本文主要是介绍推荐系统 - Google多目标学习MMOE(附tf2.0实现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文收录在推荐系统专栏,专栏系统化的整理推荐系统相关的算法和框架,并记录了相关实践经验,所有代码都已整理至推荐算法实战集合(hub-recsys)。
1.背景
何谓多任务,即在一个模型中考虑多个目标。在推荐系统中,往往需要同时优化多个业务目标,承担起更多的业务收益。如电商场景:希望能够同时优化点击率和转换率,使得平台具备更加的目标;信息流场景,希望提高用户点击率的基础上提高用户关注,点赞,评论等行为,营造更好的社区氛围从而提高留存。当前多任务的迭代进程是 stacking ——> shared bottom layer(hard) ——> shared bottom layer(soft)
2. MMoE简介
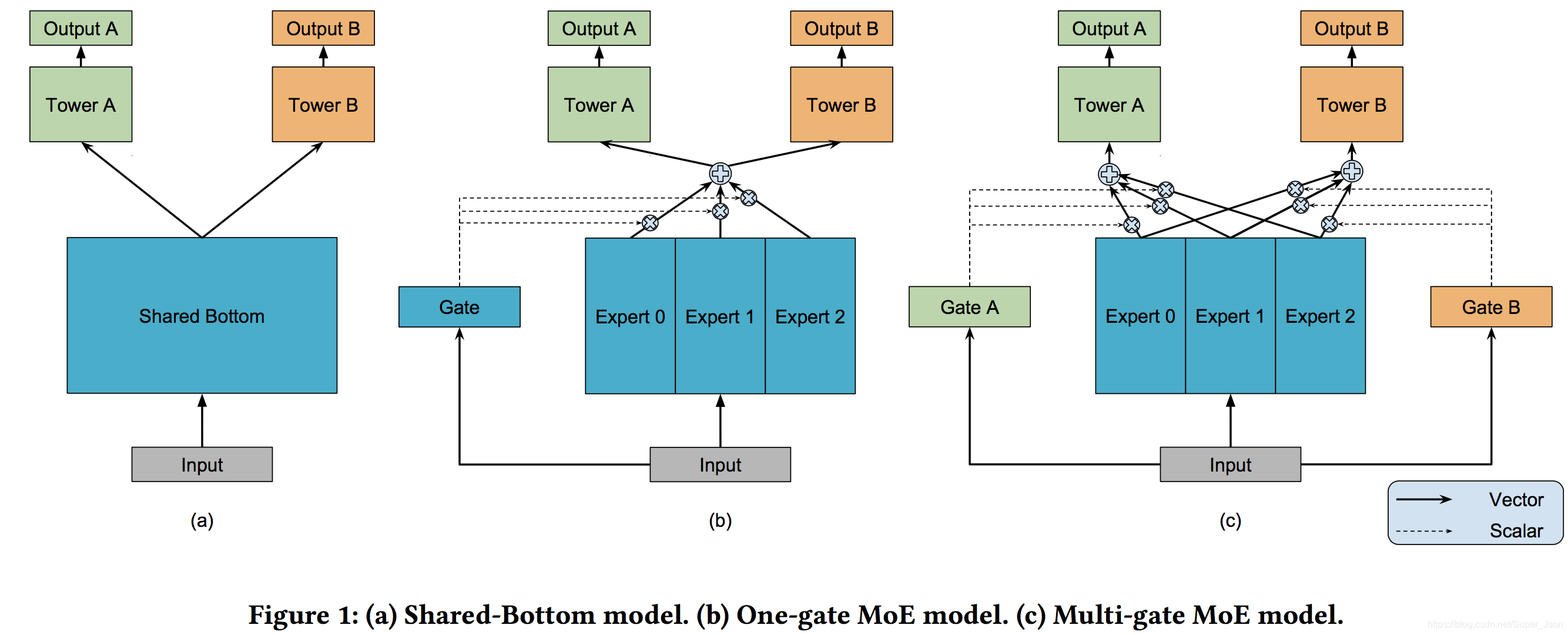
MMoE 是Google的研究人员提出的一种NN模型中多目标优化的模型结构。MMoE为每一个模型目标设置一个gate,所有的目标共享多个expert,每个expert通常是数层规模比较小的全连接层。gate用来选择每个expert的信号占比。每个expert都有其擅长的预测方向,最后共同作用于上面的多个目标。
MMoE 具备以下两点主要优势:
- 相比较简单的stacking多模型融合,MMoE引入了shared bottom layer来加强参数共享。多个目标的模型可以联合训练,减小模型的参数规模,防止模型过拟合。从性能方面的考虑,可以节省训练和预测的计算量。
- 共享参数一定程度上限制了不同目标的特异性,预测的目标之间的相关性比较高,模型才会具备好结果,MMoE引入门结构作为不同任务之间学习的注意力引入。
3. MMoE原理
3.1 Mixture-of-Experts
在正式介绍MMoE之前,我们先看简单的share bottom,x为模型的输入,如上图a所示,shared-bottom网络(表示为函数f)位于底部,多个任务共用这一层。K个子任务分别对应一个tower Network(表示为![]() ,如图tower A),每个子任务的输出为
,如图tower A),每个子任务的输出为![]()
MoE在此基础上引入了one-gate和多个Expert网络,其核心思想是将shared-bottom网络中的函数f替换成MoE层,如下所示:

其中fi(x),i=1,2,....n 是n个expert network(expert network可认为是一个神经网络),具体来说g产生n个experts上的概率分布,g是组合experts结果的gating network,最终的输出是所有experts的带权加和。显然,MoE可看做基于多个独立模型的集成方法。
3.2 Multi-gate Mixture-of-Experts
文章提出的模型(简称MMoE)目的就是相对于shared-bottom结构不明显增加模型参数的要求下捕捉任务的不同,形式化表达为:
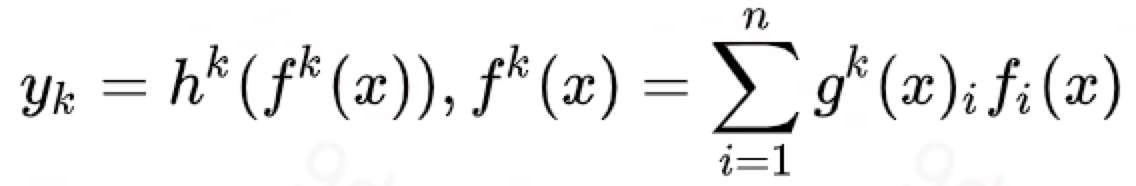
![]()
其中gk输入就是input feature,输出是所有experts上的权重。
一方面,因为gating networks通常是轻量级的,而且expert networks是所有任务共用,所以相对于论文中提到的一些baseline方法在计算量和参数量上具有优势。另一方面,相对于所有任务公共一个门控网络(One-gate MoE model,如上图b),这里MMoE(上图c)中每个任务使用单独的gating networks。每个任务的gating networks通过最终输出权重不同实现对experts的选择性利用。不同任务的gating networks可以学习到不同的组合experts的模式,因此模型考虑到了捕捉到任务的相关性和区别。
4. 总结
- 可以将每一个gate认为是weighted sum pooling操作。如果我们选择将gate换成max操作。x为输入,g(x)中分量最大值对应的expert被唯一选中,向上传递信号。如果g(x)与input无关,则模型退化成多个独立的NN模型stacking,这样就便于我们更方便理解模型的进化关系。
- 此处MMoE是将MoE作为一个基本的组成单元,横向堆叠。也可以进行纵向堆叠,将上个MMoE的输出作为下一个输入。
- 如果任务相关度非常高,则OMoE和MMoE的效果近似,但是如果任务相关度很低,则OMoE的效果相对于MMoE明显下降,说明MMoE中的multi-gate的结构对于任务差异带来的冲突有一定的缓解作用。
- gate的softmax值可以反映不同expert和各个目标之间的关系,可以看到不同的expert确实在不同的任务中的重要性不同。但是这种expert和task的对应关系是训练获得的,如何加入expert和task之间存在的先验知识(强相关)。任务和expert权值参数初始化预引入,或者直接修改softmax函数,让占比大的更大。
- 是否需要对expert进行拆分,如FFM将特征分成Field;或者按照结构分expert,或者task specific expert + common expert
5. 代码实现
利用tensorflow实现了MMoElayer,整体的代码可以参考https://github.com/hxyue/hub-recsys/blob/master/Deep/MMOE/mmoe.py
import tensorflow as tf
from tensorflow import tensordot, expand_dims
from tensorflow.keras import layers, Model, initializers, regularizers, activations, constraints, Inputfrom tensorflow.keras.backend import expand_dims,repeat_elements,sumclass MMoE(layers.Layer):"""Multi-gate Mixture-of-Experts model."""def __init__(self,units,num_experts,num_tasks,use_expert_bias=True,use_gate_bias=True,expert_activation='relu',gate_activation='softmax',expert_bias_initializer='zeros',gate_bias_initializer='zeros',expert_bias_regularizer=None,gate_bias_regularizer=None,expert_bias_constraint=None,gate_bias_constraint=None,expert_kernel_initializer='VarianceScaling',gate_kernel_initializer='VarianceScaling',expert_kernel_regularizer=None,gate_kernel_regularizer=None,expert_kernel_constraint=None,gate_kernel_constraint=None,activity_regularizer=None,**kwargs):"""Method for instantiating MMoE layer.:param units: Number of hidden units:param num_experts: Number of experts:param num_tasks: Number of tasks:param use_expert_bias: Boolean to indicate the usage of bias in the expert weights:param use_gate_bias: Boolean to indicate the usage of bias in the gate weights:param expert_activation: Activation function of the expert weights:param gate_activation: Activation function of the gate weights:param expert_bias_initializer: Initializer for the expert bias:param gate_bias_initializer: Initializer for the gate bias:param expert_bias_regularizer: Regularizer for the expert bias:param gate_bias_regularizer: Regularizer for the gate bias:param expert_bias_constraint: Constraint for the expert bias:param gate_bias_constraint: Constraint for the gate bias:param expert_kernel_initializer: Initializer for the expert weights:param gate_kernel_initializer: Initializer for the gate weights:param expert_kernel_regularizer: Regularizer for the expert weights:param gate_kernel_regularizer: Regularizer for the gate weights:param expert_kernel_constraint: Constraint for the expert weights:param gate_kernel_constraint: Constraint for the gate weights:param activity_regularizer: Regularizer for the activity:param kwargs: Additional keyword arguments for the Layer class"""super(MMoE, self).__init__(**kwargs)# Hidden nodes parameterself.units = unitsself.num_experts = num_expertsself.num_tasks = num_tasks# Weight parameterself.expert_kernels = Noneself.gate_kernels = Noneself.expert_kernel_initializer = initializers.get(expert_kernel_initializer)self.gate_kernel_initializer = initializers.get(gate_kernel_initializer)self.expert_kernel_regularizer = regularizers.get(expert_kernel_regularizer)self.gate_kernel_regularizer = regularizers.get(gate_kernel_regularizer)self.expert_kernel_constraint = constraints.get(expert_kernel_constraint)self.gate_kernel_constraint = constraints.get(gate_kernel_constraint)# Activation parameter#self.expert_activation = activations.get(expert_activation)self.expert_activation = expert_activationself.gate_activation = gate_activation# Bias parameterself.expert_bias = Noneself.gate_bias = Noneself.use_expert_bias = use_expert_biasself.use_gate_bias = use_gate_biasself.expert_bias_initializer = initializers.get(expert_bias_initializer)self.gate_bias_initializer = initializers.get(gate_bias_initializer)self.expert_bias_regularizer = regularizers.get(expert_bias_regularizer)self.gate_bias_regularizer = regularizers.get(gate_bias_regularizer)self.expert_bias_constraint = constraints.get(expert_bias_constraint)self.gate_bias_constraint = constraints.get(gate_bias_constraint)# Activity parameterself.activity_regularizer = regularizers.get(activity_regularizer)self.expert_layers = []self.gate_layers = []for i in range(self.num_experts):self.expert_layers.append(layers.Dense(self.units, activation=self.expert_activation,use_bias=self.use_expert_bias,kernel_initializer=self.expert_kernel_initializer,bias_initializer=self.expert_bias_initializer,kernel_regularizer=self.expert_kernel_regularizer,bias_regularizer=self.expert_bias_regularizer,activity_regularizer=None,kernel_constraint=self.expert_kernel_constraint,bias_constraint=self.expert_bias_constraint))for i in range(self.num_tasks):self.gate_layers.append(layers.Dense(self.num_experts, activation=self.gate_activation,use_bias=self.use_gate_bias,kernel_initializer=self.gate_kernel_initializer,bias_initializer=self.gate_bias_initializer,kernel_regularizer=self.gate_kernel_regularizer,bias_regularizer=self.gate_bias_regularizer, activity_regularizer=None,kernel_constraint=self.gate_kernel_constraint,bias_constraint=self.gate_bias_constraint))def call(self, inputs):"""Method for the forward function of the layer.:param inputs: Input tensor:param kwargs: Additional keyword arguments for the base method:return: A tensor"""#assert input_shape is not None and len(input_shape) >= 2expert_outputs, gate_outputs, final_outputs = [], [], []for expert_layer in self.expert_layers:expert_output = expand_dims(expert_layer(inputs), axis=2)expert_outputs.append(expert_output)expert_outputs = tf.concat(expert_outputs,2)for gate_layer in self.gate_layers:gate_outputs.append(gate_layer(inputs))for gate_output in gate_outputs:expanded_gate_output = expand_dims(gate_output, axis=1)weighted_expert_output = expert_outputs * repeat_elements(expanded_gate_output, self.units, axis=1)final_outputs.append(sum(weighted_expert_output, axis=2))# 返回的矩阵维度 num_tasks * batch * unitsreturn final_outputs
这篇关于推荐系统 - Google多目标学习MMOE(附tf2.0实现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






