本文主要是介绍StarRocks加速查询——低基数全局字典,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
StarRocks-2.0引入了低基数全局字典,可以通过全局字典将字符串的相关操作转换成整型相关操作,极大提升了查询性能。StarRocks 2.0+后的版本默认会开启低基数字典优化。
一、低基数字典
对于利用整型替代字符串进行处理,通常使用字典编码进行优化。一个 SQL 从输入到输出结果,往往会经过这几个步骤,几乎每一个阶段都可以使用字典优化:Scan,Filter,Agg,Join,Shuffle,Sort。以 Filter为例:
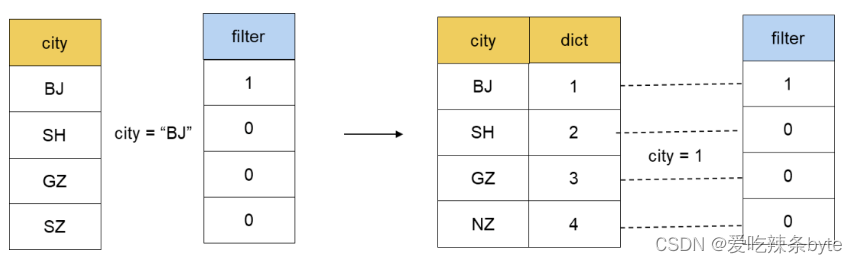
对于 Filter 阶段来说,如果某一个列是用字典编码的,我们就可以直接使用编码之后的整数进行比较,而不是直接用 String 进行比较操作。大多数情况下,整数之间的 Compare 性能会高于字符串之间的性能。
二、全局字典
分布式执行引擎中,一个查询可能会涉及多个机器多个任务之间数据交换。因此执行过程中需要保证字典全局性。字典数据始终贯穿 SQL 执行的整个生命周期,如果不是全局字典,那么加速只能在局部进行。例如如果两个执行节点的字典编码不一致,那么在网络传输过程中需要同时把字典传给对端机器,或者是需要提前把字典码转为字符串再通过网络发送。StarRocks中有全局字典,各个节点之间共享同一个字典,那么就不需要发送后再进行解码并转换字典码了。StarRocks 2.0+后的版本默认会开启低基数字典优化。
三、全局字典构建
3.1 建表时定义
用户在建表的时候,指定对应的列为低基数列。
这种方式对用户不友好,并且不易维护
ps:低基数列:取值区分度小的字段,例如性别,婚姻状态等。StarRocks支持对低基数列创建Bitmap位图索引来加速数据查询。(高基数列:例如UserID)
3.2 导入时构建全局字典
导入数据时,通过中心节点维护全局字典。每次遇到新的的字符都要通过中心节点创建一个新的字典码。但是这么做的主要问题是中心节点很容易会成为瓶颈。另外中心节点因为需要同时处理维护并发控制。
3.3 StarRocks 全局字典的构建
3.3.1 数据存储上的字典优化
先回顾下 StarRocks的数据存储的结构。 StarRocks的底层存储单元为Segment,每个Segment 的存储结构(简易版)如下:

StarRocks 的存储结构天然为低基数字符串做了字典编码。对于 Segment 上的低基数字符串列会有以下特点:
-
Footer上会存储有这个Column 特有的字典信息,包括字典码跟原始字符串之间的映射关系;
-
Data page 上存储的不是原始字符串,而是整数类型的字典码(整型)。

当处理低基数 String column 的时候,直接使用编码后的字典码,而不是直接处理原始的 String 值。当需要原始的 String 值时,使用字典码就可以很方便地在这个列的字典信息里面拿到原始 String 值。这么做带来的明显好处是:(1)减少了磁盘IO;(2)可以提前做一些过滤操作,提升处理速度。
3.3.2 全局字典的构建
StarRocks 支持 CBO 优化器,并且存在一套统计信息机制,那么就可以通过统计信息来收集全局字典。我们通过统计信息,筛选出潜在的低基数列,再从潜在的低基数列的元数据中读取字典信息,然后做去重/编码操作,就可以收集到全量的字典了。
3.3.3 低基数String优化的特点
总结,StarRocks 的低基数String 优化,主要的特点有:
全局的字典加速,作用于 SQL 执行的各个阶段。
不需要用户通过 Schema 指定特定低基数列,而是基于CBO 优化器,自动选择全局字典的加速策略。
四、使用 auto increment列构建全局字典
这部分主要介绍【使用 auto increment 列构建全局字典以加速精确去重计算和 join】。
參考文章:
滴滴 x StarRocks:极速多维分析创造更大的业务价值-腾讯云开发者社区-腾讯云
国产数据库-内核特性-低基数全局字典
StarRocks 技术内幕 | 基于全局字典的极速字符串查询
这篇关于StarRocks加速查询——低基数全局字典的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





