本文主要是介绍srs集群下行edge处理逻辑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
官方关于源站集群的介绍:
Origin Cluster | SRS
下行边缘是指观众端从边缘edge拉流,边缘edge回源到源站origin节点拉流,然后再
把流转给客户端
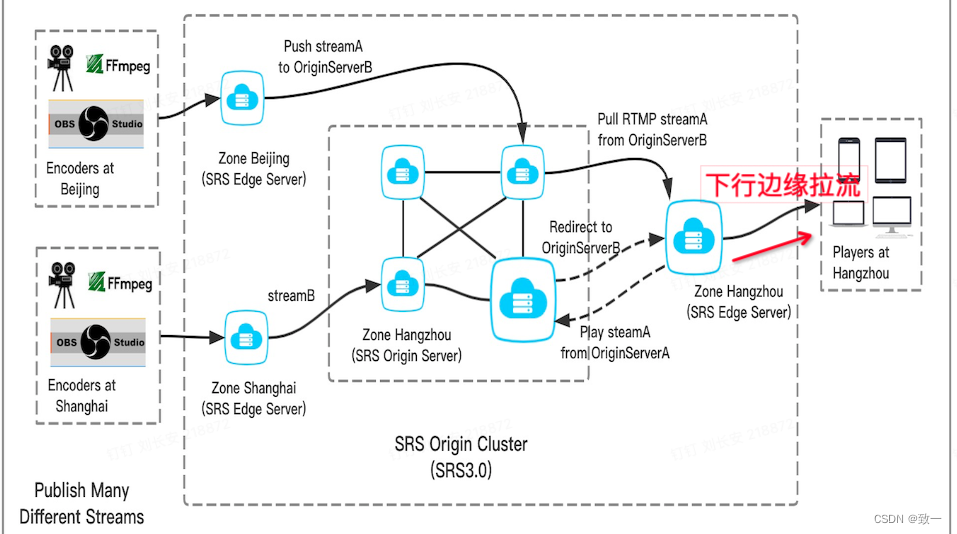
边缘处理类SrsPlayEdge
当服务器收到播放请求时,创建对应的consumer消费者。在创建消费者consumer时会判断当前服务器的类型,如果服务器是边缘edge,就通过play_edge进行处理。每一个SrsLiveSource都有一个对应的 SrsPlayEdge *play_edge,如果配置文件指定了remote才开启边缘逻辑。
srs_error_t SrsLiveSource::create_consumer(ISrsConnection* conn, SrsLiveConsumer*& consumer)
{srs_error_t err = srs_success;consumer = new SrsLiveConsumer(this, conn);consumers.push_back(consumer);if (conn != NULL) {conn->srsConsumer = consumer;}// There should be one consumer, so reset the timeout.stream_die_at_ = 0;publisher_idle_at_ = 0;//通过配置文件中的参数,判断是否是边缘服务器//如果是边缘服务器,则调用 play_edge进行拉流播放//SrsPlayEdge* play_edge;// for edge, when play edge stream, check the stateif (_srs_config->get_vhost_is_edge(req->vhost)) {// notice edge to start for the first client.if ((err = play_edge->on_client_play()) != srs_success) {return srs_error_wrap(err, "play edge");}}return err;
}SrsPlayEdge会通过SrsEdgeIngester进行拉流
srs_error_t SrsPlayEdge::on_client_play()
{srs_error_t err = srs_success;//SrsEdgeIngester ingester 启动一个新的协程去源站拉流// start ingest when init state.if (state == SrsEdgeStateInit) {state = SrsEdgeStatePlay;err = ingester->start();} else if (state == SrsEdgeStateIngestStopping) {return srs_error_new(ERROR_RTMP_EDGE_PLAY_STATE, "state is stopping");}return err;
}拉流类SrsEdgeIngester
SrsEdgeIngester会启动一个协程SrsSTCoroutine进行拉流处理
srs_error_t SrsEdgeIngester::start()
{srs_error_t err = srs_success;if ((err = source->on_publish()) != srs_success) {return srs_error_wrap(err, "notify source");}srs_freep(trd);trd = new SrsSTCoroutine("edge-igs", this);if ((err = trd->start()) != srs_success) {return srs_error_wrap(err, "coroutine");}return err;
}真正拉流类 SrsEdgeUpstream
协程会有一个while循环不停的去拉流,目前边缘回源拉流支持两种协议rtmp和flv,根据配置参数创建对应的拉流对象
srs_error_t SrsEdgeIngester::do_cycle()
{while (true) {if ((err = trd->pull()) != srs_success) {return srs_error_wrap(err, "do cycle pull");}// Use protocol in config.string edge_protocol = _srs_config->get_vhost_edge_protocol(req->vhost);// If follow client protocol, change to protocol of client.bool follow_client = _srs_config->get_vhost_edge_follow_client(req->vhost);if (follow_client && !req->protocol.empty()) {edge_protocol = req->protocol;}// Create object by protocol.srs_freep(upstream);//根据边缘协议创建对应的拉流类if (edge_protocol == "flv" || edge_protocol == "flvs") {upstream = new SrsEdgeFlvUpstream(edge_protocol == "flv"? "http" : "https");} else {upstream = new SrsEdgeRtmpUpstream(redirect);}if ((err = source->on_source_id_changed(_srs_context->get_id())) != srs_success) {return srs_error_wrap(err, "on source id changed");}//边缘服务连接源站服务,一般源站会部署多个节点,边缘选取源站节点时也是通过RoundRobin算法选取//其中一个节点进行拉流//这里需要注意一点,如果负载到一台没有流的源站节点上怎么办?//其实如果发现连接的源站没有流,会触发302 redirect重连逻辑if ((err = upstream->connect(req, lb)) != srs_success) {return srs_error_wrap(err, "connect upstream");}if ((err = edge->on_ingest_play()) != srs_success) {return srs_error_wrap(err, "notify edge play");}// set to larger timeout to read av data from origin.upstream->set_recv_timeout(SRS_EDGE_INGESTER_TIMEOUT);//拉流处理函数err = ingest(redirect);if (srs_is_client_gracefully_close(err)) {srs_warn("origin disconnected, retry, error %s", srs_error_desc(err).c_str());srs_error_reset(err);}break;}}拉流源站没有流触发302
边缘服务通过负载均衡获取源站节点 ,然后去源站拉流,如果当前源站节点没有流,会触发320 redirect 重定向另一台。srs目前会重试三次,如果三次之后还是拉不到流,就认为失败了
srs_error_t SrsEdgeFlvUpstream::do_connect(SrsRequest* r, SrsLbRoundRobin* lb, int redirect_depth)
{//第一次连接源站节点时 redirect_depth = 0,通过lb->select负载均衡随机选择一台//如果连接的源站没有流,触发302,再连接另一台if (redirect_depth == 0) {SrsConfDirective* conf = _srs_config->get_vhost_edge_origin(req->vhost);// @see https://github.com/ossrs/srs/issues/79// when origin is error, for instance, server is shutdown,// then user remove the vhost then reload, the conf is empty.if (!conf) {return srs_error_new(ERROR_EDGE_VHOST_REMOVED, "vhost %s removed", req->vhost.c_str());}// select the origin.std::string server = lb->select(conf->args);int port = SRS_DEFAULT_HTTP_PORT;if (schema_ == "https") {port = SRS_DEFAULT_HTTPS_PORT;}srs_parse_hostport(server, server, port);// Remember the current selected server.selected_ip = server;selected_port = port;} else {// If HTTP redirect, use the server in location.schema_ = req->schema;selected_ip = req->host;selected_port = req->port;}sdk_ = new SrsHttpClient();if ((err = sdk_->initialize(schema_, selected_ip, selected_port, cto)) != srs_success) {return srs_error_wrap(err, "edge pull %s failed, cto=%dms.", url.c_str(), srsu2msi(cto));}if ((err = sdk_->get(path, "", &hr_)) != srs_success) {return srs_error_wrap(err, "edge get %s failed, path=%s", url.c_str(), path.c_str());}if (hr_->status_code() == 404) {return srs_error_new(ERROR_RTMP_STREAM_NOT_FOUND, "Connect to %s, status=%d", url.c_str(), hr_->status_code());}if ((err = sdk_->get(path, "", &hr_)) != srs_success) {return srs_error_wrap(err, "edge get %s failed, path=%s", url.c_str(), path.c_str());}if (hr_->status_code() == 404) {return srs_error_new(ERROR_RTMP_STREAM_NOT_FOUND, "Connect to %s, status=%d", url.c_str(), hr_->status_code());}//如果状态码为302,开启重连另一台逻辑string location;if (hr_->status_code() == 302) {//获取302返回的地址location = hr_->header()->get("Location");}srs_trace("Edge: Connect to %s ok, status=%d, location=%s", url.c_str(), hr_->status_code(), location.c_str());if (hr_->status_code() == 302) {//最多重试三次if (redirect_depth >= 3) {return srs_error_new(ERROR_HTTP_302_INVALID, "redirect to %s fail, depth=%d", location.c_str(), redirect_depth);}string app;string stream_name;if (true) {string tcUrl;srs_parse_rtmp_url(location, tcUrl, stream_name);int port;string schema, host, vhost, param;srs_discovery_tc_url(tcUrl, schema, host, vhost, app, stream_name, port, param);r->schema = schema; r->host = host; r->port = port;r->app = app; r->stream = stream_name; r->param = param;}//重连return do_connect(r, lb, redirect_depth + 1);}
}回源拉流的逻辑
边缘节点连接源站成功后,即找到有流的源站,然后就开始通过upstream进行拉流
srs_error_t SrsEdgeIngester::ingest(string& redirect)
{while (true) {if ((err = trd->pull()) != srs_success) {return srs_error_wrap(err, "thread quit");}pprint->elapse();// pithy printif (pprint->can_print()) {upstream->kbps_sample(SRS_CONSTS_LOG_EDGE_PLAY, pprint->age());}// read from client.SrsCommonMessage* msg = NULL;//upstream拉流if ((err = upstream->recv_message(&msg)) != srs_success) {return srs_error_wrap(err, "recv message");}srs_assert(msg);SrsAutoFree(SrsCommonMessage, msg);//处理拉到的流if ((err = process_publish_message(msg, redirect)) != srs_success) {return srs_error_wrap(err, "process message");}}
}处理拉到的流,拉到流后和普通单节点就一样了,把流转给 SrsLiveSource ,然后再转给对应的consumer
srs_error_t SrsEdgeIngester::process_publish_message(SrsCommonMessage* msg, string& redirect)
{srs_error_t err = srs_success;// process audio packetif (msg->header.is_audio()) {if ((err = source->on_audio(msg)) != srs_success) {return srs_error_wrap(err, "source consume audio");}}// process video packetif (msg->header.is_video()) {if ((err = source->on_video(msg)) != srs_success) {return srs_error_wrap(err, "source consume video");}}}这篇关于srs集群下行edge处理逻辑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





