本文主要是介绍NEO4J中文分词全文索引自动更新解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NEO4J中文分词全文索引自动更新解决方案
- 一、样例数据
- 二、英文与中文全文索引差别
- 1、创建NEO4J默认索引
- 2、删除索引
- 3、创建支持中文分词的索引
- 三、APOC自带英文全文索引过程(可自动更新索引)
- 1、添加全文索引
- 2、新增节点与属性
- 3、检索
- 四、自定义中文分词全文索引插件(自动更新索引不成功)
- 1、添加全文索引
- 2、新增节点与属性
- 3、检索
- 五、标签交叉检索
- 六、自定义中文分词插件(自动更新索引失败单独更新节点索引)
- 1、添加全文索引
- 2、新增节点与属性并更新全文索引
- 3、将2新增的节点或者更新的属性增加到索引
- 4、检索
- 七、解决事务提交超时
- 八、备注
使用NEO4J INDEX API实现自动更新失败,转换了一种思路解决这个问题(在更新节点或者新建节点的时候同步更新到对应的全文索引中。)
一、样例数据
样例数据格式参考
二、英文与中文全文索引差别
1、创建NEO4J默认索引
CALL apoc.index.addAllNodes('Loc', {Loc:["description","cause","year"]})
// 以下检索不成功:
CALL apoc.index.search('Loc', 'Loc.description:中文~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:中文*') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:测试~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:测试中文~') YIELD node RETURN node
2、删除索引
CALL apoc.index.remove('Loc')
3、创建支持中文分词的索引
CALL zdr.index.addChineseFulltextIndex('Loc', ["description","cause","year"], 'Loc') YIELD message RETURN message
// 以下检索成功:
CALL apoc.index.search('Loc', 'description:中文~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'description:中文*') YIELD node RETURN node
CALL apoc.index.search('Loc', 'description:测试~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'description:测试中文~') YIELD node RETURN node
三、APOC自带英文全文索引过程(可自动更新索引)
1、添加全文索引
CALL apoc.index.addAllNodes('Loc', {Loc:["description","cause","year"]},{autoUpdate:true})
2、新增节点与属性
CREATE (n:Loc {name:'V'}) SET n.description='测试中文分词,复联终章快上映了好激动,据说知识图谱与人工智能技术应用到了那部电影!',n.cause='测试英文分词,Mobile World Congress, the world’s largest gathering for the mobile industry, ' RETURN n
3、检索
可以支持索引的自动更新,但是对于中文的检索不友好,例如以下测试:
// 检索失败:
CALL apoc.index.search('Loc', 'Loc.cause:测试英文分词~') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:测试中文分词~') YIELD node RETURN node
// 检索成功:
CALL apoc.index.search('Loc', 'Loc.cause:测试英文分词*') YIELD node RETURN node
CALL apoc.index.search('Loc', 'Loc.description:测试中文分词*') YIELD node RETURN node
四、自定义中文分词全文索引插件(自动更新索引不成功)
addChineseFulltextAutoIndex过程为添加支持中文的全文索引过程,创建全文索引可以成功,但是对于节点的新增属性的更新,不支持自动更新。
1、添加全文索引
CALL zdr.index.addChineseFulltextAutoIndex('IKAnalyzer',["description","cause","year"],'Loc',{autoUpdate:'true'}) YIELD message RETURN message
2、新增节点与属性
CREATE (n:Loc {name:'V'}) SET n.description='测试中文分词,复联终章快上映了好激动,据说知识图谱与人工智能技术应用到了那部电影!',n.cause='测试英文分词,Mobile World Congress, the world’s largest gathering for the mobile industry, ' RETURN n
3、检索
添加全文检索之后就可以检索:
CALL zdr.index.chineseFulltextIndexSearch('IKAnalyzer', 'description:吖啶基氨基甲烷磺酰甲氧基苯胺', 100) YIELD node RETURN node
重新索引之后才能检索到:
CALL zdr.index.chineseFulltextIndexSearch('IKAnalyzer', 'description:测试~', 100) YIELD node RETURN node
五、标签交叉检索
addChineseFulltextAutoIndex/addChineseFulltextIndex支持多标签的同时检索,在建立索引时使用相同的索引名即可。
标签:Loc
CALL zdr.index.addChineseFulltextAutoIndex('Loc',["description","cause","name"],'Loc',{autoUpdate:'true'}) YIELD message RETURN message
标签:LocProvince’
CALL zdr.index.addChineseFulltextAutoIndex('Loc',["description","cause","name"],'LocProvince',{autoUpdate:'true'}) YIELD message RETURN message
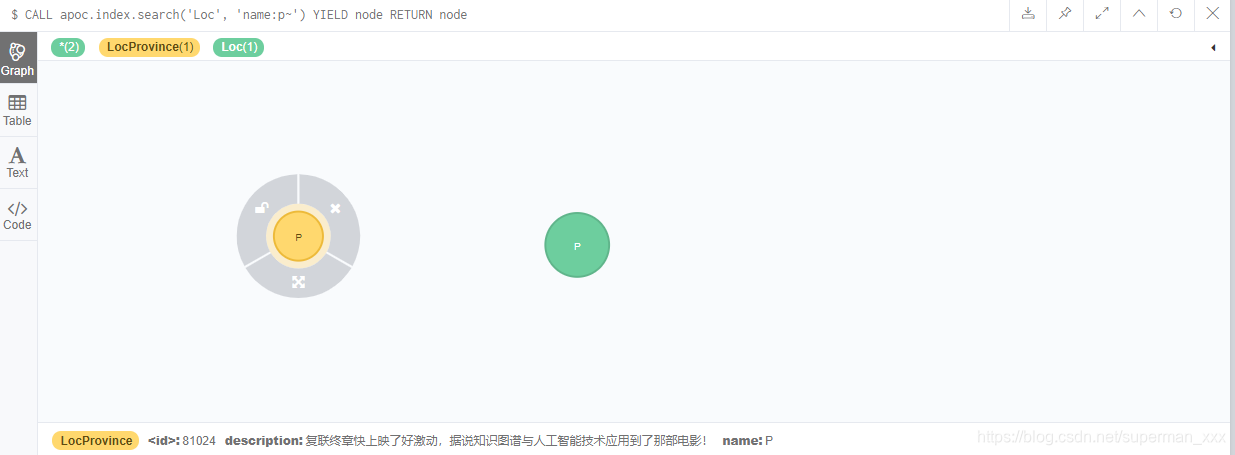
检索节点:
CALL apoc.index.search('Loc', 'name:p~') YIELD node RETURN node
六、自定义中文分词插件(自动更新索引失败单独更新节点索引)
为了支持单节点的索引更新,开发以下过程。(三中所描述的自动更新方案失败,转为在更新节点或者新建节点的时候同步更新到对应的全文索引中。)
1、添加全文索引
CALL apoc.index.remove('Loc')
CALL zdr.index.addChineseFulltextIndex('Loc',["description","cause","year"],'Loc') YIELD message RETURN message
2、新增节点与属性并更新全文索引
CREATE (n:Loc {name:'V'}) SET n.description='测试中文分词,复联终章快上映了好激动,据说知识图谱与人工智能技术应用到了那部电影!',n.cause='测试英文分词,Mobile World Congress, the world’s largest gathering for the mobile industry, ' RETURN n
3、将2新增的节点或者更新的属性增加到索引
MATCH (n) WHERE n.name='V' WITH n CALL zdr.index.addNodeChineseFulltextIndex(n, ['description']) RETURN *
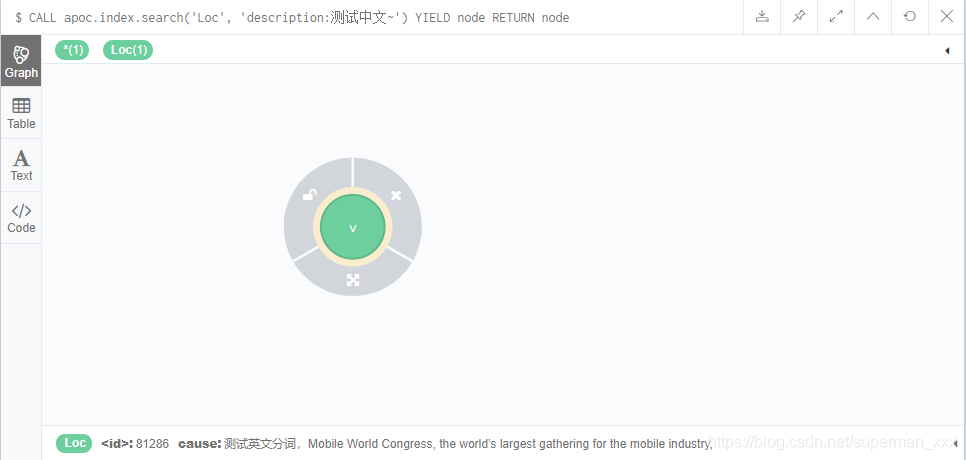
4、检索
CALL zdr.index.chineseFulltextIndexSearch('Loc', 'description:测试中文~') YIELD node RETURN node
七、解决事务提交超时
如果配置了事务提交超时设置,在构建索引时取消。
#********************************************************************
### Neo4j transcation timeout
###******************************************************************
#dbms.transaction.timeout=180s
使用后台脚本执行构建索引程序:
# index.sh
#!/usr/bin/env bash
nohup /neo4j-community-3.4.9/bin/neo4j-shell -file build.cql >>indexGraph.log 2>&1 &
// build.cql
CALL zdr.index.addChineseFulltextIndex('IKAnalyzer', ['description','fullname','name','lnkurl'], 'LinkedinID') YIELD message RETURN message;
八、备注
如果使用APOC自带的过程,设置自动更新配置之后即可,但是会影响性能。
apoc.autoIndex.enabled=true
// 构建示例
CALL apoc.index.addAllNodes('Loc', {Loc:["description","cause","year"]},{autoUpdate:true})
上述所有涉及到的NEO4J自定义过程参考
这篇关于NEO4J中文分词全文索引自动更新解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




