本文主要是介绍语音处理——Pyannote使用学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 引言
- 正文
- Pyannote的介绍
- Pyannote安装
- Pyannote使用
- 问题总结
- SSLError
- 总结
引言
-
在进行AD检测的模型中,原来使用的是whisper进行的语音转换,但是whisper只能实现ASR任务,并不能检测出不同说话者,所以需要学习一下SpeechBrain,实现说话者检测和情绪分类等不同的语音任务,以进一步完善当前的任务。
-
这里发现SpeechBrain实现起来比较费劲,自由度比较高,并不能拿来直接用。后来还是换成了pyannote,但是这中间也经过了很多异常情况。这里写一篇文章,记录一下整体过程。
-
出现这么多问题,是因为我的开发ide,pycharm并不能正常地科学上网,即使本地打开了vpn也不行,所以很多东西只能手动下载到本地,然后在一点点配置。
-
最有效的配置就是设置好pycharm的代理工具,使之能够顺利访问huggingface,下载相关的模型,而不是向网上现在说的一些,替换镜像源,这没有任何作用,毕竟有很多工具在国内的镜像上都是没有的。
正文
Pyannote的介绍
-
这是一个开源的声音处理工具,已经广泛应用于很多公司的生产中,除此之外,这个模型的性能也很棒。这个模型可以干如下一些任务:
- 话者变化检测(Speaker Change Detection)
自动检测音频流中说话者变化的时刻。这对于后续的说话者分割和识别任务至关重要。 - 说话者嵌入(Speaker Embedding)
提取说话者的声音特征表示,这些特征可以用于比较和识别不同说话者的身份。 - 说话者识别(Speaker Identification)
确定音频中说话者的身份,通常需要一个已知说话者身份的数据库来匹配和识别。 - 说话者验证(Speaker Verification)
确认一个声音样本是否属于某个特定的说话者,常用于生物特征认证系统。 - 声音活动检测(Voice Activity Detection, VAD)
识别音频中的语音段和非语音段,这是处理语音信号的基础步骤之一。 - 重叠说话者检测(Overlapped Speech Detection)
检测音频中存在两个或多个人同时说话的情况,对于会议记录和多人对话分析特别有用。 - 说话者二分化(Diarization)
将音频流分割成不同说话者的语音段,并标识每个段落的说话者。这被广泛应用于会议记录、法庭记录和新闻采访等场景。
- 话者变化检测(Speaker Change Detection)
-
这里只需要使用他的说话者二分化,区分出医生和病人说话的时间段即可。
Pyannote安装
- 安装很简单,直接通过PyPI指令进行安装即可,具体如下。
pip install pyannote.audio
Pyannote使用
- 这里直接访问pyannote对应的huggingface即可,会有相关的使用实例代码
- 链接如下:Speaker Diarization
- 具体使用代码如下
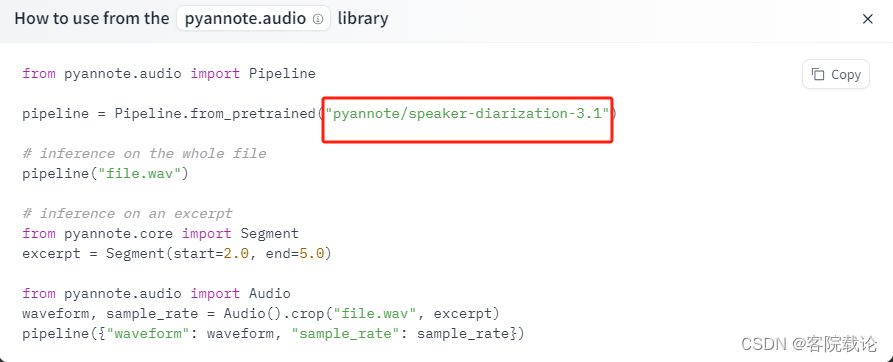
from pyannote.audio import Pipeline
import utils# 创建对应pipeline管道模型,调用预训练模型,这里是指定了调用模型的相关路径。
pipeline = Pipeline.from_pretrained(r"F:\FeatureEngineer\pyannote\speaker-diarization-3.0\config.yaml")
# run the pipeline on an audio file
diarization = pipeline("test.wav")# dump the diarization output to disk using RTTM format
with open("audio.rttm", "w") as rttm:diarization.write_rttm(rttm)
- 下述图片为huggingface使用样例的代码截图
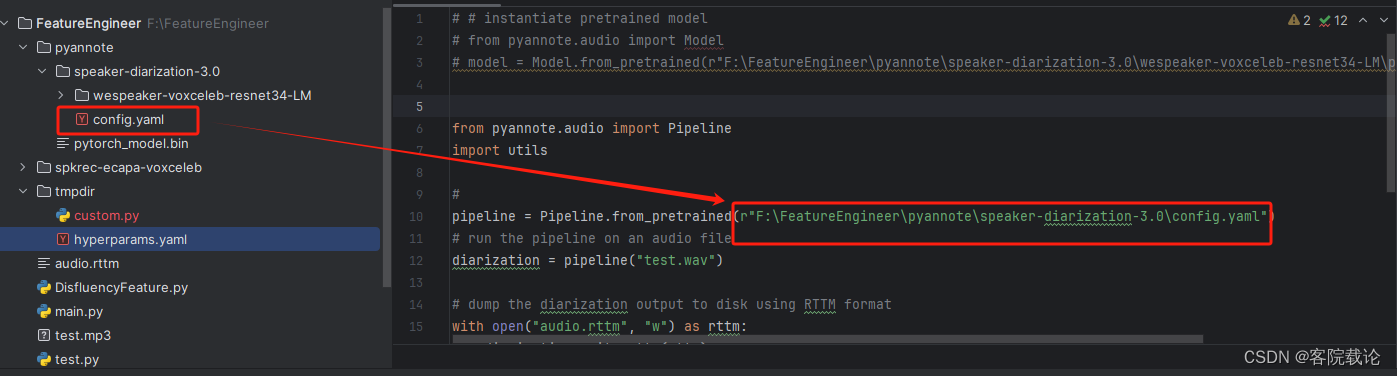
配置文件
- 上图红框为指定的模型的路径,如果不是一个文件,他会默认在远端huggingface仓库中下载对应的模型,需要能够访问huggingface网站,否则还是推荐将相关模型下载到本地。
- 这里给出对应的配置文件路径——config.yaml文件
version: 3.0.0pipeline:name: pyannote.audio.pipelines.SpeakerDiarizationparams:clustering: AgglomerativeClusteringembedding: hbredin/wespeaker-voxceleb-resnet34-LM # 提取embedding的网络模型路径
# embedding: F:\FeatureEngineer\pyannote\speaker-diarization-3.0\wespeaker-voxceleb-resnet34-LM\pytorch_model.bin
# embedding: F:\FeatureEngineer\pyannote\speaker-diarization-3.0\wespeaker-voxceleb-resnet34-LM\speaker-embedding.onnxembedding_batch_size: 32embedding_exclude_overlap: truesegmentation: F:\FeatureEngineer\pyannote\pytorch_model.bin # 提取segmentation的网络模型路径segmentation_batch_size: 32params:clustering:method: centroidmin_cluster_size: 12threshold: 0.7045654963945799segmentation:min_duration_off: 0.0
注意!!
- 一般来说对应网络模型的files and versions都是存放着相关的模型参数文件,直接下载到本地,然后进行访问就行了。但是这个speaker-diarization任务只给出了对应config文件,过程中需要的一些模型,还是会调用相关的网络连接进行下载。具体来说是segmentation和embedding两个关键字对应的模型,这里给出相关的链接,自己下载,并将config.yaml文件中相关参数替换为本地文件。
-
segmentation链接
-
embedding链接
-
将上述两个文件下载后,指定对应的路径即可。

问题总结
SSLError
- 这个需要重新配置网络,不过我试过了很多次,都不行,还是找到了原来的模型,下载到了本地。
总结
- 这个问题我弄了三天,当然有一部分原因是假期,我的工作效率慢,还有一部分是因为我来回换,最终还是使用pyannote。
- 这个和正常的huggingface模型不一样,还需要自己读一下代码,下载相关的模型。
这篇关于语音处理——Pyannote使用学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




