本文主要是介绍Elasticsearch:创建自定义 ES Rally tracks 的分步指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Alejandro Sánchez
按照这个综合教程学习如何制作个性化的 Rally tracks
ES Rally 是什么?它的用途是什么?
ES Rally 是一个用于在 Elasticsearch® 上测试性能的工具,允许你运行和记录比较测试。
做出决策可能很困难,尤其是当你没有所需的信息并且只能根据过去积极或消极的变化进行猜测或经验时。
如果我们补充一点,数据世界必须是灵活的,因为它发展迅速,因此我们的 Elasticsearch 必须适应它,这个工具将帮助我们能够衡量我们随着时间的推移所做的所有变化和演变,并评估它们的影响 。 最重要的是,我们可以获得做出正确决策所需的信息。
使用 ES Rally
ES Rally 附带了几条开箱即用的 “tracks”。 track 描述一个或多个性能测试场景。
在许多情况下,这些测试可用于评估不同版本的 Elasticsearch 或底层硬件,以及已部署的集群。 然而,在这种特殊情况下,请务必记住,如果集群已经运行并提供流量,则由于并行使用会影响结果,因此指标可能不准确。 然而,给定的值仍然可以用于以后的评估和比较。
此时,你可能想知道是否可以使用 Elasticsearch 集群中已有的自己的数据集。 答案是肯定的。 并非所有优化或改进都只发生在 Elasticsearch 中。 它也可以在数据模型中完成,无论它是不断发展的还是你根据数据使用方式看到的改进。 你可以使用 ES Rally 来衡量这些更改的影响。 接下来我们将展示如何创建你自己的 “track”。
使用你的数据创建你自己的 track
首先,我们来看看先决条件。 ES Rally 可以通过多种方式安装,但以我的拙见,如果我们使用容器发行版,我们将节省时间并使事情变得简单。
另一方面,我们应该考虑磁盘空间。 ES Rally 将下载你指定其下载的索引,因此,如果你正在考虑下载 1TB 索引,则需要牢记这一点。 在这一点上,数据大小确实很重要 —— 俗话说,“不多也不少” —— 所以定义一个有代表性的数据大小很重要。 如果它太小,摄取速度指标可能不具有代表性,但如果它太大,track 的创建时间将会很长。
为此准备数据的一种方法是使用 Elasticsearch Reindex API 和 max_docs 参数来创建一个索引,该索引的大小适合稍后运行的测试。
比如:

Reindex 索引过程可能需要 30 秒以上,因此建议使用 wait_for_completion=false 选项启动它。 这将返回一个任务 ID,你可以使用该 ID 来跟踪流程的进度和完成情况。
注意:目前,ES Rally 在创建自定义赛道时是单线程的。 这是为了避免影响集群或运行任务的计算机的性能。 因此,此过程可能需要一些时间才能完成。 使用 screen 或 tmux 等虚拟终端将允许你在后台运行该进程。
入门
一旦确定了目标索引并且我们确保有足够的空间,让我们开始创建自定义 track(请相应地检查和调整,以避免硬编码密码,我们将使用 read -s 在当时输入它 ):
export loca_path='/path/where/save/esrally'
export user='user'
export track_name='test'
export ssl='true'
export verify_ssl='true'
export indice='test'
export es_host='es:port'
read -s passworddocker run --rm --name esrally \-v ${loca_path}:/rally/.rally/ \elastic/rally create-track \--track=${track_name} \--target-hosts=${es_host} \--client-options="timeout:60,use_ssl:${ssl},verify_certs:${verify_ssl},basic_auth_user:'${user}',basic_auth_password:'${password}'" \--indices="${indice}" \--output-path=/rally/.rally/tracks我们将得到类似于以下内容的输出:

我们可以通过以下方式看到我们创建的自定义 track:
docker run --rm --name esrally \-v ${loca_path}:/rally/.rally/ \elastic/rally info --track-path=/rally/.rally/tracks/${track_name}
我们得到了什么?
我们来看看ES Rally上线后有什么。 这对于了解要适应什么以及如何有目标地运行未来的测试至关重要。
下图显示了 ES Rally 的默认配置、我们执行的执行日志以及我们创建的自定义 track。

- logging.json:这是我们定义事件如何记录在日志文件中的地方。
- logs/rally.log:这是我们执行 ES Rally 的日志被转储的地方。 默认情况下,该文件不会旋转,因此我们可以配置一个外部工具(例如 logrotate)来执行此操作。
- rally.ini:这是定义 ES Rally 配置的文件。
- track/track_name/:这将包含与我们的自定义 track 相关的文件,在这种特殊情况下:
- name-documents-1k.json:前 1,000 个文档
- name-documents-1k.json.bz2:前 1,000 个压缩文档
- name-documents.json:所有文档
- name-documents.json.bz2:所有压缩文档
- name.json:原始索引的定义(映射和设置)
- track.json:自定义 track 的配置(索引、语料库、时间表、challenges)
通常,我们将用来调整 ES Rally 运行的行为和测试的最相关文档是 rally.ini 以及每个自定义 track name.json 和 track.json。
现在我们有了自定义 track,我们该如何使用它呢?
在不深入讨论的情况下,让我们调整我们已经运行的第一个测试,我们将使用该测试作为基线来衡量集群中未来的变化(假设保留变量以正确执行):
docker run --rm --name esrally \-v ${loca_path}:/rally/.rally/ \elastic/rally race \--track-path=~/.rally/tracks/${track_name} \--target-hosts=${es_host} \--pipeline=benchmark-only \--client-options="timeout:60,use_ssl:true,basic_auth_user:'${user}',basic_auth_password:'${password}'"这将为我们提供有关执行的信息,但不用担心,它会被保存以供以后使用。
我们使用 benchmark-only 的 pipeline 类型在已经运行的集群上启动它,这就是为什么我们可以看到警告,告诉我们所采取的不同步骤可能具有误导性的指标,此外还可以看到在 track.json 文件的 “schedule” 部分。

最后,指标部分将向我们显示每个 metric 的值。
注意:可以通过配置 reporting 将指标保存到 Elasticsearch。

[...]

要深入了解每一项,我们必须查看官方文档,其中对每一项都有详细解释。 然而,其中许多都是不言自明的,我们将找到与下面的案例最相关的内容。
改变的时刻
此时,我们已经有了自定义 track,并且已经使用 ES Rally 的默认配置以及该索引的原始映射和设置执行了至少一次。
让我们定义一个用例,数据模型优化。 我之所以特别提出这一点,是因为我在许多部署中看到了性能的显着提高和资源的显着节省,甚至对存储节省等基本资源成本也产生了积极的影响。
我知道这个用例可能是一个 challenge,特别是当我们无法控制数据模型时,因为它来自另一个领域或由外部应用程序管理。 但这将使我们能够将数字转化为性能和成本,从而更有效、更有利地、更优化地使用 Elasticsearch。
我的同事 Mattias Brunnert 撰写了一篇关于分析和优化 Elasticsearch 中的存储的博客文章,你可以在其中看到映射(或数据模型)在这方面的影响的示例。 我想强调的是,最佳的数据模型不仅会节省磁盘空间,还会提高摄取速度和查询速度。
因此,利用我们现在所处的位置,探索以下 api _field_usage_stats,它将向你展示如何使用数据。 例如,你可以从 n 个字段的索引映射中看到你正在使用哪些字段以及你没有使用哪些字段。 在此基础上,你可以定义符合你的需求和实际使用情况的新的、更优化的映射。
好吧,我们已经有了用例,我们分析了数据,并且发现我们可以改进自定义 track 中使用的索引的映射,因此我们继续编辑 name.json 文件以使其适应结果 我们的分析。
我们可以找到类似的内容,其中我们看到默认行为,即在推断文本数据类型时生成文本和关键字字段,但在本例中这显然是不正确的。

因此,我们调整了映射并保存了更改以继续重新运行相同的测试。
我们将得到与前一个类似的输出:

评价时刻
现在我们已经执行了两次自定义 track,区别在于映射的优化,我们将比较结果。
首先,正如我们之前提到的,结果存储在我们赋予它们的持久性中:

在这些 JSON 文件中,我们可以单独看到每个测试获得的结果,但 ES Rally 还允许我们比较执行的执行情况。 为此,我们首先列出执行的执行:
docker run --rm --name esrally -v ${loca_path}:/rally/.rally/ elastic/rally esrally list races
并且通过获取 Race ID,我们将执行以下命令进行比较:
docker run --rm --name esrally -v ${loca_path}:/rally/.rally/ \
elastic/rally esrally compare \
--baseline=ID_WITHOUT_CHANGES \
--contender=ID_WITH_CHANGES这将为我们提供两次执行的比较:
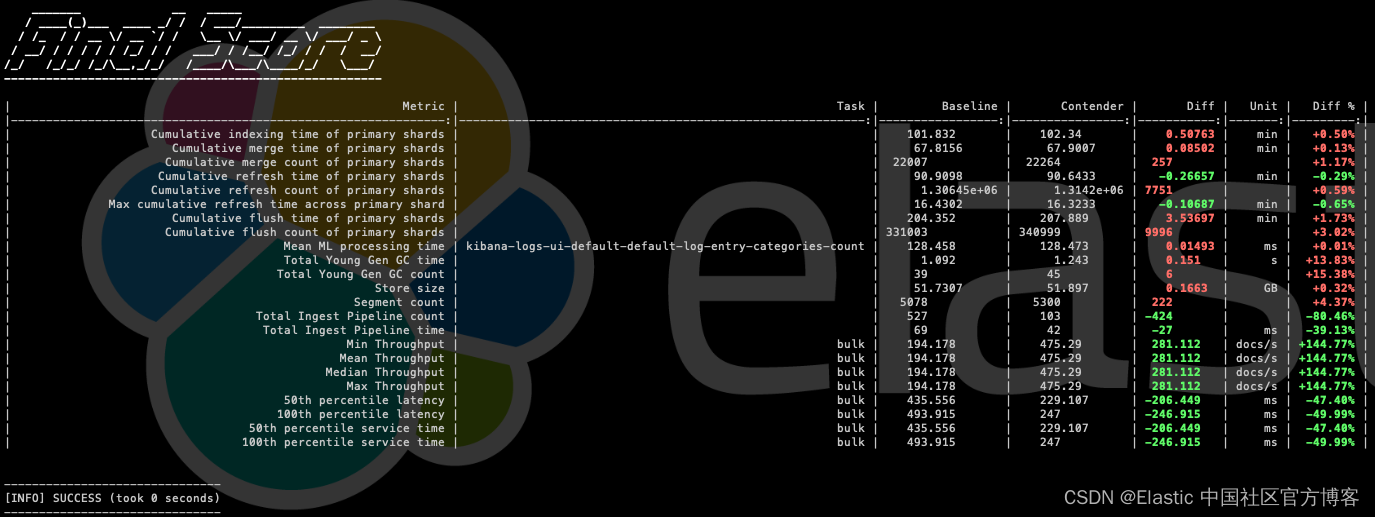
注:这些数据仅供参考,不代表实际值; 它们是在实验室中执行的,数据样本由 100 个文档组成。
使用 ES Rally 优化 Elasticsearch
我们已经了解了如何将 ES Rally 与我们自己的数据集一起使用,如何修改它们以使其适应代表当前或未来情况的场景,以及如何比较和评估它们。 这将帮助我们衡量未来或计划中可能发生的变化,并确定是否会产生积极或消极的影响。 如果我们定期执行负载测试并确定我们距离达到 Elasticsearch 性能的操作或 SLA 限制的程度,那么它对于测量集群的性能也很有用。
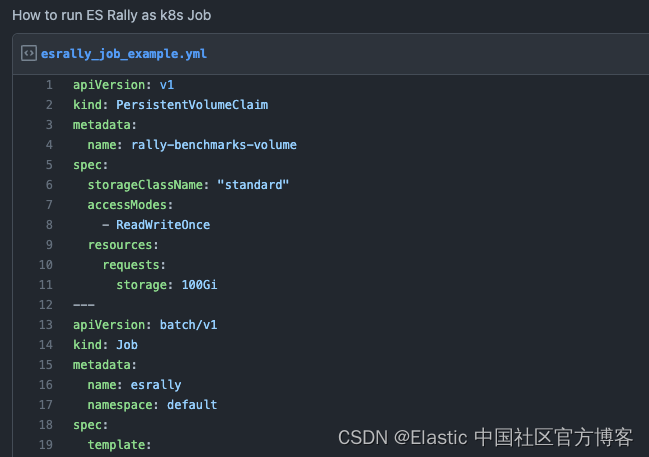
ES Rally 可以通过多种方式进行配置,甚至可以以分布式方式执行,以测试大型 Elasticsearch 环境 - 例如,当执行 ES Rally 的单个节点不够或者出现执行瓶颈时。
尽管我们已经了解了如何从 Docker 运行它,但我还是给你留下了一个如何从 K8s 作为作业运行它的示例作为奖励:
想要了解有关 ES Rally 及其用例的更多信息?
我鼓励你查看官方文档或联系我们的咨询团队,以帮助你以最优化的方式在你的组织中使用它,以增加最大的价值。
请记住,数据是决策的关键。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:A step-by-step guide to creating custom ES Rally tracks | Elastic Blog
这篇关于Elasticsearch:创建自定义 ES Rally tracks 的分步指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




