本文主要是介绍半天搞定MySQL(全)三(MySQL数据库教程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
半天搞定MySQL(全)
半天搞定MySQL(全)一
半天搞定MySQL(全)二
半天搞定MySQL(全)四
半天搞定MySQL(全)五
半天搞定MySQL(全)六
半天搞定MySQL(全)七(终章)
博主用的是8.0版本的MySQL,储存引擎是InnoDB,关于InnoDB这里不详细解释,需要的话推荐了解这篇博文(或者自行百度)https://www.jianshu.com/p/519fd7747137
- 目录
- 多表操作
- 正则表达式
- 事务
5. 多表操作
在前面博主有试着进行过多表查询,但是正式的多表操作现在开始吧!
JOIN
inner join(内连接,或等值连接):获取两个表中字段匹配关系的记录。
left join(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
right join(右连接): 与 left join相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
inner join
inner join也可以省略inner使用join,效果一样
mysql> select city_journey.city_name,city_journey.times,city_spots.city_score from city_spots inner join city_journey on city_journey.city_name=city_spots.city_name;
+-----------+-------+------------+
| city_name | times | city_score |
+-----------+-------+------------+
| 海南 | 2 | 78 |
| 香港 | 1 | 76 |
| 香港 | 1 | 76 |
| Janpan | 1 | 85 |
| America | 1 | 82 |
| Iceland | 1 | 88 |
+-----------+-------+------------+
6 rows in set (0.00 sec)
上述语句等价于以下语句:
mysql> select city_journey.city_name,city_journey.times,city_spots.city_score from city_spots,city_journey where city_journey.city_name=city_spots.city_name;
+-----------+-------+------------+
| city_name | times | city_score |
+-----------+-------+------------+
| 海南 | 2 | 78 |
| 香港 | 1 | 76 |
| 香港 | 1 | 76 |
| Janpan | 1 | 85 |
| America | 1 | 82 |
| Iceland | 1 | 88 |
+-----------+-------+------------+
6 rows in set (0.00 sec)
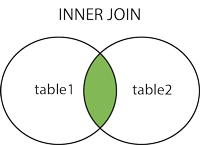
图片来源:https://www.runoob.com/mysql/mysql-join.html
left join
mysql> select city_journey.city_name,city_journey.times,city_spots.city_score from city_spots left join city_journey on city_journey.city_name=city_spots.city_name;
+-----------+-------+------------+
| city_name | times | city_score |
+-----------+-------+------------+
| America | 1 | 82 |
| Iceland | 1 | 88 |
| Janpan | 1 | 85 |
| NULL | NULL | 80 |
| NULL | NULL | 86 |
| NULL | NULL | 93 |
| NULL | NULL | 90 |
| 海南 | 2 | 78 |
| 香港 | 1 | 76 |
| 香港 | 1 | 76 |
+-----------+-------+------------+
10 rows in set (0.00 sec)
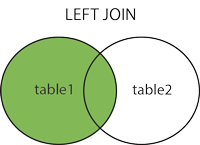
图片来源:https://www.runoob.com/mysql/mysql-join.html
right join
mysql> select city_journey.city_name,city_journey.times,city_spots.city_score from city_spots right join city_journey on city_journey.city_name=city_spots.city_name;
+-----------+-------+------------+
| city_name | times | city_score |
+-----------+-------+------------+
| 海南 | 2 | 78 |
| 夏威夷 | 1 | NULL |
| 香港 | 1 | 76 |
| 香港 | 1 | 76 |
| Janpan | 1 | 85 |
| America | 1 | 82 |
| Iceland | 1 | 88 |
+-----------+-------+------------+
7 rows in set (0.00 sec)
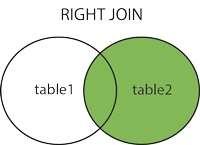
图片来源:https://www.runoob.com/mysql/mysql-join.html
NULL值处理
IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。 <=>: 比较操作符(不同于 = ),当比较的两个值相等或者都为
NULL 时返回 true。
null
mysql> create table city_play(-> city_name varchar(20) not null,-> city_thing varchar(50) not null,-> cost int,-> journey_ID varchar(20),-> thing_score int,-> play_ID int auto_increment primary key);
Query OK, 0 rows affected (0.04 sec)
is null 和 is not null
mysql> select * from city_play where cost is null;
+-----------+------------+------+------------+-------------+---------+
| city_name | city_thing | cost | journey_ID | thing_score | play_ID |
+-----------+------------+------+------------+-------------+---------+
| 夏威夷 | 水 | NULL | 2 | 88 | 2 |
| 香港 | 潜水 | NULL | 10 | 95 | 10 |
| Janpan | woman | NULL | 11 | 90 | 11 |
+-----------+------------+------+------------+-------------+---------+
3 rows in set (0.00 sec)
6. 正则表达式
在讲到like时,博主提到了模糊匹配:a,a%,%a,%a,a%,%a%…
但是MySQL支持的正则表达式不仅仅这些。
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式 |
| […] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^…] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,‘z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
^ 匹配以city_journey中以’Ja’开头的所有数据
mysql> select * from city_journey where city_name regexp '^Ja';
+------------+-----------+-------+------------+
| journey_ID | city_name | times | data |
+------------+-----------+-------+------------+
| 11 | Janpan | 1 | 2021-06-04 |
+------------+-----------+-------+------------+
1 row in set (0.02 sec)
$ 匹配以city_journey中以’n’结尾的所有数据
mysql> select * from city_journey where city_name regexp 'n$';
+------------+-----------+-------+------------+
| journey_ID | city_name | times | data |
+------------+-----------+-------+------------+
| 11 | Janpan | 1 | 2021-06-04 |
+------------+-----------+-------+------------+
1 row in set (0.00 sec)
$ 匹配以city_journey中包含’ri’字符串的所有数据
mysql> select * from city_journey where city_name regexp 'ri';
+------------+-----------+-------+------------+
| journey_ID | city_name | times | data |
+------------+-----------+-------+------------+
| 12 | America | 1 | 2022-06-06 |
+------------+-----------+-------+------------+
1 row in set (0.00 sec)
∧ ∧ ∧[北上广]|d$ 匹配以[北上广]中任意字符开头或以’d’字符结尾的所有数据
mysql> select * from city_spots where city_name regexp '^[北上广]|d$';
+-----------+--------------------+------------+----------+----------+-----------+
| city_name | place_of_interest' | city_score | cost_rmb | time_way | time_stay |
+-----------+--------------------+------------+----------+----------+-----------+
| Iceland | Ice | 88 | 19000 | 1.5 | 5 |
| 上海 | 购物 | 80 | 13000 | 1 | 2.5 |
| 北京 | 长城 | 93 | 15000 | 1 | 3 |
+-----------+--------------------+------------+----------+----------+-----------+
3 rows in set (0.00 sec)
∗ * ∗ 匹配前一个字符0次以上
mysql> select * from city_spots where city_name regexp 's*';
+-----------+--------------------+------------+----------+----------+-----------+
| city_name | place_of_interest' | city_score | cost_rmb | time_way | time_stay |
+-----------+--------------------+------------+----------+----------+-----------+
| America | 未知 | 82 | 20000 | 1.5 | 4 |
| Iceland | Ice | 88 | 19000 | 1.5 | 5 |
| Janpan | 未知 | 85 | 15000 | 1 | 3 |
| 上海 | 购物 | 80 | 13000 | 1 | 2.5 |
| 东北 | 雪 | 86 | 10000 | 1.5 | 5 |
| 北京 | 长城 | 93 | 15000 | 1 | 3 |
| 新疆 | 水果 | 90 | 12000 | 1.5 | 5 |
| 海南 | 沙滩 | 78 | 9000 | 1 | 4 |
| 香港 | 未知 | 76 | 8000 | 1 | 3 |
+-----------+--------------------+------------+----------+----------+-----------+
9 rows in set (0.00 sec)mysql> select * from city_spots where city_name regexp 'as*';
+-----------+--------------------+------------+----------+----------+-----------+
| city_name | place_of_interest' | city_score | cost_rmb | time_way | time_stay |
+-----------+--------------------+------------+----------+----------+-----------+
| America | 未知 | 82 | 20000 | 1.5 | 4 |
| Iceland | Ice | 88 | 19000 | 1.5 | 5 |
| Janpan | 未知 | 85 | 15000 | 1 | 3 |
+-----------+--------------------+------------+----------+----------+-----------+
3 rows in set (0.00 sec)
事务
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。 事务处理可以用来维护数据库的完整性,保证成批的 SQL
语句要么全部执行,要么全部不执行。 事务用来管理 insert,update,delete 语句
事务四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
事务控制语句:
BEGIN 或 START TRANSACTION 显式地开启一个事务;
COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK 也可以使用 ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
ROLLBACK TO identifier 把事务回滚到标记点;
SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,时会被回滚(Rollback)到事务开始前的状态。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
BEGIN 开始一个事务
ROLLBACK 事务回滚
COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
完整事务
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into city_spots-> values('Italy','food',79,20000,1,4);
Query OK, 1 row affected (0.01 sec)
mysql> insert into city_spots-> values('西安','兵马俑',83,5500,1,3);
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
回滚
mysql> begin;
Query OK, 0 rows affected (0.00 sec)-> values('Italian','food',79,20000,1,4);
Query OK, 1 row affected (0.01 sec)mysql> rollback;
Query OK, 0 rows affected (0.01 sec)
未完待续。。。
半天搞定MySQL(全)一
半天搞定MySQL(全)二
半天搞定MySQL(全)四
半天搞定MySQL(全)五
半天搞定MySQL(全)六
半天搞定MySQL(全)七(终章)
这篇关于半天搞定MySQL(全)三(MySQL数据库教程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








