本文主要是介绍实例分析AnnexB格式h264流startcode,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们知道,h264 流格式有两种:avcC与AnnexB。
avcC 就是在 NALU 前面写上几个字节,这几个字节组成一个整数(大端字节序)这个整数表示了整个 NALU 的长度。在读取的时候,先把这个整数读出来,拿到这个 NALU 的长度,然后按照长度读取整个 NALU,我们不妨把这几个字节叫做NALU Body Length。
AnnexB 就是在一个 NALU 前面加上三个或者四个字节,这些字节的内容是 0 0 0 1 或者 0 0 1。当我们读取一个 H264 流的时候,一旦遇到 0 0 0 1 或者 0 0 1,我们就认为一个新的 NALU 开始了,因此,这些用来做分隔符的字节,一般也被称为 start code。
所以,接下来重点分析下startcode。
startcode的有两种形式
3字节的0x000001和4字节的0x00000001
为什么需要startcode?
主要是为了将相邻两个NALU划分开,让他们有一个界线,方便解码,比如将h264的数据存储在一个文件当中,解码器无法从数据流中分别每个NALU的起始位置。
在编码时,每个NALU前面添加startcode(占4字节0x00000001或者3字节0x000001),这里有人会想到万一中间出现0x000001怎么办呢,h264有个防止竞争的机制,在编码完一个NAL时,如果出现有连续两个0x00字节,就在后面插入一个0x03(解码的时候这个0x03会被丢弃)。
startcode占4字节还是3字节?
实际上startcode只占3字节,4字节的startcode = zero_byte + start_code_prefix_one_3bytes,就是说无论啥时候其实startcode都是3字节,关键就在于zero_byte。
- 包含SPS,PPS的NALU前面要加
zero_byte(4字节)。 - 当一帧被分为多个slice时,首个NALU前面要加
zero_byte(4字节)。也就是,当一个完整的帧被编为多个slice的时候,除掉第一个NALU,剩下的都用3字节的,其余的都是4字节,这个在后面的实例分析中可以得到验证。
比如给定一组frame:
SPS (4字节头)
PPS (4字节头)
SEI (4字节头)
I0(slice0) (4字节头)
I0(slice1) (3字节头)
P1(slice0) (4字节头)
P1(slice1) (3字节头)
P2(slice0) (4字节头)
P2(slice1) (3字节头)
- I0(slice0)是序列第一帧(I帧)的第一个slice,是当前Access Unit的首个nalu,所以是4字节头。而I0(slice1)表示第一帧的第二个slice,所以是3字节头。
- P1(slice0) 、P1(slice1)同理。
h264stream文件实例分析
0x00000000的地址开始是SPS,这时候startcode是0x00000001,4个字节
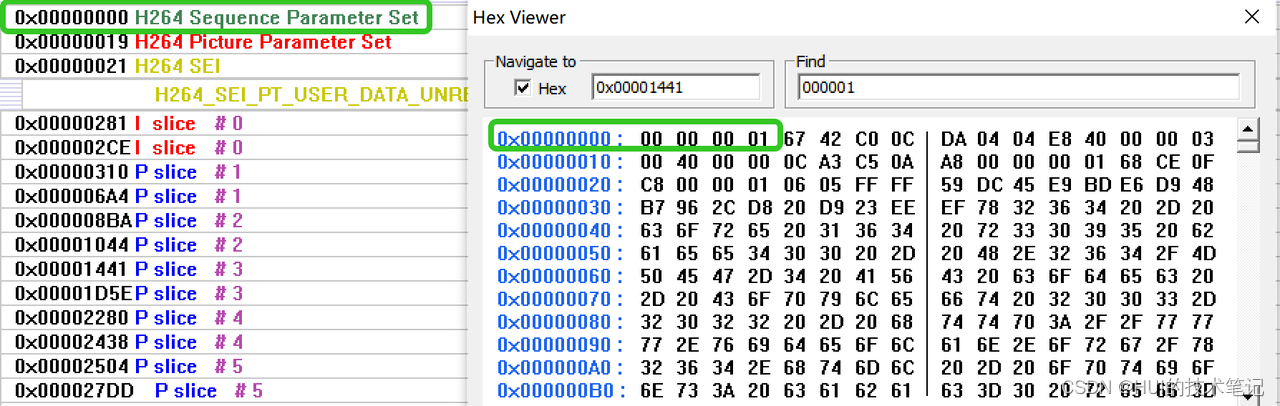
0x00000019的地址开始是PPS,这时候startcode是0x00000001,4个字节
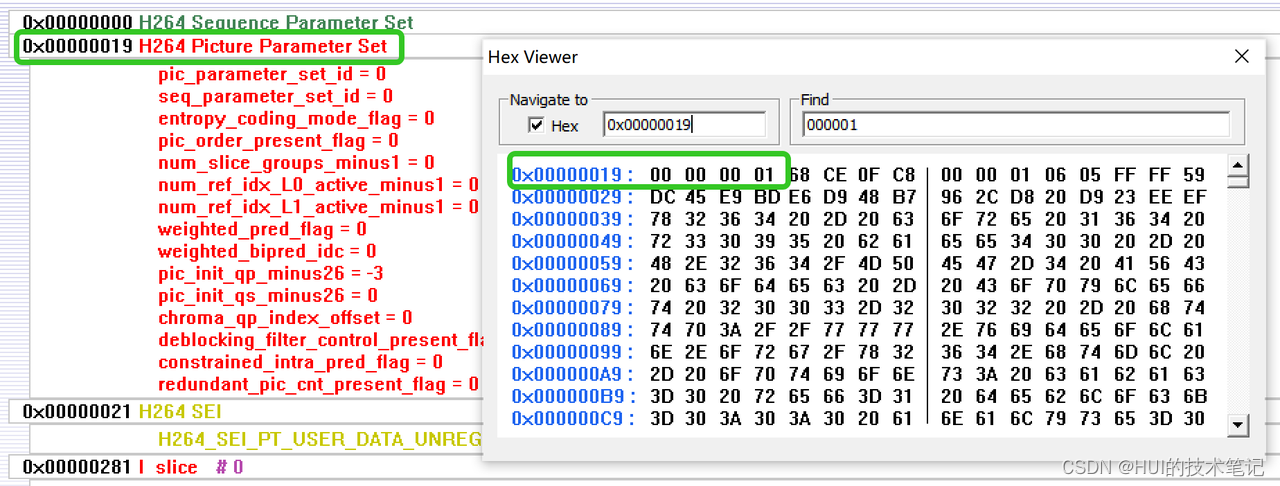
0x00000021的地址开始是SEI,这时候startcode是0x000001,3个字节
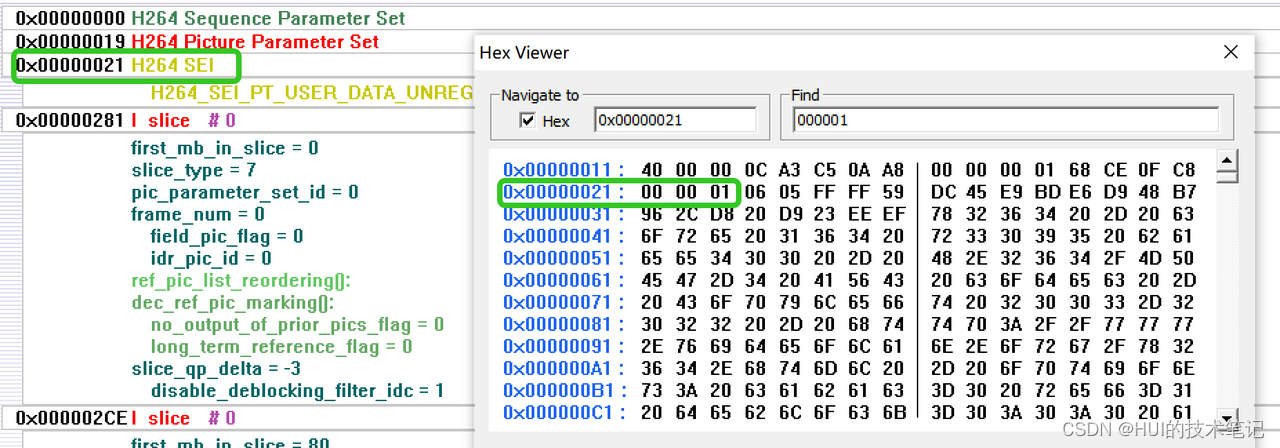
0x00000281的地址开始是第一个I帧的slice 0,这时候startcode是0x000001,3个字节
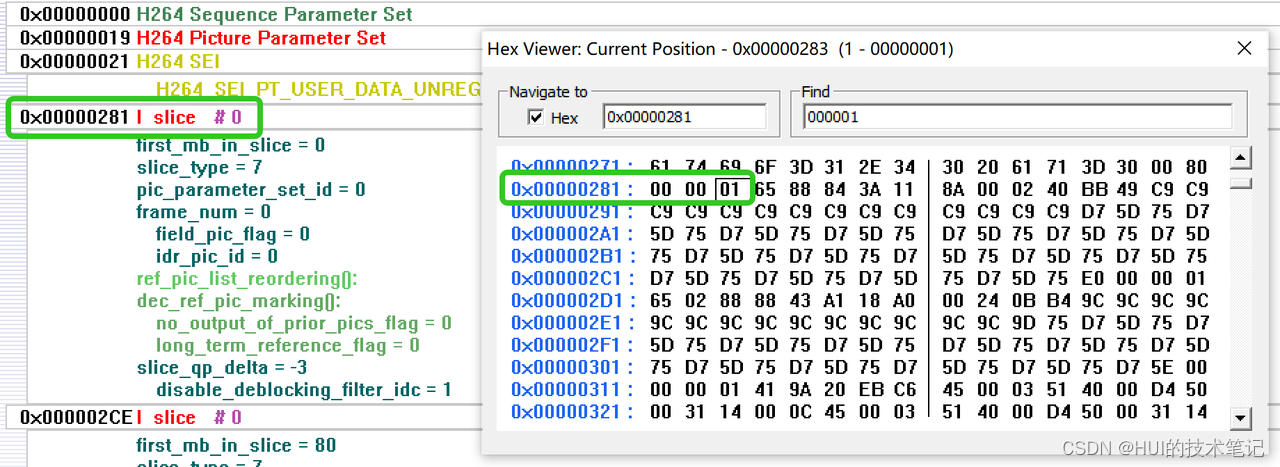
0x000002CE的地址开始是第一个I帧的slice 1,这时候startcode是0x00000001,3个字节
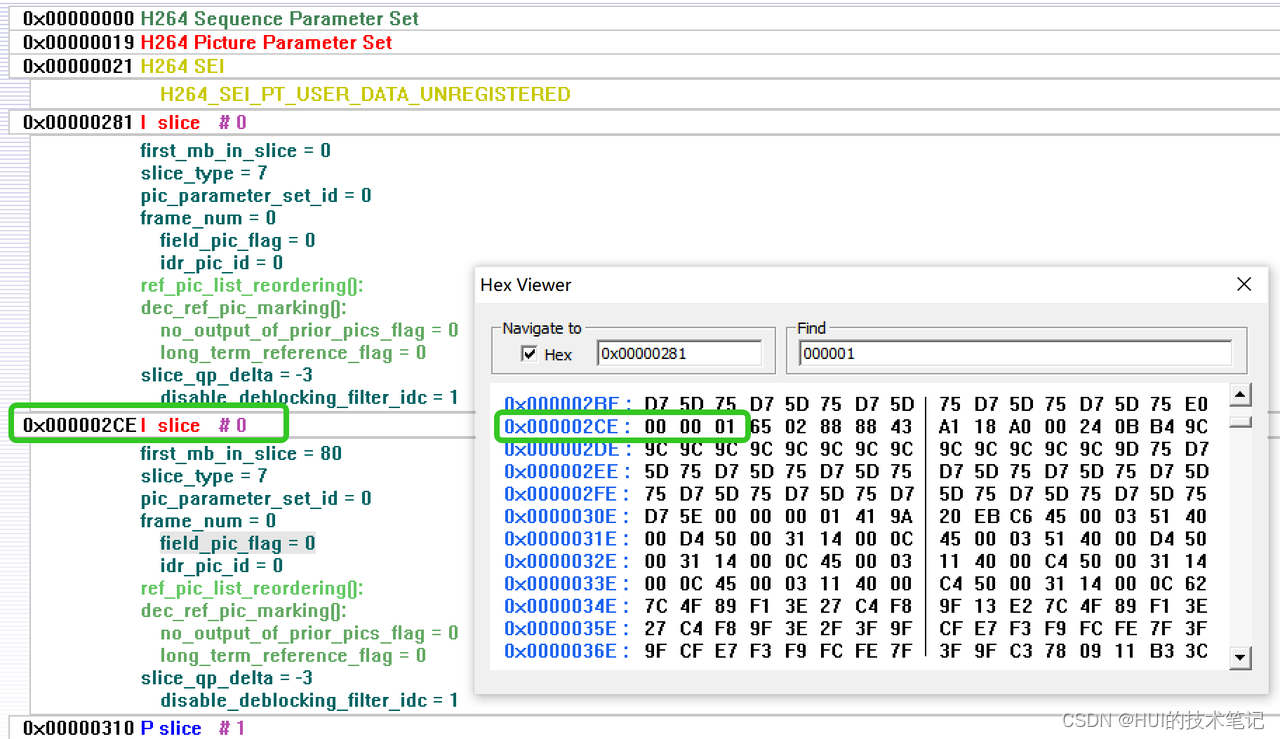
0x00000310的地址开始是接着的P帧的slice 0,这时候startcode是0x0000000001,4个字节
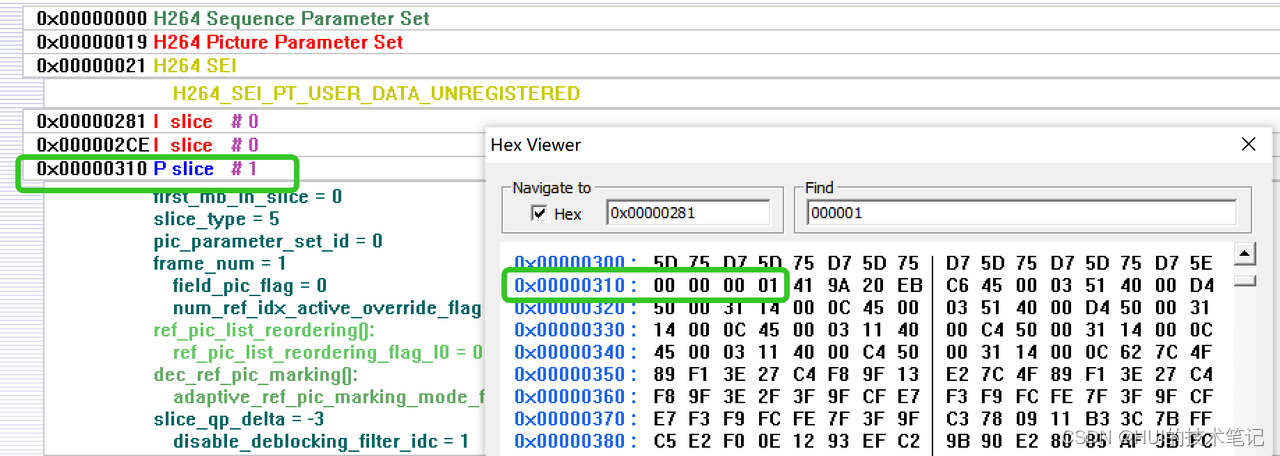
0x000006A4的地址开始是接着的P帧的slice 1,这时候startcode是0x00000001,3个字节
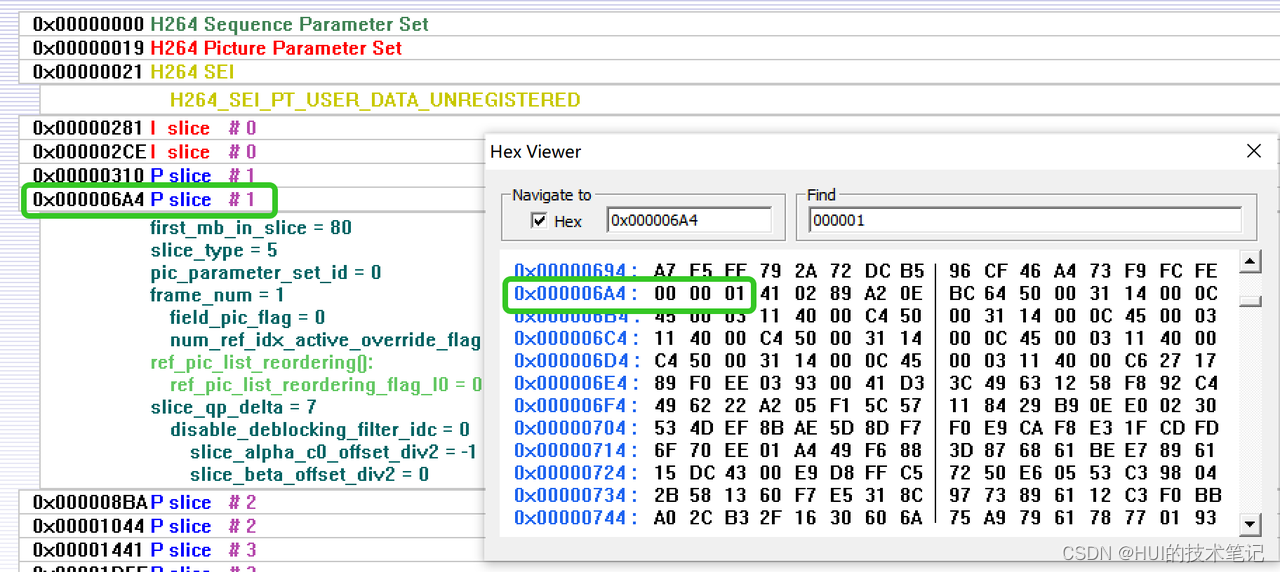
0x000008BA的地址开始是接着的下一个P帧的slice 0,这时候startcode是0x0000000001,4个字节
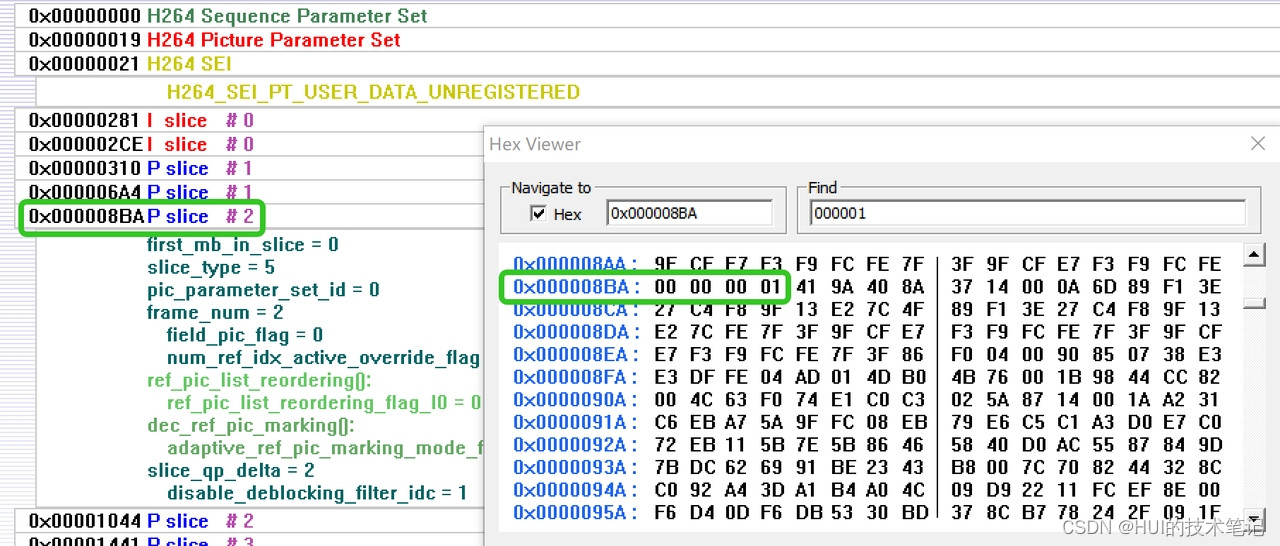
依次往后分析,每一个完整的帧开始的时候startcode都是4个字节的startcode,每个帧的slice使用3个字节的startcode分隔。
对比ffprobe生成信息
ffprobe生成frame信息文件videoframes.info:
ffprobe -show_frames -select_streams v -of xml 256x144.h264 > videoframes.info
简化这个xml文件内容后如下:
<?xml version="1.0" encoding="UTF-8"?>
<ffprobe><frames><frame pkt_pos="0" pkt_size="784" pict_type="I"><side_data_list><side_data side_data_type="H.26[45] User Data Unregistered SEI message"/></side_data_list></frame><frame pkt_pos="784" pkt_size="1450" pict_type="P" coded_picture_number="1" /><frame pkt_pos="2234" pkt_size="2951" pict_type="P" coded_picture_number="2" /><frame pkt_pos="5185" pkt_size="3647" pict_type="P" coded_picture_number="3" /><frame pkt_pos="8832" pkt_size="644" pict_type="P" coded_picture_number="4" /><frame pkt_pos="9476" pkt_size="952" pict_type="P" coded_picture_number="5" /><frame pkt_pos="10428" pkt_size="981" pict_type="P" coded_picture_number="6" /><frame pkt_pos="11409" pkt_size="678" pict_type="P" coded_picture_number="7" /><frame pkt_pos="12087" pkt_size="1003" pict_type="P" coded_picture_number="8" /><frame pkt_pos="13090" pkt_size="415" pict_type="P" coded_picture_number="9" /><frame pkt_pos="13505" pkt_size="772" pict_type="P" coded_picture_number="10"/><frame pkt_pos="14277" pkt_size="799" pict_type="P" coded_picture_number="11"/><frame pkt_pos="15076" pkt_size="424" pict_type="P" coded_picture_number="12"/><frame pkt_pos="15500" pkt_size="466" pict_type="P" coded_picture_number="13"/><frame pkt_pos="15966" pkt_size="745" pict_type="P" coded_picture_number="14"/></frames>
</ffprobe>
从这个结果对比后面的代码分析,ffprobe拿到的frame 0的信息,packet size是784,刚好是从起始地址到I帧结束的大小,0x00000310换算成10进制就是784,对比流的16进制和后面代码对stream的解析来看,ffprobe给出的信息第一个frame的实际上包含了SPS,PPS,SEI,I帧数据,在SPS和PPS前面的startcode是4个字节,而后面的程序解析,frame#0是SPS,frame#1是包含PPS和SEI的I帧。

代码解析startcode
后面的这段代码解析前面的h264stream文件,然后打印每一个frame的大小,通过输出信息来看,和前面的xml统计信息符合,区别就是Frame 0和Frame 1的输出分别是SPS和PPS的4个字节的startcode开始的帧,这个和前面用工具分析的截图完全一致。
Frame 0: 25 bytes
Frame 1: 759 bytes
Frame 2: 1450 bytes
Frame 3: 2951 bytes
Frame 4: 3647 bytes
Frame 5: 644 bytes
Frame 6: 952 bytes
Frame 7: 981 bytes
Frame 8: 678 bytes
Frame 9: 1003 bytes
Frame 10: 415 bytes
Frame 11: 772 bytes
Frame 12: 799 bytes
Frame 13: 424 bytes
Frame 14: 466 bytes
#include <stdint.h>
#include <stdio.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define START_CODE_PREFIX_LENGTH 3
#define START_CODE_LENGTH 4int main(int argc, char *argv[])
{FILE *fp = fopen(argv[1], "rb");if (!fp) {printf("Failed to open file\n");return -1;}// Allocate buffer for reading fileint buffer_size = 1024 * 1024;uint8_t *buffer = (uint8_t *)malloc(buffer_size);// Allocate buffer for storing frame dataint frame_size = buffer_size;uint8_t *frame = (uint8_t *)malloc(frame_size);int frame_count = 0;int bytes_read = 0;int frame_start = 0;int frame_end = 0;int frame_length = 0;int start_code_prefix_found = 0;while ((bytes_read = fread(buffer, 1, buffer_size, fp)) > 0){for (int i = 0; i < bytes_read; i++) {if (!start_code_prefix_found) {/** 这里用001来判断的好处是,当发现后面的四个字节是0001的时候,说明frame结* 束,这时候buffer[i]的位置已经是下一个0001的0位置,下次循环进来的时候* buffer指向的位置刚好是001,因为有i++运算,已经去掉了前导0* (leading_zero_8bits)** 如果是0001,那么经过i++,start_code_prefix_found的位置就是下下一个* startcode的位置了。*/if (i < bytes_read - START_CODE_PREFIX_LENGTH) {if (buffer[i] == 0x00 &&buffer[i+1] == 0x00 &&buffer[i+2] == 0x01) {start_code_prefix_found = 1;frame_start = i + START_CODE_PREFIX_LENGTH;}}} else {if (i < bytes_read - START_CODE_LENGTH) {if (buffer[i] == 0x00 &&buffer[i+1] == 0x00 &&buffer[i+2] == 0x00 &&buffer[i+3] == 0x01) {start_code_prefix_found = 0;frame_end = i;frame_length = frame_end - frame_start;if (frame_length > frame_size) {frame_size = frame_length;frame = (uint8_t *)realloc(frame, frame_size);}memcpy(frame, buffer + frame_start, frame_length);printf("Frame %d: %d bytes\n", frame_count++, frame_length + START_CODE_LENGTH);}} else if (i == bytes_read-1) {frame_length = bytes_read - frame_start;memcpy(frame, buffer + frame_start, frame_length);printf("Frame %d: %d bytes\n", frame_count++, frame_length + START_CODE_LENGTH);}}}}fclose(fp);free(buffer);free(frame);return 0;
}
这篇关于实例分析AnnexB格式h264流startcode的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








