本文主要是介绍Pulsar-架构与设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Pulsar架构与设计
- 一、背景和起源
- 二、框架概述
- 1.设计特点
- 2.框架适用场景
- 三、架构图
- 1.Broker
- 2.持久化存储(Persistent storage)
- 3.Pulsar元数据(Metadata store)
- 四、功能特性
- 1.消息顺序性
- 2.消息回溯
- 3.消息去重
- 4.消息重投递
- 5.消息重试
- 6.消息TTL
- 7.延迟队列
- 8.重试队列
- 9.死信队列
- 10.消息语义
- 五、设计原理
- 1.消息去重
- 2.消息重试
- 3.延迟队列
- 4.消费订阅模式
- 4.1 独享模式
- 4.2 灾备模式
- 4.3 共享模式
- 4.4 Key共享模式
- 5.生产访问模式
- 5.1 共享模式
- 5.2 独占模式
- 5.3 独占屏蔽模式
- 5.4 等待独占模式
- 总结
- 参考链接
一、背景和起源
随着云原生的兴起,对消息中间件的伸缩性和多租户隔离有了更高的要求。现有的消息中间件不支持多租户的隔离,但是有一定伸缩性,需要一定的迁移工具支持和手工操作。
Pulsar是下一代云原生分布式消息平台,采用存储和计算分离架构设计,支持弹性伸缩,支持多租户、持久化存储、多机房跨区域数据复制。
二、框架概述
1.设计特点
- 下一代云原生分布式消息流平台
- 单实例支持多集群,支持跨机房在集群间消息复制
- 极低的发布延迟和端到端延迟
- 支持超过百万的消息主题。
- 支持多种消息订阅模式(独占、共享和故障转移)
- 由BookKeeper 提供的持久化消息存储机制保证消息传递
- 由轻量级的 serverless 计算框架 Pulsar Functions 实现流原生的数据处理。
- 基于 Pulsar Functions 的 Server less connector 框架 Pulsar IO 使得数据更易移入、移出
Apache Pulsar。 - 支持冷热数据分级存储
2.框架适用场景
- 适用于多租户、云服务场景
- 适用于业务波动比较大、需要弹性伸缩场景
三、架构图
一个Pulsar实例有多个Pulsar Cluster组成,Pulsar Cluster之间可以进行消息复制。
Pulsar Cluster整体架构和组成如下,其中Broker为无状态服务,用于发布和消费消息,BookKeeper用于存储。
- Broker集群:用于处理producer发出的消息;将消息存储到BookKeeper集群;将消息分配给consumer;处理集群协调任务。
- BookKeeper集群:用于消息持久化存储。
- Zookeeper集群:用于处理多个Pulsar集群之间的协调任务。

1.Broker
主要包含以下部分:
- HTTP服务器:主要是提供系统管理接口、topic查找接口
- Dispatcher:异步TCP服务器,用于数据传输
- Managed Ledger:用于缓存从BookKeeper读取的消息
Broker是无状态服务的计算节点;可以通过增加Broker来增加系统的吞吐量;某个Broker节点负载过高,可以将负载迁移到其他Broker节点。
2.持久化存储(Persistent storage)
Pulsar采用BookKeeper作为持久化存储组件。其中Bookie为数据的存储节点,采用分片机制。Bookie支持扩缩容,在扩容过程中不需要将已持久化数据迁移到新存储节点。
3.Pulsar元数据(Metadata store)
Pulsar元数据和BookKeeper元数据可以共享一个Zookeeper集群,也可以使用不同集群。Pulsar使用Zookeeper来进行元数据存储、集群配置和协调。
四、功能特性
1.消息顺序性
可以支持分区顺序性,生产者通过指定的key将消息发送到固定分区,消息订阅模式需要选择独享模式、灾备模式、key共享模式。
2.消息回溯
pulsar默认删除已经被所有Consumer确认消费完成消息,可以通过配置保留已经被消费完成的消息。
3.消息去重
通过服务器设置可以保证消息不会重复持久化存储,保证存储的幂等。
4.消息重投递
消息投递失败,会进行重新投递
5.消息重试
消息消费失败后消息会重新消费
6.消息TTL
支持消息生存期
7.延迟队列
支持任意时间延迟的消息
8.重试队列
重试队列是消费失败后,消息会重新投递到此队列,重试队列按照消费组进行设置的。
9.死信队列
重试次数达到一定次数后,会将消息投递此队列
10.消息语义
支持Exactly Once消息语义,消息确定被写入一次。producer保存发送失败消息再次发送,服务端保证重试多条消息只存储一次。
五、设计原理
1.消息去重
消息去重是指即使消息被Producer多次投递到Broker,也只会被持久化一次。Pulsar可以通过Broker配置开启消息去重功能,不需要应该代码去保证。
实现原理:
- Producer每个消息都有一个递增的唯一SequenceId
- Broker针对每个Producer保存已经接受到的最大SequenceId和已经持久化的最大SequenceId
- Broker接收的消息中SequenceId大于以上SequenceId,则正常处理;如果小于或者等于则为重复消息,直接返回Ack确认
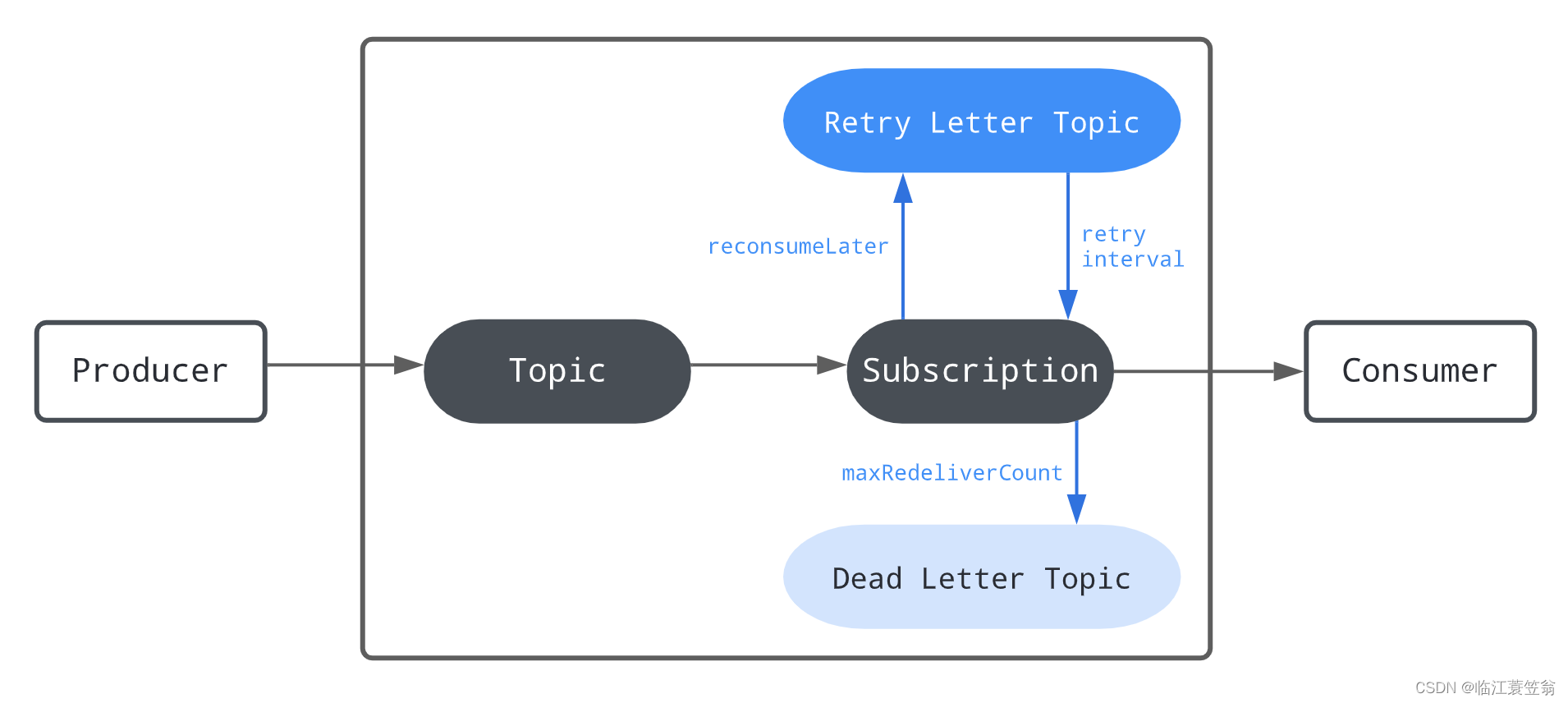
2.消息重试
如果消费组中设置消息主题可以重试,则会(以主题和消费组为度)创建重试队列和死信队列;其中重试队列名称格式为--RETRY;死信队列名称格式为--DLQ;
整体流程为:
- 消费失败后,会将消息作为延迟消息重新投递到重试队列,利用延迟消息特性使Consumer延后一段时间重新消费
- 如果重新投递到重试队列超过一定次数,则会把消息投递到死信队列
3.延迟队列
Broker针对topic每个分区,按照subscription维度维护了DelayedDeliveryTracker优先级队列,队列中以消息的延迟投递时间进行升序排列。
- 延迟消息投递到Broker后,不用特殊处理直接持久化
- 消费时,优先检测DelayedDeliveryTracker是否有消息需要消费(延迟投递时间已到);如有则消费;如果没有则消费正常队列消息
- 消费正常队列消息,如果消息为延迟消息,则需要把消息索引存入到DelayedDeliveryTracker优先级队列
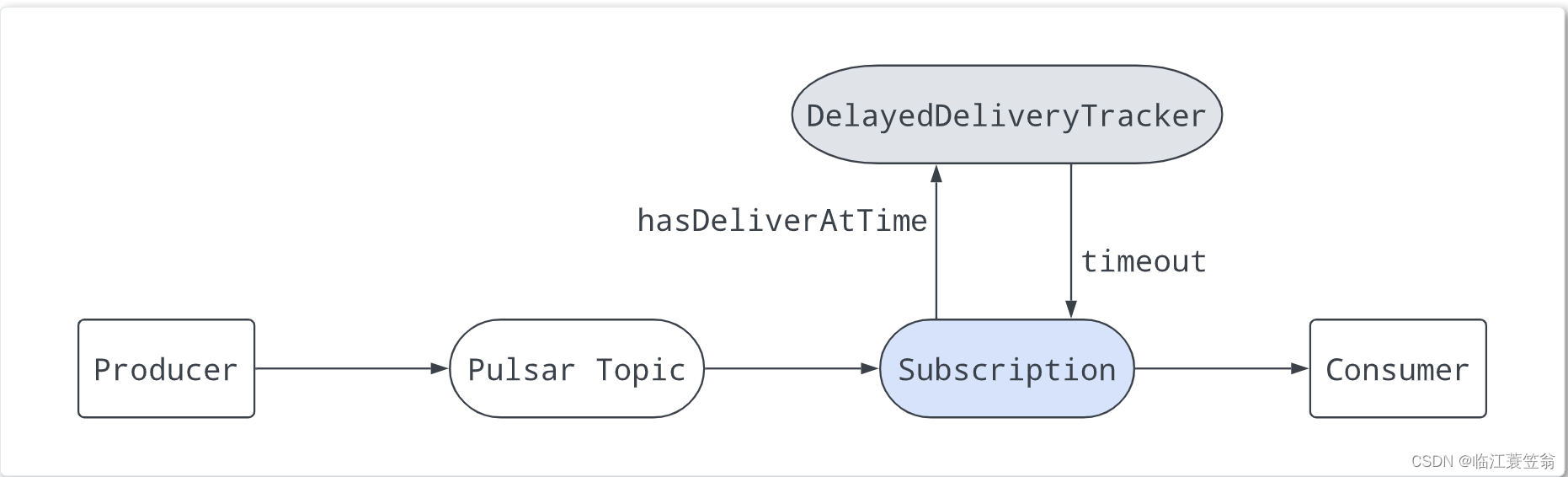
注意:只有在共享模式和key共享模式才支持延迟队列
4.消费订阅模式
pulsar总共有四种消费订阅模式:独享模式、灾备模式、共享模式和Key共享模式;
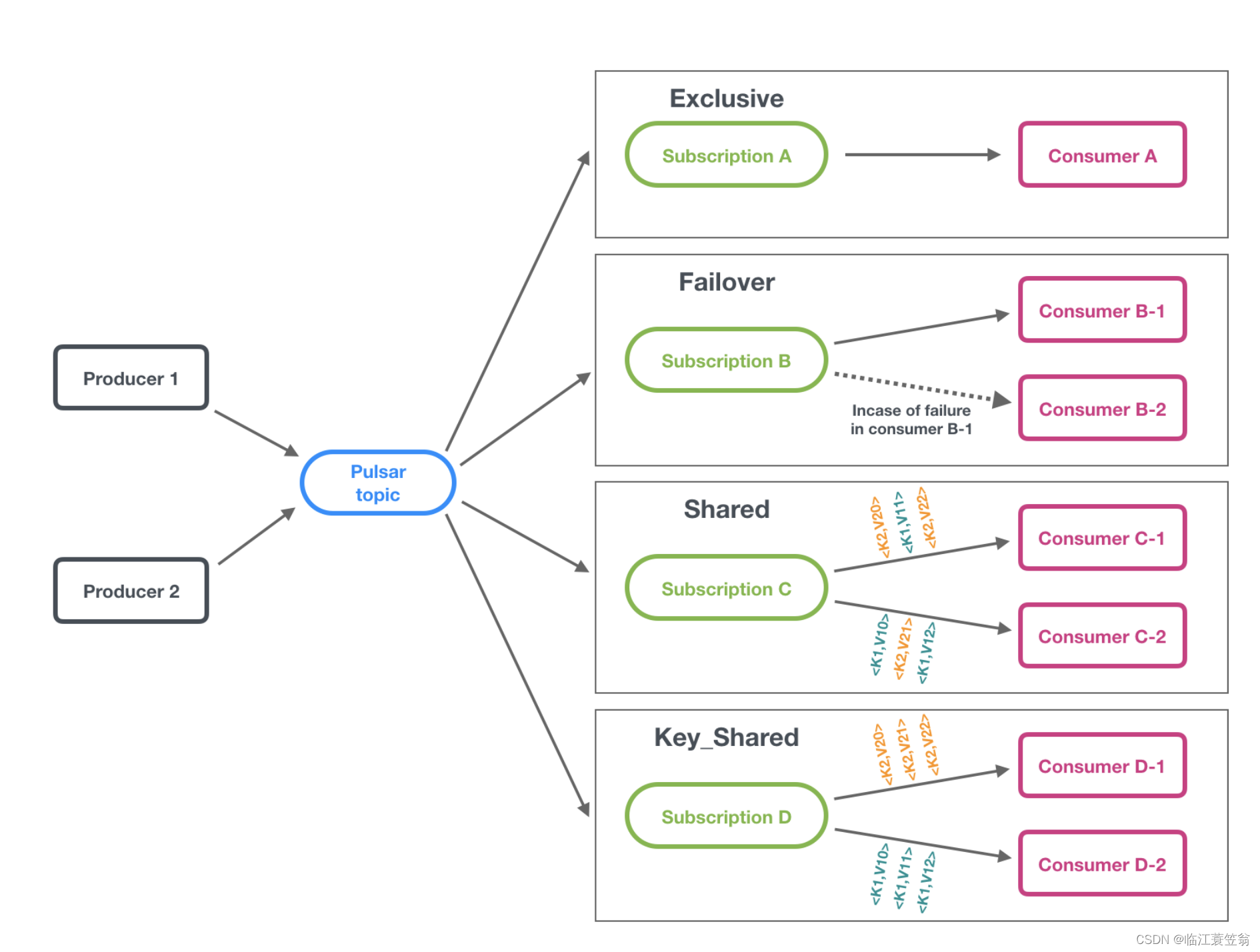
4.1 独享模式
此模式下,一个topic的某个消费组中只有一个消费者;即使topic进行了分区,所有分区也是共享同一个消费者。
此模式可以保证全局消息顺序性。
4.2 灾备模式
此模式下,一个topic可以对应多个消费者,但是只有master consumer可以消费,当master出现异常会由其他消费者进行消费。如果topic进行了分区,则每个分区都会对应一个master消费者和多个备用消费者。
此模式可以保证分区消息顺序性。
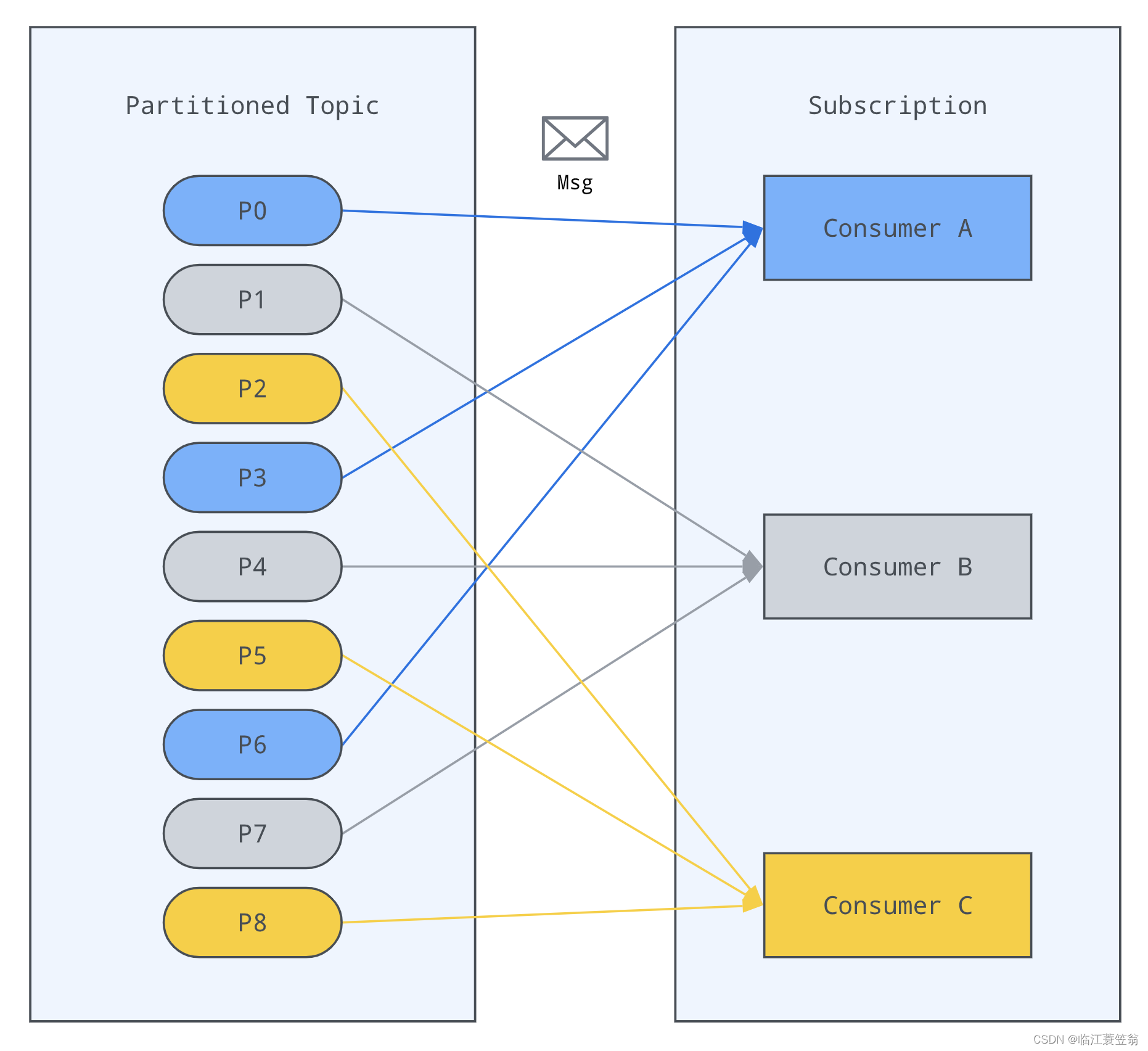
此模式下分区topic和master消费者之间分配图:
4.3 共享模式
此模式一个分区对应多个消费者,每个消费者处理分区中的一部分数据,消费者数量可以大于分区数量。此模式下可以通过增加消费者来提高消费速度。
4.4 Key共享模式
此模式一个分区对应多个消费者,每个消费者处理分区中的一部分数据,具有相同Key的消息会分派给相同Consumer处理。此模式下可以通过增加消费者来提高消费速度。
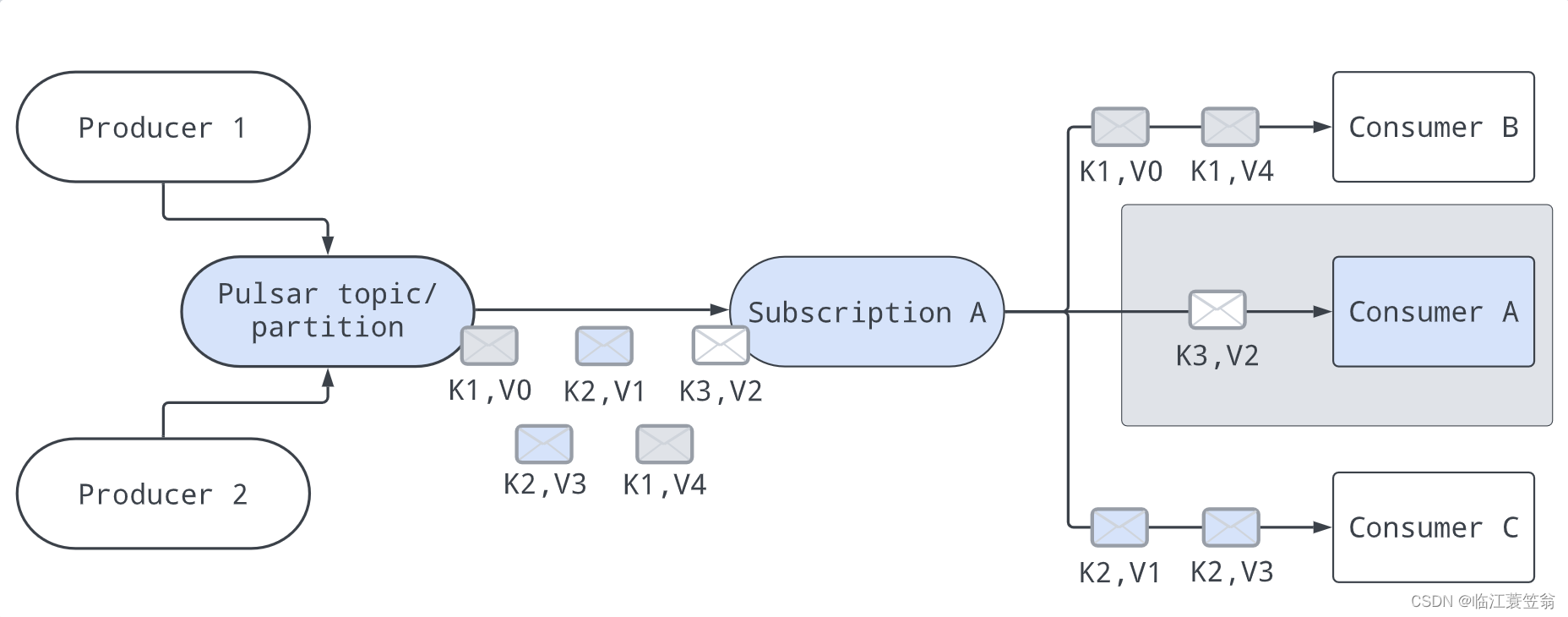
5.生产访问模式
pulsar总共有四种生产访问模式:共享模式、独占模式、独占屏蔽模式、等待独占模式;
5.1 共享模式
一个Topic可以有多个生产者
5.2 独占模式
一个Topic只能有一个生产者,新生产者连接到topic会直接报错
5.3 独占屏蔽模式
一个Topic只能有一个生产者,新生产者连接Topic,原有的生产者会被断开连接
5.4 等待独占模式
一个Topic只能有一个生产者,新的生产者连接topic会被挂起,直到生产者获取独占访问权。
总结
作为下一代云原生消息队列,Pulsar采用存储和计算分离的架构设计,具有很好的弹性伸缩能力。Pulsar单个实例可以部署多个Pulsar集群,支持多租户、持久化存储、多机房跨区域数据复制。本文主要是介绍一下Pulsar的架构和特性,后续还会对Pulsar进行近一步研读。
参考链接
1.Pulsar简介
2.Pulsar架构
3.Pulsar生产消费
这篇关于Pulsar-架构与设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








