本文主要是介绍线程池(ThreadPoolExecutor,as_completed)和scrapy框架初步构建——学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用法1:map函数
with ThreadPoolExecutor() as pool: results = pool.map(craw,utls)for result in results:print(result)1.Scrapy框架:
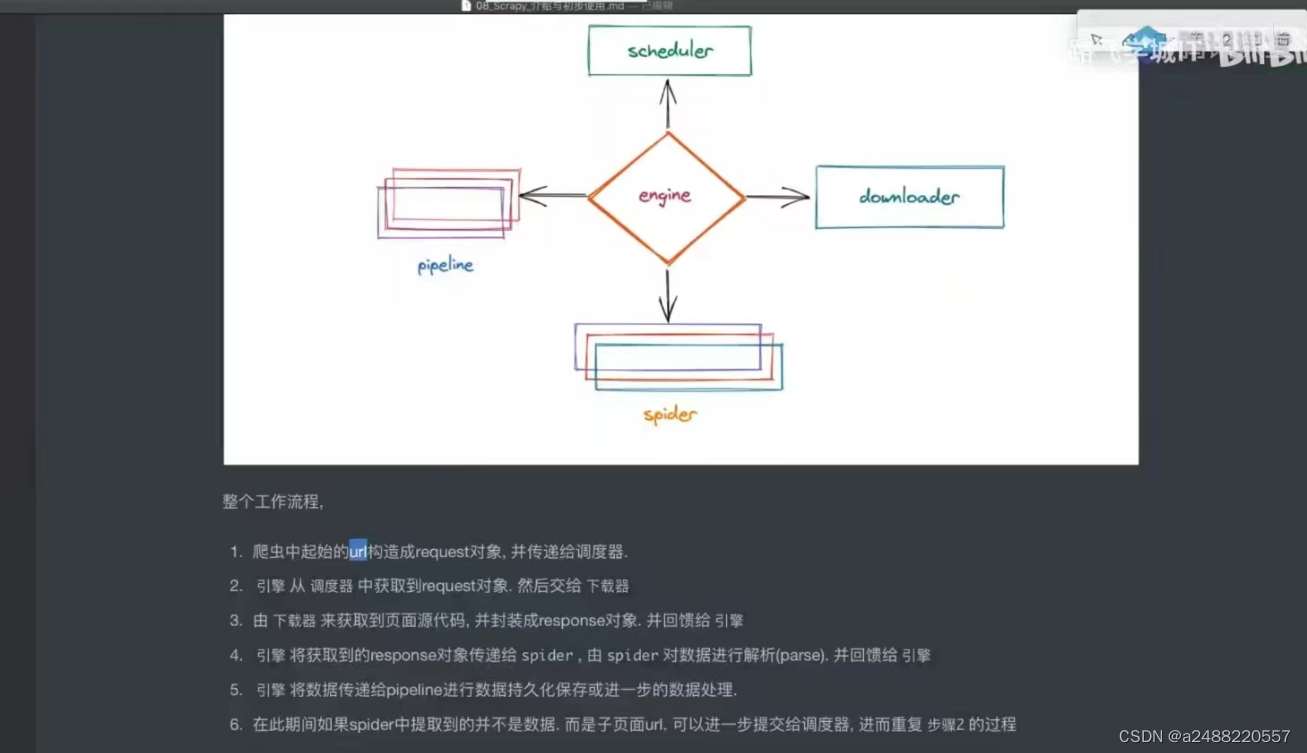
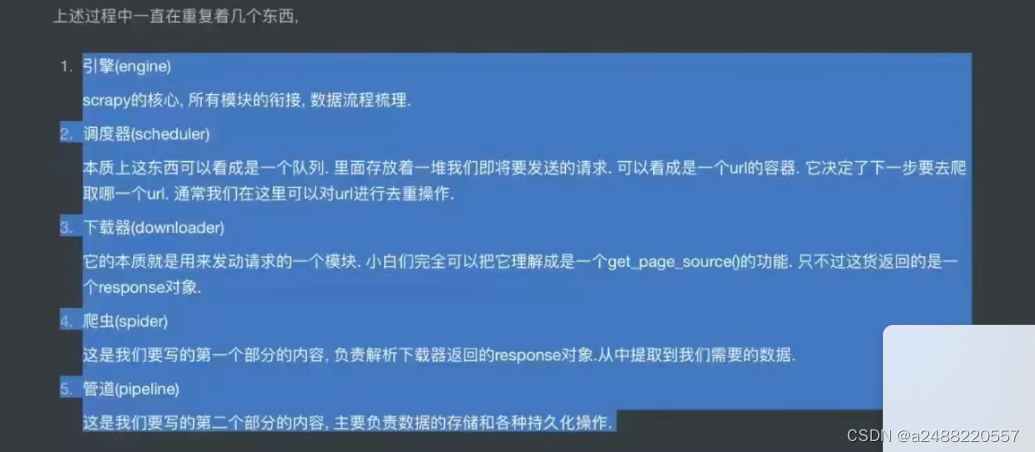
五大结构:引擎,下载器,爬虫,调度器,管道,爬虫
其中引擎,下载器,调度器。不用我们写。剩下的要我们写。
代码部分的了解:这个是自己创建一个爬虫(用scrapy)叫“xiao”
import scrapyclass XiaoSpider(scrapy.Spider):name = "xiao"allowed_domains = ["4399.com"]start_urls = ["https://4399.com/flash/"]def parse(self, response):#print(response.text)#获得游戏名# txt = response.xpath("//ul[@class = 'n-game cf']/li/ a/b/text()")# #提取信息内容# txt = txt.extract()# print(txt)#分块提取li_list = response.xpath("//ul[@class = 'n-game cf']/li")for list in li_list:#name = list.xpath("./a/b/text()").extract()#返回的一个列表,拿到字符串要加[0]name = list.xpath("./a/b/text()").extract_first()#拿到第一个,如果没有返回Noneleibie = list.xpath("./em/a/text()").extract_first()#拿到第一个,如果没有返回Noneprint(name,leibie)

这个scrapy是拿终端跑的。
步骤:
1.

2.
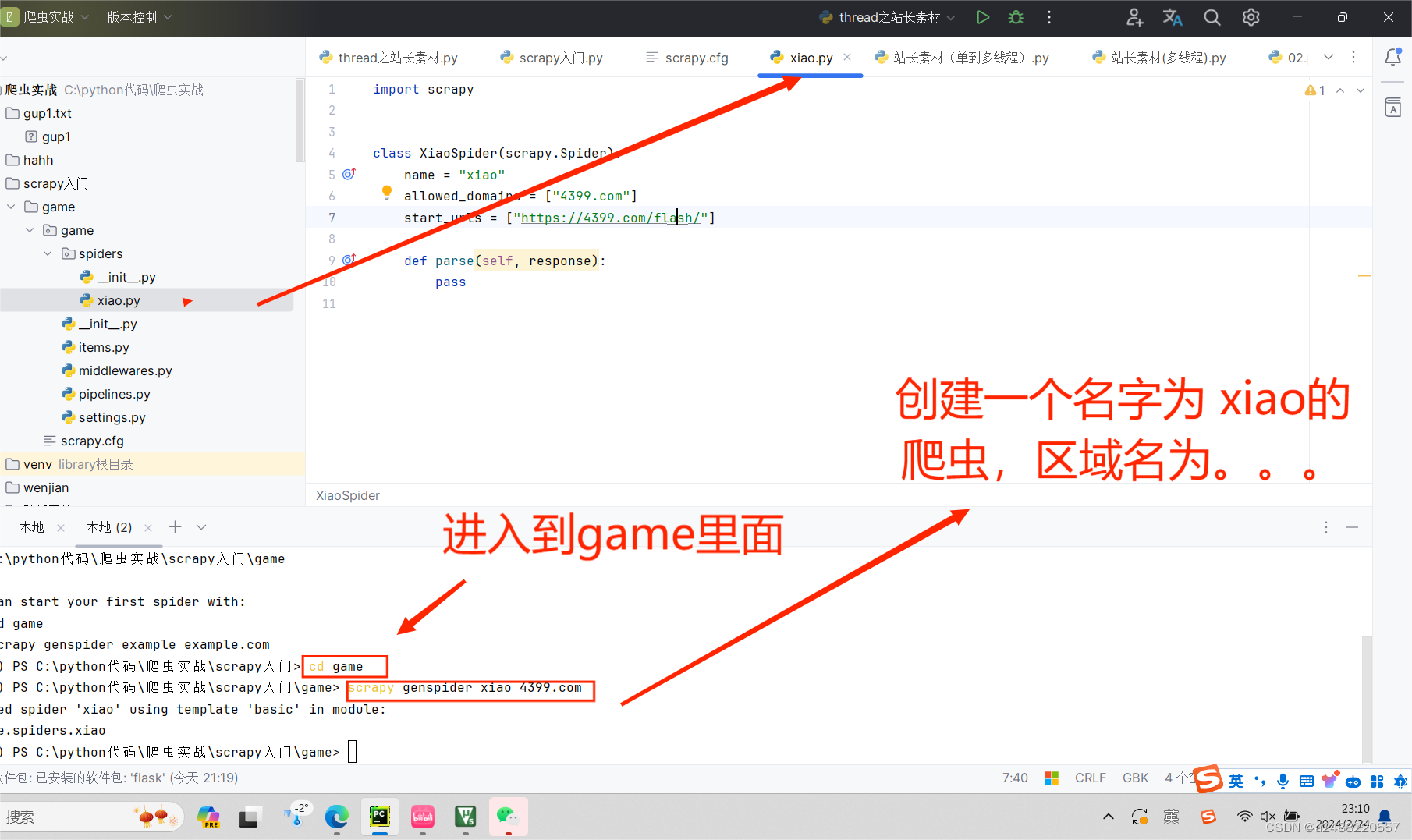 3.
3.
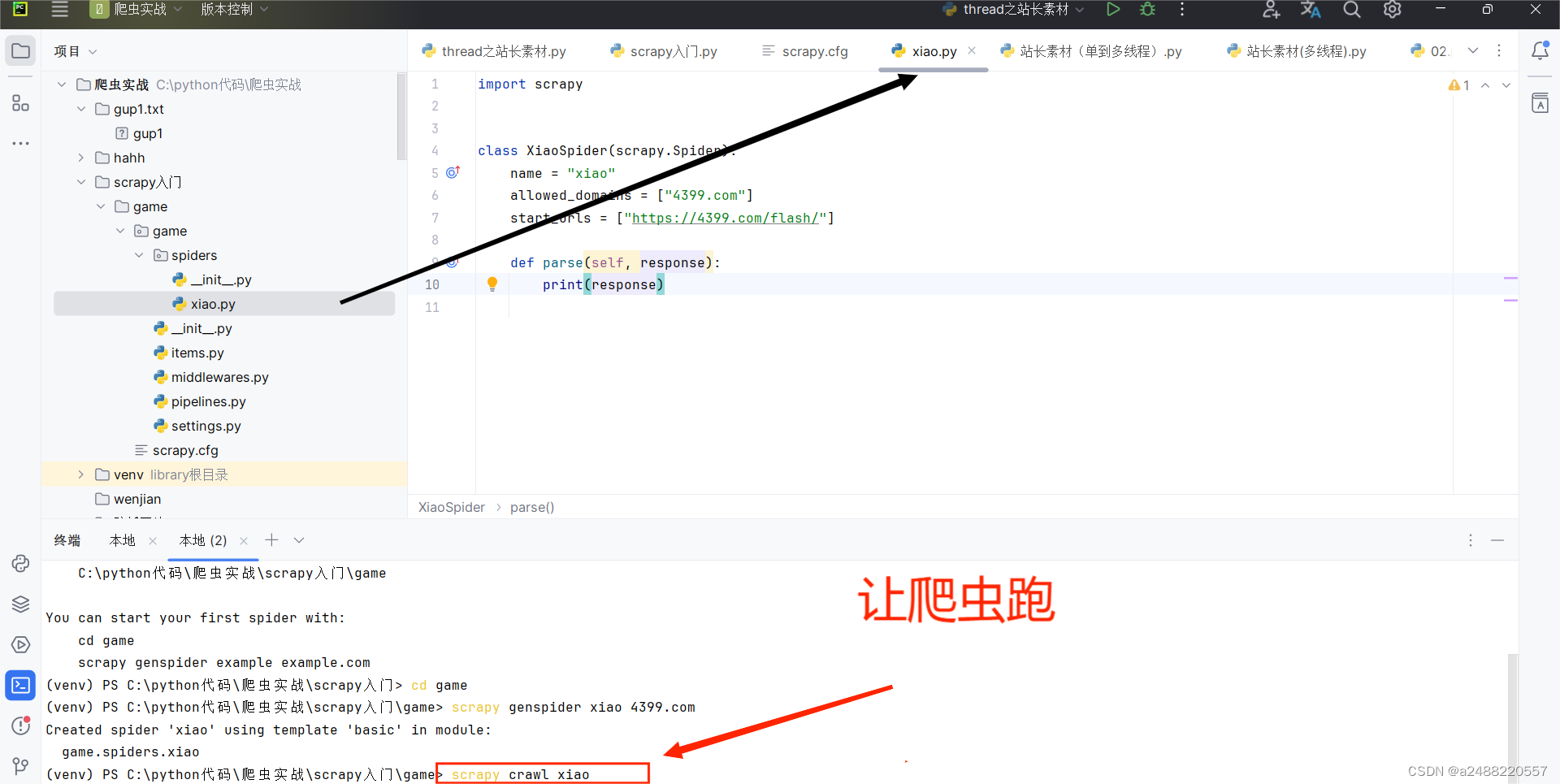
4.
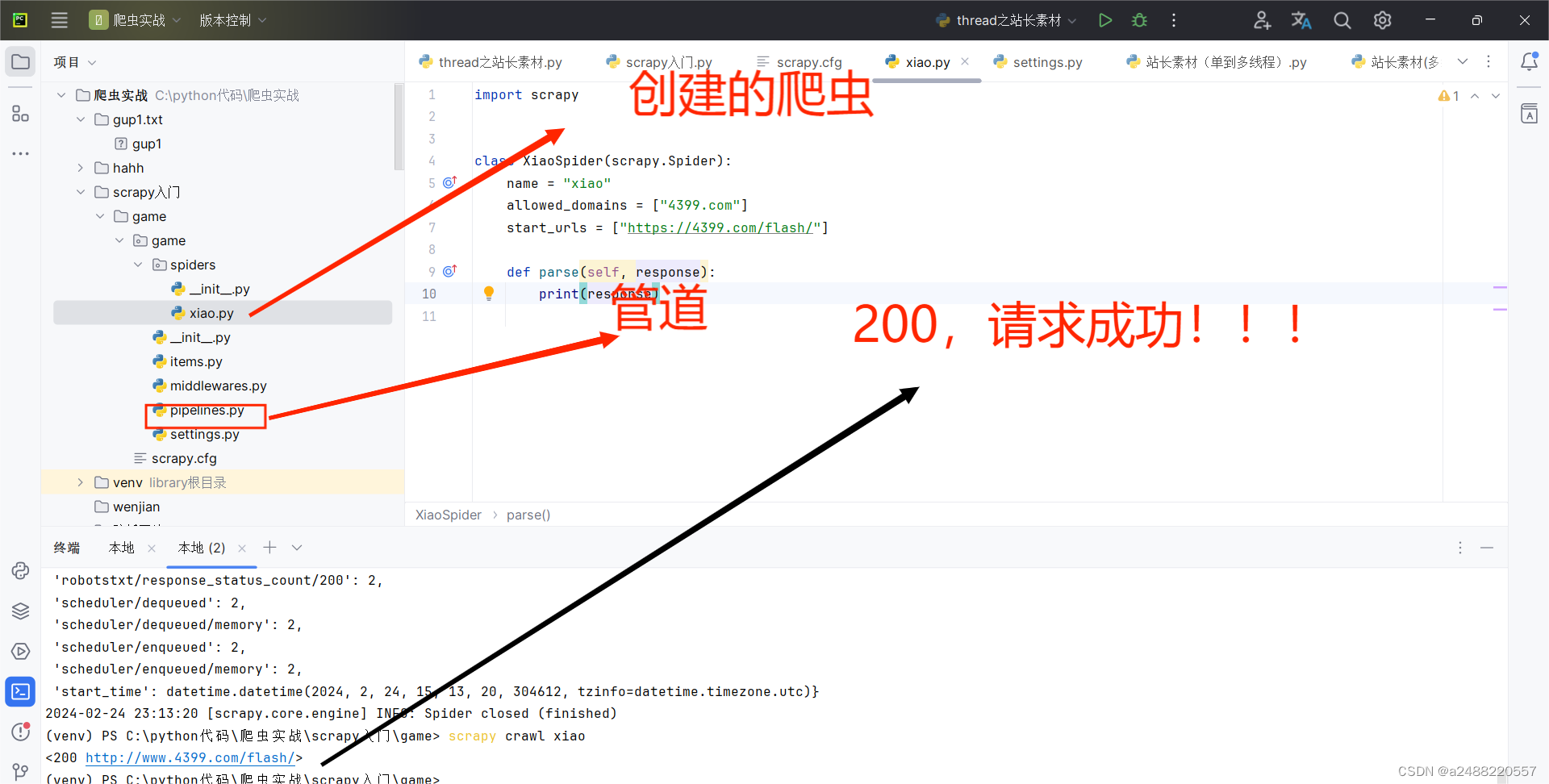
其中代码中,scrapy给我们了,寻找的方法
response.xpath(),respon,css()。
没有见过的是:
leibie = list.xpath("./em/a/text()").extract_first()
的extract(),这个就是
提取信息内容
学习笔记加油!!!
这篇关于线程池(ThreadPoolExecutor,as_completed)和scrapy框架初步构建——学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






