本文主要是介绍基于python3.6+tensorflow2.2的石头剪刀布案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
unzip_save.py
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 不显示等级2以下的提示信息
import zipfile
import matplotlib.pyplot as plt
import matplotlib.image as mpimg# 解压
local_zip1 = 'E:/Python/pythonProject_1/rps/tmp/rps.zip' # 数据集压缩包路径
zip_ref1 = zipfile.ZipFile(local_zip1, 'r') # 打开压缩包,以读取方式
zip_ref1.extractall('E:/Python/pythonProject_1/rps/tmp/') # 解压到以下路径
zip_ref1.close()local_zip2 = 'E:/Python/pythonProject_1/rps/tmp/rps-test-set.zip' # 数据集压缩包路径
zip_ref2 = zipfile.ZipFile(local_zip2, 'r') # 打开压缩包,以读取方式
zip_ref2.extractall('E:/Python/pythonProject_1/rps/tmp/') # 解压到以下路径
zip_ref2.close()rock_dir = os.path.join('E:/Python/pythonProject_1/rps/tmp/rps/rock')
paper_dir = os.path.join('E:/Python/pythonProject_1/rps/tmp/rps/paper')
scissors_dir = os.path.join('E:/Python/pythonProject_1/rps/tmp/rps/scissors')rock_files = os.listdir(rock_dir)
print(rock_files[:10])paper_files = os.listdir(paper_dir)
print(paper_files[:10])scissors_files = os.listdir(scissors_dir)
print(scissors_files[:10])pic_index = 2
next_rock = [os.path.join(rock_dir, fname)for fname in rock_files[pic_index - 2:pic_index]]
next_paper = [os.path.join(paper_dir, fname)for fname in paper_files[pic_index - 2:pic_index]]
next_scissors = [os.path.join(scissors_dir, fname)for fname in scissors_files[pic_index - 2:pic_index]]for i, img_path in enumerate(next_rock+next_paper+next_scissors):img = mpimg.imread(img_path)plt.imshow(img)plt.axis('Off')plt.show()model_training_fit.py
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 不显示等级2以下的提示信息import tensorflow as tf
# from tensorflow import keras
# from tensorflow.keras.optimizers import RMSprop
# from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plttraining_datagen = ImageDataGenerator(# 数据增强rescale=1. / 255,rotation_range=40, # 旋转范围width_shift_range=0.2, # 宽平移height_shift_range=0.2,# 高平移shear_range=0.2, # 剪切zoom_range=0.2, # 缩放horizontal_flip=True,fill_mode='nearest'
)validation_datagen = ImageDataGenerator(rescale=1. / 255
)TRAINING_DIR = 'E:/Python/pythonProject_1/rps/tmp/rps/'
training_generator = training_datagen.flow_from_directory(TRAINING_DIR,target_size = (150, 150),class_mode = 'categorical'
)VALIDATION_DIR = 'E:/Python/pythonProject_1/rps/tmp/rps-test-set/'
validation_generator = validation_datagen.flow_from_directory(VALIDATION_DIR,target_size = (150, 150),class_mode = 'categorical'
)#======== 模型构建 =========
model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(64, (3, 3), activation = 'relu', input_shape = (150, 150, 3)), # 输入参数:过滤器数量,过滤器尺寸,激活函数:relu, 输入图像尺寸tf.keras.layers.MaxPooling2D(2, 2), # 池化:增强特征tf.keras.layers.Conv2D(64, (3, 3), activation = 'relu'), # 输入参数:过滤器数量、过滤器尺寸、激活函数:relutf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), # 输入参数:过滤器数量、过滤器尺寸、激活函数:relutf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), # 输入参数:过滤器数量、过滤器尺寸、激活函数:relutf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Flatten(), # 输入层tf.keras.layers.Dense(512, activation = 'relu'), # 全连接隐层 神经元数量:128 ,激活函数:relutf.keras.layers.Dense(3, activation = 'softmax') # 英文字母分类 26 ,阿拉伯数字分类 10 输出用的是softmax 概率化函数 使得所有输出加起来为1 0-1之间
])model.summary()#======== 模型参数编译 =========
model.compile(optimizer = 'rmsprop',loss = 'categorical_crossentropy', # 损失函数: 稀疏的交叉熵 binary_crossentropymetrics = ['accuracy']
)#======== 模型训练 =========
# Note that this may take some time.
history = model.fit_generator(training_generator,epochs = 25,validation_data = validation_generator,verbose = 1
)model.save('E:/Python/pythonProject_1/rps/model.h5') # model 保存#-----------------------------------------------------------
# Retrieve a list of list result on training and test data
# set for each training epoch
#-----------------------------------------------------------
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc)) # Get number of epochs#-----------------------------------------------------------
# Plot training and validation accuracy per epoch
#-----------------------------------------------------------
plt.plot(epochs, acc, 'r', label = "tra_acc")
plt.plot(epochs ,val_acc, 'b', label = "val_acc")
plt.title("training and validation accuracy")
plt.legend(loc=0)
plt.grid(ls='--') # 生成网格
plt.show()
# 曲线呈直线是因为epochs/轮次太少
#-----------------------------------------------------------
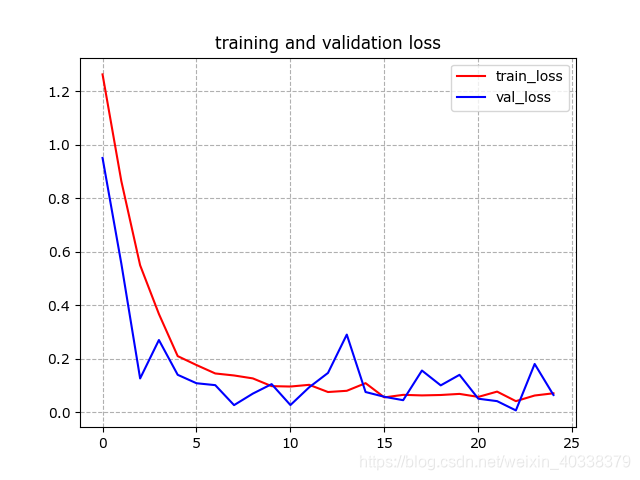
# Plot training and validation loss per epoch
#-----------------------------------------------------------
plt.plot(epochs, loss, 'r', label = "train_loss")
plt.plot(epochs ,val_loss, 'b', label = "val_loss")
plt.title("training and validation loss")
plt.legend(loc=0)
plt.grid(ls='--') # 生成网格
plt.show()
# 曲线呈直线是因为epochs/轮次太少predict.py
import numpy as np
from tensorflow.keras.preprocessing import image
from tensorflow import keras
model = keras.models.load_model('E:/Python/pythonProject_1/rps/model.h5')# predicting images
path = 'E:/Python/pythonProject_1/rps/scissor.png'
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)images = np.vstack([x])
classes = model.predict(images, batch_size=10)
print(classes)model.summary
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 64) 1792
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense (Dense) (None, 512) 3211776
_________________________________________________________________
dense_1 (Dense) (None, 3) 1539
=================================================================
Total params: 3,473,475
Trainable params: 3,473,475
Non-trainable params: 0
_________________________________________________________________测试结果:
Epoch 23/25
79/79 [==============================] - 83s 1s/step - loss: 0.0410 - accuracy: 0.9905 - val_loss: 0.0064 - val_accuracy: 1.0000
Epoch 24/25
79/79 [==============================] - 82s 1s/step - loss: 0.0621 - accuracy: 0.9798 - val_loss: 0.1802 - val_accuracy: 0.9382
Epoch 25/25
79/79 [==============================] - 82s 1s/step - loss: 0.0704 - accuracy: 0.9821 - val_loss: 0.0640 - val_accuracy: 0.9704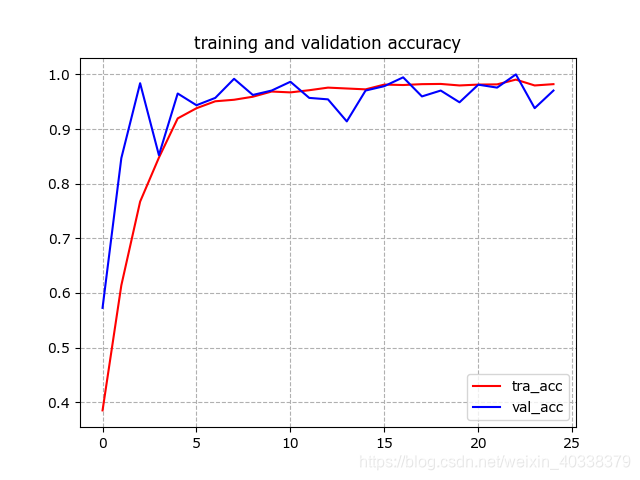
预测结果:
scissor.png

>>> print(classes)[[0. 0. 1.]]数据来源地址: https://laurencemoroney.com/datasets.html
这篇关于基于python3.6+tensorflow2.2的石头剪刀布案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






