本文主要是介绍redis7高级篇2 redis的BigKey的处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一 Bigkey的处理
1.1 模拟造数
1.截图

2.代码 :使用pipe 批量插入10w的数据量
cat /root/export/monidata.txt | redis-cli -h 127.0.0.1 -a 123456 -p 6379 --pipe
[root@localhost export]# for((i=1;i<=10*10;i++)); do echo "set k$i v$i" >> /root/export/monidata.txt ;done;
[root@localhost export]# ls
dockertest dump.rdb monidata.txt myredis-data nacos nacos-1.4.2 redis-7.0.10 redis-7.0.10.tar.gz rocketmq-all-4.9.6-bin-release rocketmq-all-4.9.6-bin-release.zip servers
[root@localhost export]# cat /root/export/monidata.txt | redis-cli -h 127.0.0.1 -a 123456 -p 6379 --pipe
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 100
[root@localhost export]#
3.查看

4.查看数据量大小
 1.2 设置禁用一些危险命令
1.2 设置禁用一些危险命令
1.线上不能使用 keys *
2.不能使用 flushdb
3.不能使用 flushdball
在redis的redis.conf配置文件中进行修改: 通过搜索关键字: rename-command ;进行修改
rename-command keys "" ; rename-command flushdb "" ;
[root@localhost myredis]# vi redis.conf
[root@localhost myredis]# pwd
/myredis
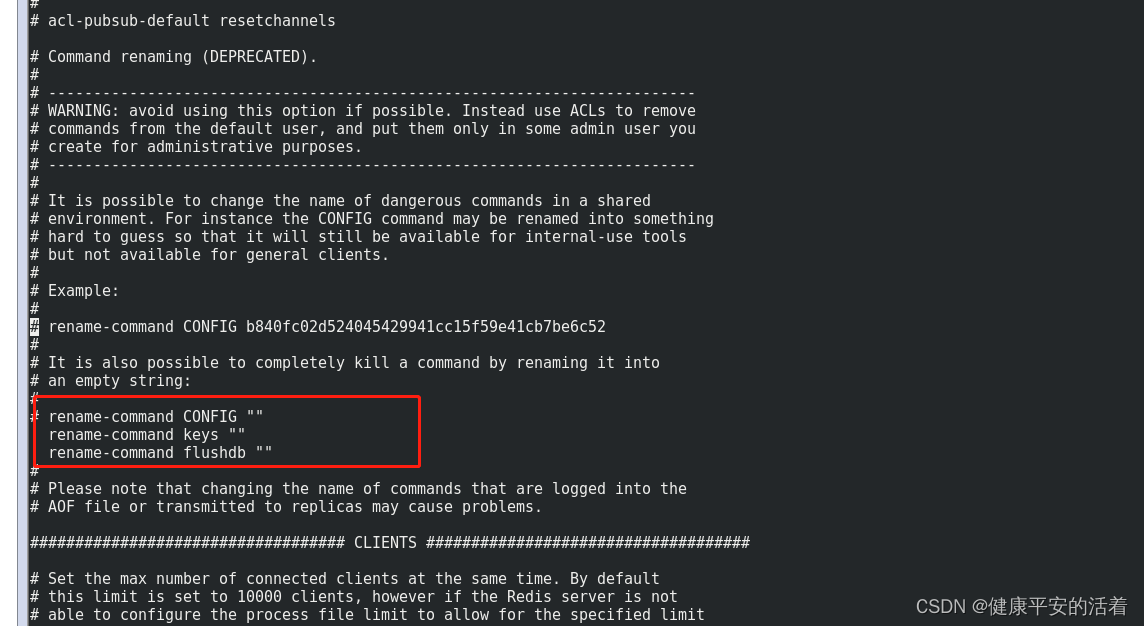
2.重启服务,查看效果
[root@localhost ~]# redis-server /myredis/redis.conf
[root@localhost ~]# redis-cli -a 123456 -p 6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> keys *
(error) ERR unknown command 'keys', with args beginning with: '*'
127.0.0.1:6379> flushdb
(error) ERR unknown command 'flushdb', with args beginning with:
127.0.0.1:6379>
1.3 大key的判断依据
string类型的key控制在10kb以内,hash,list,set,zset元素的个数不要超过5000
非string的bigkey,不要使用del删除,使用hscan、sscan、zscan等方式进行渐进式删除。
1.4 删除命令逻辑
#string
1.使用del命令 ,超大使用unlink命令
#hash
2.使用hscan每次获取少量的field-value,再使用hdel删除每个field
#list
3.使用ltrim渐进式逐步删除,直到全部删除完成。
#set
4.使用sscan命令获取部分元素,再使用srem命令删除每个元素
#zset
5.使用zscan每次获取部分元素,再使用zremrangebyrank命令删除每个元素
二 scan命令的操作
2.1 使用scan命令查看数据
scan命令用于获取数据库中的键。一次返回的数据不可控,只是大概返回count数。
SCAN 命令是一个基于游标的迭代器,每次被调用之后,都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数,从而让迭代过程延续下,当游标返回 0 时,迭代结束。
语法格式:scan 游标 pattern count取出的条数
返回值:SCAN 返回一个包含两个元素的数组, 第一个元素是用于进行下一次迭代的新游标, 而第二个元素则是一个数组, 这个数组中包含了所有被迭代的元素。
案例:
127.0.0.1:6379> scan 0 match * count 10
1) "120"
2) 1) "k66"
2) "k49"
3) "k35"
4) "k23"
5) "k12"
6) "k83"
7) "k22"
8) "k36"
9) "k61"
10) "k47"
截图:

2.2 scan命令分类用途
Scan命令又细分为:scan命令,Sscan命令、Hscan命令、Zscan命令。
- scan命令用于迭代字符串中的元素。
- Sscan命令用于迭代集合键中的元素。
- Hscan命令用于迭代哈希键中的键值对。
- Zscan命令用于迭代有序集合中的元素(包括元素成员和元素分值)
三 Bigkey的处理
string类型的key控制在10kb以内,hash,list,set,zset元素的个数不要超过5000
非string的bigkey,不要使用del删除,使用hscan、sscan、zscan等方式进行渐进式删除。
3.1 发现大key的命令
1.使用memory usage 命令
127.0.0.1:6379> memory usage k32
(integer) 56
127.0.0.1:6379> memory usage k100
(integer) 56
127.0.0.1:6379>
2.使用bigkeys命令
[root@localhost myredis]# redis-cli -h 127.0.0.1 -p 6379 -a 123456 --bigkeys
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"k66"' with 3 bytes
[41.00%] Biggest string found so far '"k100"' with 4 bytes
-------- summary -------
Sampled 100 keys in the keyspace!
Total key length in bytes is 292 (avg len 2.92)
Biggest string found '"k100"' has 4 bytes
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
100 strings with 292 bytes (100.00% of keys, avg size 2.92)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
[root@localhost myredis]# redis-cli -h 127.0.0.1 -p 6739 -a 123456 --bigkeys -l 0.1
3.2 大key的删除
3.2.1 String类型的删除
一般使用del,如果过于庞大则使用unlink
127.0.0.1:6379> set bj 123
OK
127.0.0.1:6379> get bj
"123"
127.0.0.1:6379> del bj
(integer) 1
127.0.0.1:6379> get bj
(nil)
127.0.0.1:6379>
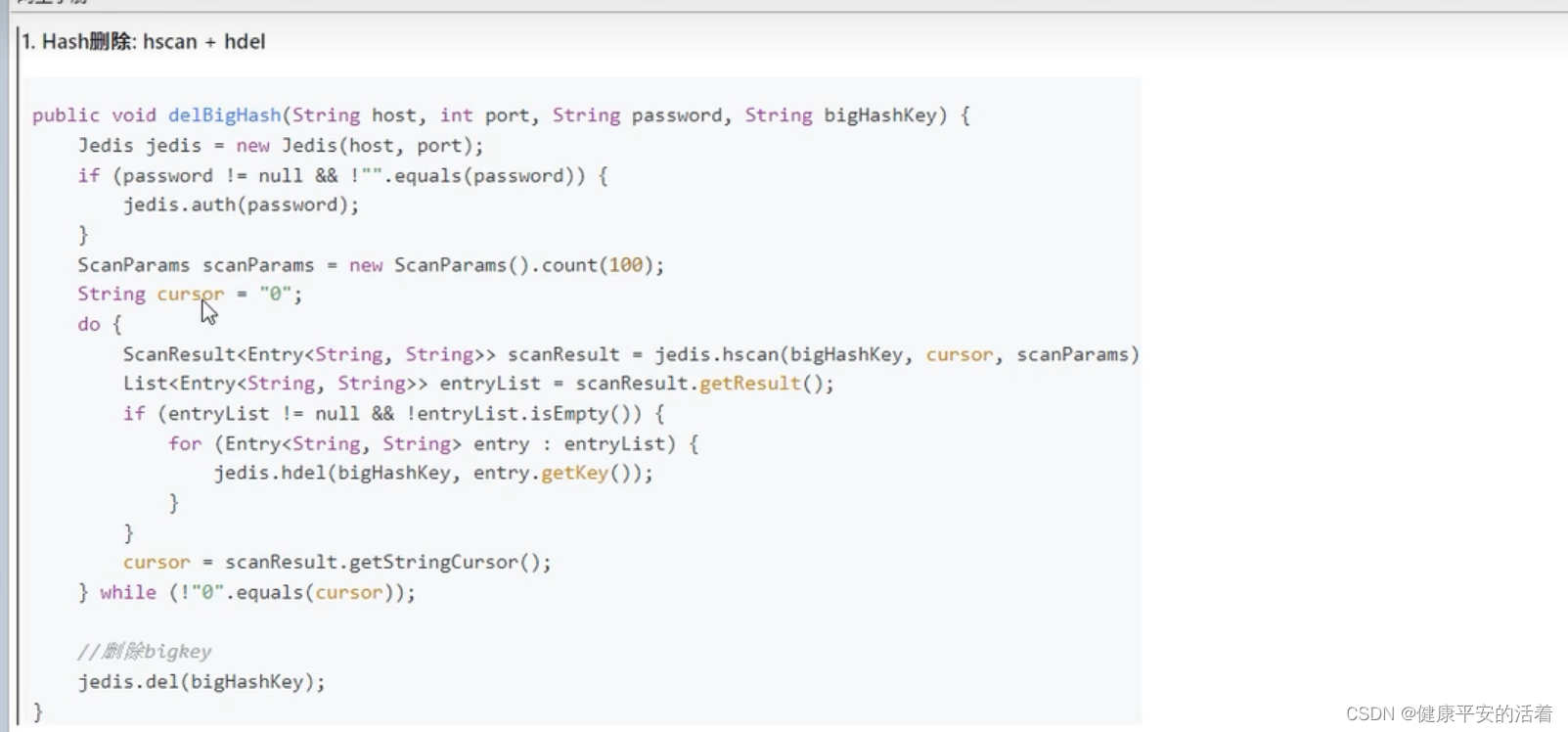
3.2.2 Hash数据类型删除
1.使用hscan每次获取少量的field-value,再使用hdel删除每个field
1.查询命令
127.0.0.1:6379> hmset website ws1 "beijing.com" ws2 "tianjin.com" ws3 "shanghai.com"
OK
127.0.0.1:6379> hscan website 0 match * count 2
1) "0"
2) 1) "ws1"
2) "beijing.com"
3) "ws2"
4) "tianjin.com"
5) "ws3"
6) "shanghai.com"
删除
127.0.0.1:6379> hscan website 0 match *
1) "0"
2) 1) "ws1"
2) "beijing.com"
3) "ws2"
4) "tianjin.com"
5) "ws3"
6) "shanghai.com"
127.0.0.1:6379> hdel website ws1
(integer) 1
127.0.0.1:6379> hscan website 0 match *
1) "0"
2) 1) "ws2"
2) "tianjin.com"
3) "ws3"
4) "shanghai.com"
127.0.0.1:6379>
2.java代码
3.2.3 List类型删除
1.使用ltrim渐进式逐步删除,直到全部删除完成。
Lrim命令的作用是: 让列表只保留制定区间内的元素,不在制定区间的内容将被删除。
2.命令演示
27.0.0.1:6379> rpush list v1 v2 v3 v4 v5
(integer) 5
127.0.0.1:6379> lrange list 0 -1
1) "v1"
2) "v2"
3) "v3"
4) "v4"
5) "v5"
127.0.0.1:6379> ltrim list 0 2
OK
127.0.0.1:6379> lrange list 0 -1
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379>
3.java代码

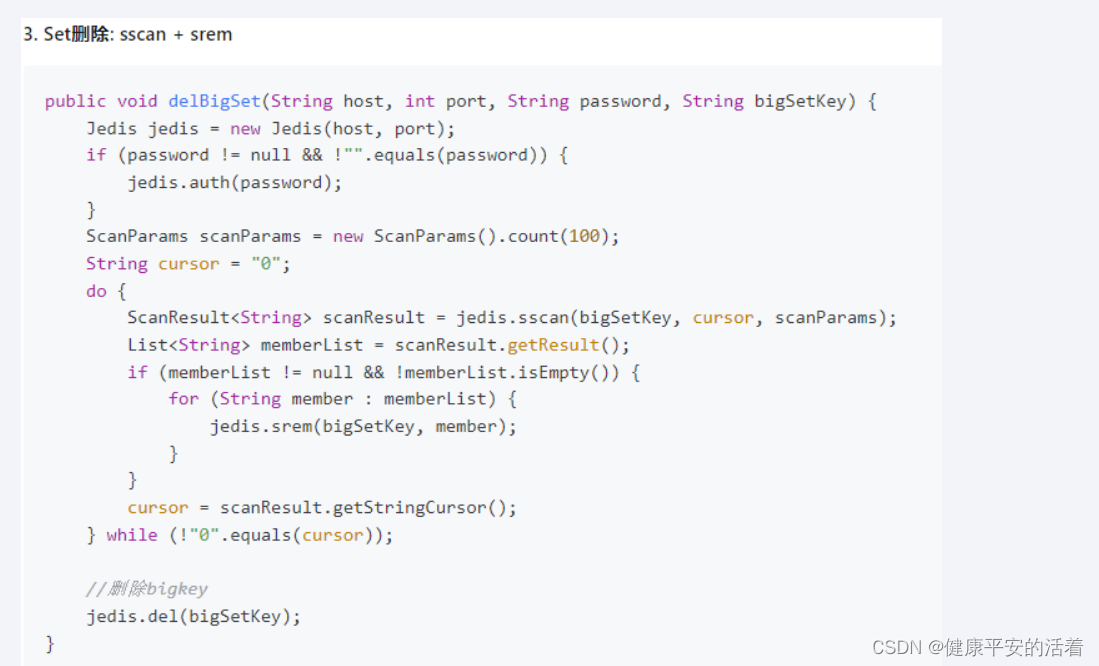
3.2.4 set类型删除
1.使用sscan命令获取部分元素,再使用srem命令删除每个元素
2.命令案例
127.0.0.1:6379> sadd sk1 111 222 333 5 6 8
(integer) 6
127.0.0.1:6379> smembers sk1
1) "5"
2) "6"
3) "8"
4) "111"
5) "222"
6) "333"
127.0.0.1:6379> srem sk1 333
(integer) 1
127.0.0.1:6379> smembers sk1
1) "5"
2) "6"
3) "8"
4) "111"
5) "222"
127.0.0.1:6379> sscan sk1 0 match *
1) "0"
2) 1) "5"
2) "6"
3) "8"
4) "111"
5) "222"
3.java代码
3.2.5 zset类型删除
1.使用zscan每次获取部分元素,再使用zremrangebyrank命令删除每个元素
2.命令代码
127.0.0.1:6379> zadd ks 20 v1 70 v2 45 v3 50 v4 90 v5
(integer) 5
127.0.0.1:6379> zrange ks 0 -1 withscores
1) "v1"
2) "20"
3) "v3"
4) "45"
5) "v4"
6) "50"
7) "v2"
8) "70"
9) "v5"
10) "90"
127.0.0.1:6379> zscan ks 0
1) "0"
2) 1) "v1"
2) "20"
3) "v3"
4) "45"
5) "v4"
6) "50"
7) "v2"
8) "70"
9) "v5"
10) "90"
127.0.0.1:6379> zremrangebyrank ks 0 1
(integer) 2
127.0.0.1:6379> zrange ks 0 -1 withscores
1) "v4"
2) "50"
3) "v2"
4) "70"
5) "v5"
6) "90"
127.0.0.1:6379>
3.3 bigkey的优化
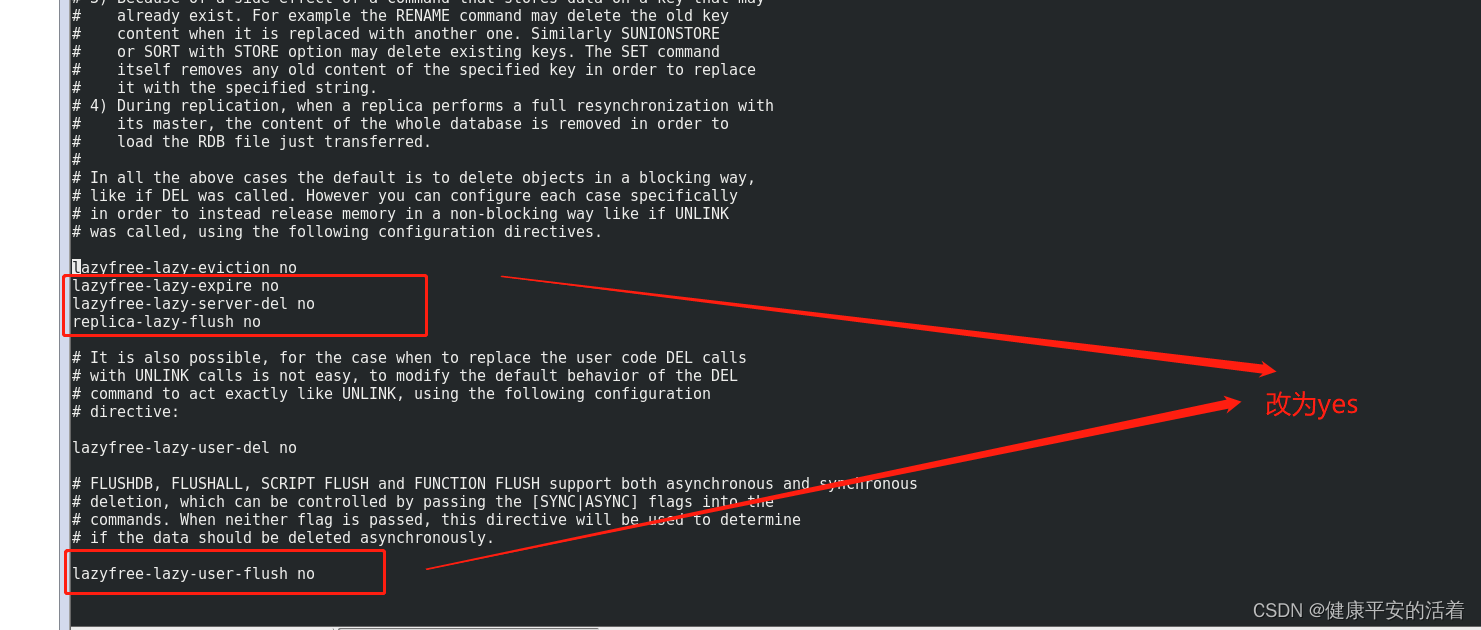
1.在配置文件中,修改redis.conf配置文件,修改这几项参数:改为yes。
这篇关于redis7高级篇2 redis的BigKey的处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









