缓解了局部最优解问题,将隐含层推动到了7层(参考论文:Hinton G E, Salakhutdinov R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786):504-507.),神经网络真正意义上有了“深度”,由此揭开了深度学习的热潮。这里的“深度”并没有固定的定义——在语音识别中4层网络就能够被认为是“较深的”,而在图像识别中20层以上的网络屡见不鲜。为了克服梯度消失,ReLU、maxout等传输函数代替了 sigmoid,形成了如今 DNN 的基本形式。单从结构上来说,全连接的DNN和上图的多层感知机是没有任何区别的。值得一提的是,今年出现的高速公路网络(highway network)和深度残差学习(deep residual learning)进一步避免了梯度弥散问题,网络层数达到了前所未有的一百多层(深度残差学习:152层)
卷积神经网络CNN
参考:
CNN笔记:通俗理解卷积神经网络_cnn卷积神经网络-CSDN博客
图解CNN:通过100张图一步步理解CNN-CSDN博客
卷积神经网络和深度神经网络的区别是什么? - 知乎
具体的看链接吧,讲的很清楚。
简单来说,CNN主要用于图像识别领域,主要解决特征提取的问题。通过卷积和池化来减少参数量。
卷积神经网络有2大特点
- 能够有效的将大数据量的图片降维成小数据量
- 能够有效的保留图片特征,符合图片处理的原则
循环神经网络RNN
参考:
如何理解RNN(循环神经网络),能举一些简单的例子吗? - 知乎
(新手向)能否简单易懂的介绍一下RNN(循环神经网络)? - 知乎
https://dennybritz.com/posts/wildml/recurrent-neural-networks-tutorial-part-1/
简单来说,RNN被称为循环,因为它对序列列的每个元素执行相同的任务,并且基于先前的计算进行输出。RNN的另一个优点是它具有“记忆”,它可以收集到目前为止已经计算的信息。RNN常用于NLP领域。
RNN 从始至终意图解决的都是“记忆”问题,而非 CNN 所解决的“提取”问题。两者并不冲突,甚至还可以适度融合,即组合形成 CNN+RNN 融合模型(Hybrid Model)。
残差网络ResNet
参考:
对ResNet本质的一些思考
ResNet原理与性能分析:解空间与优化视角
ResNet的基础:残差块的原理
在深度学习中,为了增强模型的学习能力,网络层会变得越来越深,但是随着深度的增加,也带来了比较一些问题,主要包括:
- 模型复杂度上升,网络训练困难;
- 梯度消失/梯度爆炸
- 网络退化,也就是说模型的学习能力达到了饱和,增加网络层数并不能提升精度了。
为了解决网络退化问题,何凯明大佬提出了深度残差网络来解决以上问题。 具体的可以参考链接进行学习。
Transformer
网络上关于Transformer的文章也很多,给大家推荐几篇学习的文章。
参考:
ChatGPT牛逼,是因为Transformer模型牛逼…-CSDN博客
https://jalammar.github.io/illustrated-transformer/
(六十)通俗易懂理解——Transformer原理解析
学习实战的库: https://github.com/google/trax
以下是Transformer的简介
2017年12月-Tranformer颠覆性的Tranformer架构出世了!
Googl机器翻译团队在年底的顶级会议NIPS上发表了里程碑式的论文《Attention is all you need》,提出只使用自注意力(Self Attention)机制来训练自然语言模型,并给这种架构起了个霸气的名字:Transformer。
所谓"自我注意力"机制,简单说就是只关心输入信息之间的关系,而不再关注输入和对应输出的关系。和之前大模型训练需要匹配的输入输出标注数据相比,这是一个革命性的变化。
**Transformer彻底抛弃了传统的CNN和RNN等神经网络结构。**在这篇论文发布之前,主流AI模型都基于CNN卷积神经网络和RNN循环神经网络(recurrent neural network); 而之后,便是Transformer一统天下。
它具有两点无敌的优势:
自我注意力机制
让模型训练只需使用未经标注的原始数据,而无需再进行昂贵的的人工标注(标注输入和对应输出)。
基于自我注意力机制的Transformer模型的出现是革命性的, 最最重要的一点, 它能实现自我监督学习. 所谓自我监督, 就是不需要标注的样本, 使用标准的语料或者图像, 模型就能学习了.
在Tranformer出现之前, 我们要训练一个深度学习模型, 必须使用大规模的标记好的数据集合来训练神经网络. 对数据进行标注只能人工进行, 金钱和时间成本都相当高.
并行效率
并行效率是之前的AI模型结构被一直诟病的地方。抛弃了传统CNN/RNN架构后,基于Transformer架构的大模型训练可以实现高度并行化,这大大提高了模型训练的效率;更不用说, Attention注意力机制只关注部分信息, 参数较少, 容易训练.
总结
以上简单介绍了一下神经网络的基础概念,以及目前业界常用的几种神经网络和适用的场景。详细介绍神经网络并非本博客的主要目标,本博客意在让有兴趣的同学了解一下,然后通过参考链接去进一步的学习。
接下来的几篇博客会总结一下模型的训练和推理,以及引申出的梯度的概念以及损失函数,激活函数的概念。最终目标是实现一个自定义神经网络,有体感的去训练和推理模型,达到解决实际问题的目标。
end
这篇关于自定义神经网络一之Tensor和神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




