本文主要是介绍CoreDNS实战(十二)-常见问题及优化方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题一:重启coredns导致业务域名不可解析
现象
重启coredns pod导致集群业务解析域名五分钟可不用
原因
当集群使用IPVS作为kube-proxy负载均衡模式时,可能会在CoreDNS缩容或重启时遇到DNS概率性解析超时的问题。该问题由社区Linux内核缺陷导致,具体信息,请参见。
https://github.com/torvalds/linux/commit/35dfb013149f74c2be1ff9c78f14e6a3cd1539d1?spm=a2c63.p38356.0.0.56a3eb84uFgUly
大概就是当coredns节点有变更例如ip变化了,由于有会话保持的机制pod还会复用之前的连接。
优化方案
1 部署NodeLocal DNSCache(推荐)
NodeLocal DNS介绍及部署应用_nodelocaldns-CSDN博客
1.2 NodeLocal DNS优势
- pod首先会访问nodelocaldns,nodelocaldns会将每次请求缓存到本地。可以大大的提高性能。相当于集群的每个节点都是一个dns服务器
- 降低coredns 80% - 90%的请求量,减轻coredns的压力和瓶颈问题
- 如果coredns有变更时,由于我们使用nodelocaldns,pod会首先访问nodelocaldns 如果请求没有命中,nodelocaldns 再去请求coredns 进行tcp协议的请求重新建立连接三次握手,几乎不影响业务
2 修改kube-proxy 会话保持超时时间 --ipvs-udp-timeout=10s
修改方式两种,都需要重启kube-proxy:
- 一般通常会在kube-system命名空间下有一个kube-proxy的configmap,configmap中把这行配置加上即可。
- 修改kube-proxy daemonsets 增加参数
默认超时时间为300s,遇到的现象就是服务五分钟无法解析。
简单说一下不推荐第二种方式的原因
- 可以修改为10s或者5s这样可以减少一些业务流量的损失,但是没有解决本质的问题。
- 如果设置为0则代表不开启会话保持,这种情况下业务pod每进行一次域名方式的请求都会去和coredns 建立udp的连接。频繁建连首先一定会造成很多不必要的网络开销。
- 其次就是如果coredns 将65535个端口都占用完这个时候就会建立连接失败意味着业务会解析失败。
- 重启集群所有kube-proxy pod尤其是在线业务这种操作对服务来说是毁灭性的
问题二:业务无法访问外部域名
现象
服务部署到集群后,业务反馈有些接口会报无法解析部分外网域名的问题。
导致原因
因为Deployment默认使用的dnsPolicy策略为ClusterFirstWithHostNet,这种模式会优先走集群内部的coredns解析,如果coredns无法解析就会通过coredns的配置文件 forward 到宿主机的/etc/resolv.conf文件使用nameserver dns。由于宿主机的dns是自建的,只做内网域名的解析,公网域名都会forward到公有云的DNS服务器。 画个简图如下:
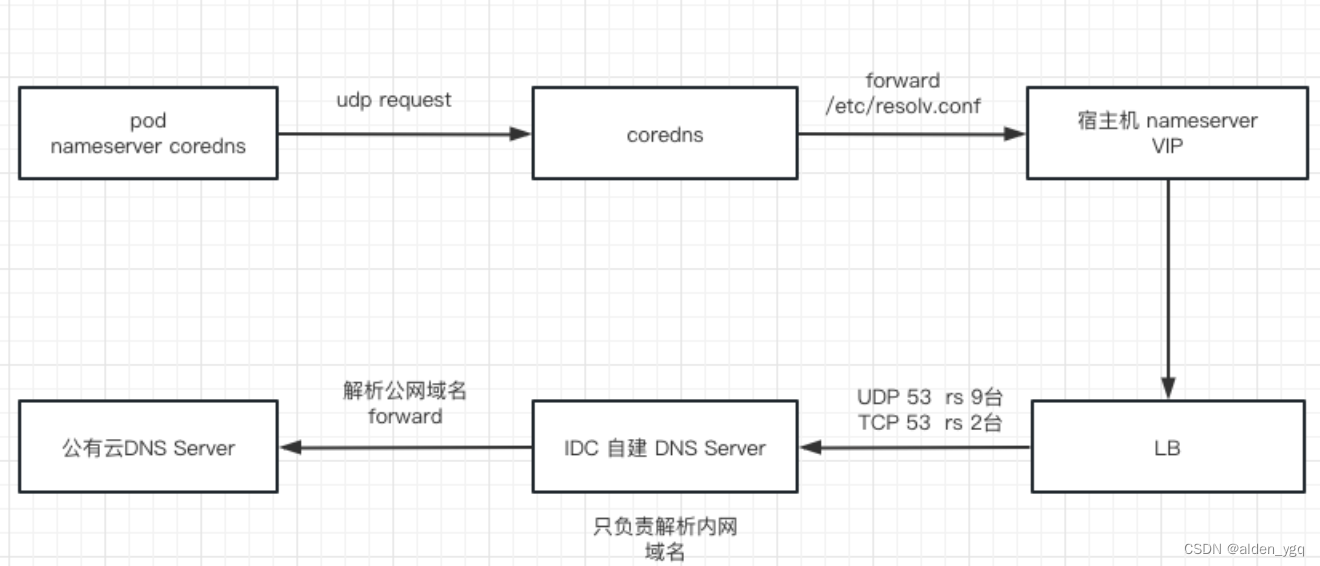
注意上面说的是部分公网无法解析并不是所有公网域名都不行。之后为了快速恢复业务,将dnsPolicy 策略改为了Default模式这个模式会将宿主机的 resolv.conf文件挂载到pod中相当于使用宿主机的nameserver。改成这种方式也没有恢复。
测试发现用dig命令直接解析时会报错 connection timed out; no servers could be reached,用nslookup 解析则正常。由于隐私问题就不截解析结果的图了。从nslookup的解析结果来看这个域名包含了70多条A记录。如下图:

这里说明了一个问题,nslookup解析域名是用的TCP协议,dig 默认不指定协议的情况是UDP,之后又用dig +tcp 再次解析这个域名结果符合预期使用tcp解析时没有问题的。
那么问题又来了,为什么使用UDP协议解析时会失败呢。抓包分析由于这个域名有很多A记录导致返回结果超过了512 字节 达到了1866字节。

抓包的路径如下:
服务器---> LB --> IDC DNS Server 这个包是在dns 服务器上看到的。同时也在服务器抓包发现服务器并没有接收到response只有query的包。那这个问题又是为什么呢?dns 服务器分明返回数据了但是客户端没有接收到。结合整体的链路判断应该是LB出现了问题:

询问云厂商后得知云厂商LB用的NAT模式也就是说请求的结果一定还会通过LB将结果返回,而且云厂商LB还有一个限制当使用UDP请求的返回结果大于1500byte 就会丢弃。而且之前测试过nameserver绑定某一台rs是没有问题。足以说明一定是LB的问题。
优化方案
- 将LB TCP 后端rs增加为9个确保每个rs都能正常响应tcp请求
- 部署NodeLocal DNSCache,pod 访问NodeLocalDNS默认协议是UDP,但是NodeLocal DNS 请求core DNS使用的是TCP协议。
- 业务代码改用TCP方式(需要研发配合修改代码,如果涉及到底层依赖的库不是太友好)
附录
Core DNS配置优化和说明
apiVersion: v1
data:Corefile: |.:53 {errorsready # 节点就绪探测,默认监听端口8181,检测通过后挂到endpoint#logdebughealth { #CoreDNS自身健康状态报告,默认监听端口8080,一般用来做健康检查lameduck 15s}kubernetes cluster.local in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}hosts {198.18.96.191 xxx.xxx.xxx.xxxfallthrough}#template IN AAAA . #禁用ipv6#template ANY AAAA { #ipv6解析时返回NXDOMAIN# rcode NXDOMAIN# fallthrough#}prometheus :9153forward . /etc/resolv.conf {prefer_udp #优先使用udp协议}cache 30loop #环路检测,如果检测到环路,则停止CoreDNS。reload #动态加载配置文件loadbalance #循环DNS负载均衡器,可以在答案中随机A、AAAA、MX记录的顺序}
kind: ConfigMap
metadata:name: corednsnamespace: kube-system这篇关于CoreDNS实战(十二)-常见问题及优化方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





