本文主要是介绍【虹科案例】虹科高速数字化仪在光探测和测距 (LIDAR) 系统中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言

50 多年前激光技术的发展催生了光探测和测距 (LIDAR) 系统,该系统在距离计算方式上取得了突破。LIDAR 的原理与雷达使用的原理非常相似。主要区别在于雷达系统检测物体反射的无线电波,而激光雷达使用激光信号。这两种技术通常采用相同类型的飞行时间方法来确定物体的距离。然而,由于激光的波长比无线电波的波长短得多,因此激光雷达系统可提供卓越的测量精度。激光雷达系统还可以检查反射光的其他属性,例如频率内容或偏振,以揭示有关物体的其他信息。
激光雷达系统现在被用于越来越多的应用领域。这包括但不限于自动驾驶、地质和地理测绘、地震学、气象学、大气物理学、监视、测高、林业、导航、车辆跟踪、测量和环境保护。
激光雷达配置
为了匹配许多不同的应用,激光雷达系统有多种设计和配置。每个系统都需要合适的光电传感器和合适的数据采集电子设备。光检测系统要么是非相干的,其中直接能量通过反射信号的幅度变化来测量,要么是相干的,其中反射信号的频率偏移,例如由多普勒效应引起的偏移,或其相位被观察到。类似地,光源可以是低功率微脉冲设计,其中传输间歇性脉冲序列,也可以是高能量设计。微脉冲系统非常适合“人眼安全”操作必不可少的应用(例如测量和地面车辆跟踪),而高能系统通常部署在会遇到长距离和低水平反射的地方 (如大气物理学和气象学研究)。
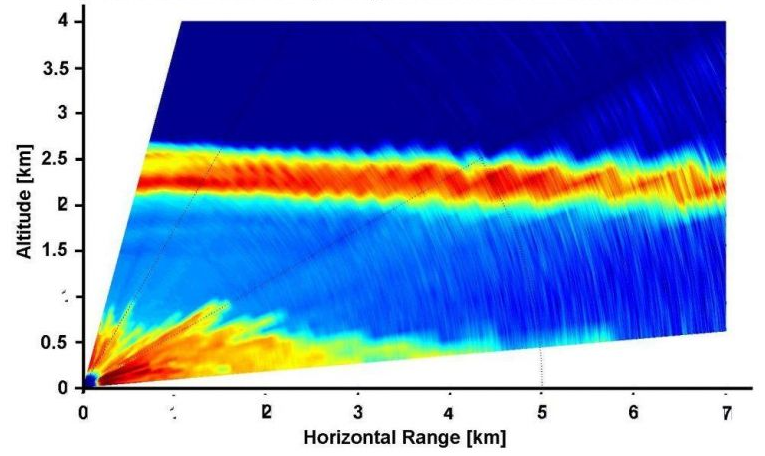
大气激光雷达扫描
每个激光雷达系统都需要使用合适的传感器来检测反射的激光信号并将其转换为电信号。最常见的传感器类型是光电倍增管 (PMT) 和固态光电探测器(例如光电二极管)。通常,PMT 用于使用可见光的应用,而光电二极管在红外系统中更为常见。然而,这两种传感器类型都被广泛使用,选择在很大程度上取决于需要检测的光特性、所需的性能水平和成本。
最重要的是,传感器会产生需要采集和分析的快速电信号。对于大多数 LIDAR 应用,最流行的信号捕获卡类型是 PCIe,因为这使它们能够直接安装在大多数现代 PC 中。 PCIe 是许多数字化仪供应商提供的一种类型,这是创建功能强大、易于使用的数据采集系统的简单方法。 由于 PCIe 总线提供非常高的数据吞吐率,信号采集、数据传输和分析功能通常比其他更传统的采集系统快得多。 虹科Spectrum还提供其他的行业标准,例如 digitizerNETBOX,一种基于 LXI/以太网的紧凑型设备或 PXIe,它们是具有空间限制或振动问题的移动环境(例如机载或移动 LIDAR)的不错选择。
激光雷达性能等级
对于 LIDAR 应用,存在三个独立的性能等级:
01对于最快的光脉冲
为了捕获和分析非常快的信号,采集卡需要高达 10 GS/s 的采样率和超过 1 GHz 的高带宽。此类数字化仪的一个示例是虹科M5i.33xx 系列,它在 PCIe 平台上为每张卡提供多达 2 个通道,具有 12 位分辨率和高达 6.4 GS/s 的采样率。虹科M4i.22xx 系列在 PCIe 和 PXIe 平台上为每张卡提供多达 4 个通道,在 LXI 平台上提供多达 24 个通道。这种组合使这些卡非常适合与产生纳秒甚至亚纳秒范围内的脉冲的快速传感器一起使用。 此外,5 GS/s 的快速采样率可实现亚纳秒分辨率的定时测量。它非常适用于需要检测和测量小频移的情况,例如由多普勒效应产生的频移。

虹科 M4i.22xx 系列
02适用于低电平信号和高灵敏度
当需要宽信号动态范围和非常高的灵敏度时,采集卡需要能够以几百 MS/s 的采样率和匹配的带宽采集幅度降至毫伏范围的信号。垂直分辨率要高,最好是16位。一个示例是 虹科 M4i.44xx 系列,在 500 MS/s 时具有 14 位分辨率或在 250 MS/s 时具有 16 位分辨率。这些装置还具有从 ±200 mV 到 ±10 V 的可编程满量程增益范围,使其适用于需要观察和测量低电平信号和小幅度变化的应用。

虹科 M4i.44xx 系列
03具有成本效益的中档性能
第三组适用于需要高灵敏度但对时序要求不高的应用。高达 100 MS/s 的采样率和 16 位垂直分辨率,如虹科M2p.59xx 系列产品,适合该应用领域。这些装置用于需要高信号灵敏度的远程 LIDAR 应用,也用于需要高密度、多通道记录的情况。

虹科M2p.59xx 系列
激光雷达应用中需要满足的高级功能
数字化仪包括多种不同的采集模式,可有效使用数字化仪的板载内存并提供超快触发功能,因此不会遗漏任何重要事件。这些模式包括多采集和门控采集,带有时间戳、FIFO 流或基于 FPGA 的高速块平均
如何处理海量数据?
第一种方法只是将数据发送到主机 PC 的 CPU。这种传统方法提供了一种简单的解决方案。用户可以根据供应商的API编写自己的分析程序,也可以使用第三方测量软件,如虹科SBench 6、MATLAB和LabVIEW。整体性能和测量速度随后受到 CPU 可用资源的限制。在要求苛刻的应用程序中,这是一个问题,因为 CPU 与 PC 系统的其余部分共享其处理能力,并控制数据传输。
第二种方法使用 FPGA 技术——现场可编程门阵列。 这是一个强大的解决方案,但它的成本和复杂性要高得多。大型 FPGA 价格昂贵,并且创建自定义固件需要数字化仪的 FDK、FPGA 供应商提供的工具以及专门的硬件编程工程技能。创建固件并不适合所有人,即使是经验丰富的开发人员也会陷入漫长的开发周期。此外,该解决方案受到实际位于数字化仪上的 FPGA 的限制。例如,如果可用的块 RAM 已用完,则无能为力。

激光雷达数字化仪到 GPU
第三种方法是SCAPP。它由虹科 Spectrum创建,是一种新方法。SCAPP使用基于 Nvidia 的 CUDA 标准的标准现成 GPU(图形处理器单元)。GPU 直接与数字化仪连接,无需 CPU 交互。这开启了GPU用于信号处理的巨大并行核心架构,拥有数百甚至数千个处理核心、数GB的内存和高达12 Tera-FLOP的计算速度。CUDA 卡的结构非常适合分析,因为它专为并行数据处理而设计。这使其成为数据转换、数字滤波、平均、基线抑制、FFT 窗口函数甚至 FFT 本身等任务的理想选择,因为它们很容易并行处理。例如,具有 1k 内核和 3.0 Tera-FLOP 计算速度的小型 GPU 已经能够在 FFT 块大小为 512k 的两个通道上以每秒 500 兆样本的速度进行连续数据转换、多路复用、窗口化、FFT 和平均,并且它 可以运行几个小时。
将 SCAPP 方法与基于 FPGA 的解决方案进行比较,揭示了总体拥有成本的巨大节省。所需要的只是匹配的 CUDA GPU 和软件开发工具包。但是,最大的成本节省是项目开发时间。用户无需花费数周时间试图了解供应商的 FDK、FPGA 固件的结构、FPGA 设计套件和仿真工具,而是可以立即开始使用以易于理解的 C 代码编写的示例并使用通用设计工具。
这篇关于【虹科案例】虹科高速数字化仪在光探测和测距 (LIDAR) 系统中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






