本文主要是介绍超越MobileNetV3!这个轻量级网络PP-LCNet在CPU上快到起飞!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:集智书童
 PP-LCNet: A Lightweight CPU Convolutional Neural Network
PP-LCNet: A Lightweight CPU Convolutional Neural Network
论文:https://arxiv.org/abs/2109.15099
代码:https://github.com/PaddlePaddle/PaddleClas
本文提出了一种基于MKLDNN加速策略的轻量级CPU网络,即PP-LCNet,它提高了轻量级模型在多任务上的性能,对于计算机视觉的下游任务,如目标检测、语义分割等,也有很好的表现。
1简介
随着模型特征提取能力的提高以及模型参数和FLOPs数量的增加,在基于ARM架构的移动设备或基于x86架构的CPU设备上实现快速推理变得困难。在这种情况下,已经提出了许多优秀的Mobile网络,但由于MKLDNN的限制,这些网络的速度在启用MKLDNN的Intel CPU上并不理想。
在本文中,作者重新思考了在Intel-CPU上设计网络的轻量级模型元素。作者特别考虑以下三个基本问题。
如何在不增加延迟的情况下促进网络学习更强的特性展示。
在CPU上提高轻量级模型精度的要素是什么?
如何有效结合不同的策略在CPU上设计轻量级模型。
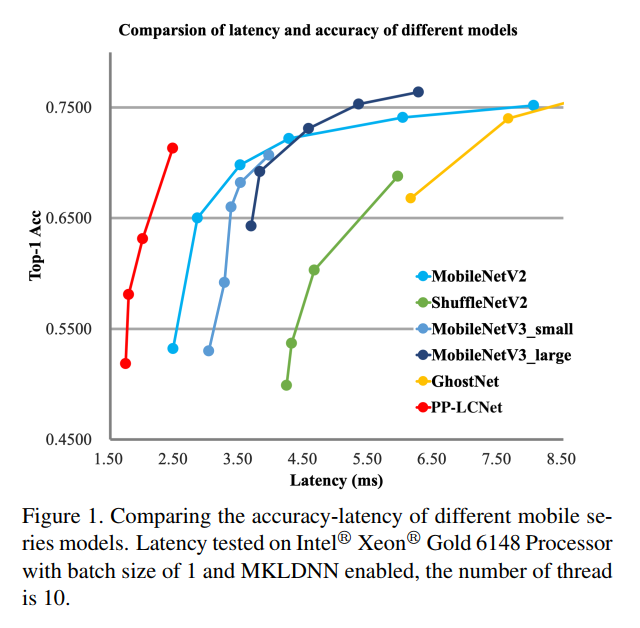
本文的主要贡献是总结了一系列在不增加推理时间的情况下提高精度的方法,以及如何将这些方法结合起来以获得更好的精度和速度的平衡。
在此基础上,提出了设计轻量级CNN的几个一般原则,为其他研究人员构建轻量级CNN提供了新的思路CPU设备。
此外,该方法可以为神经结构搜索研究人员在构建搜索空间时提供新的思路,从而更快地获得更好的模型。
2相关工作总结
2.1 手工设计的架构
VGG展示了一种简单而有效的构建深度网络的策略:用相同的维度堆叠模块。
GoogLeNet构造了Inception block,它包含了4个并行运算:1x1卷积,3x3卷积,5x5卷积和max pooling。GoogLeNet让卷积神经网络变得足够轻,然后越来越轻的网络出现。
MobileNetV1用depthwise and pointwise convolutions代替了标准卷积,大大减少了模型的参数和FLOPs数量。
MobileNetV2的作者提出了Inverted block,进一步减少了模型的FLOPs,同时提高了模型的性能。
ShuffleNetV1/V2通过channel shuffle进行信息交换,减少了网络结构不必要的开销。
GhostNet的作者提出了一种新的Ghost模块,可以用更少的参数生成更多的特征图,从而提高模型的整体性能。
2.2 神经网络结构搜索
随着GPU硬件的发展,主要关注点已经从手工设计的架构转向了自适应地对特定任务进行系统搜索的架构。NAS生成的网络大多使用与MobileNetV2类似的搜索空间,包括EfficientNet、MobileNetV3、FBNet、DNANet、OFANet等。
MixNet提出在一层中混合不同核大小的深度卷积。NAS生成的网络依赖于手工生成的块,如“BottleNeck”、“Inverted-block”等。该方法可以减少神经结构搜索的搜索空间,提高搜索效率,并有可能提高整体性能。
3本文方法
虽然有许多轻量级网络在基于ARM的设备上的推断速度很快,但很少有网络考虑到Intel CPU上的速度,特别是在启用了MKLDNN之类的加速策略时。
许多提高模型精度的方法在ARM设备上不会增加太多的推理时间,但是当切换到Intel CPU设备时,情况会有所不同。本文总结了一些在不增加推理时间的情况下提高模型性能的方法。下面将详细描述这些方法。
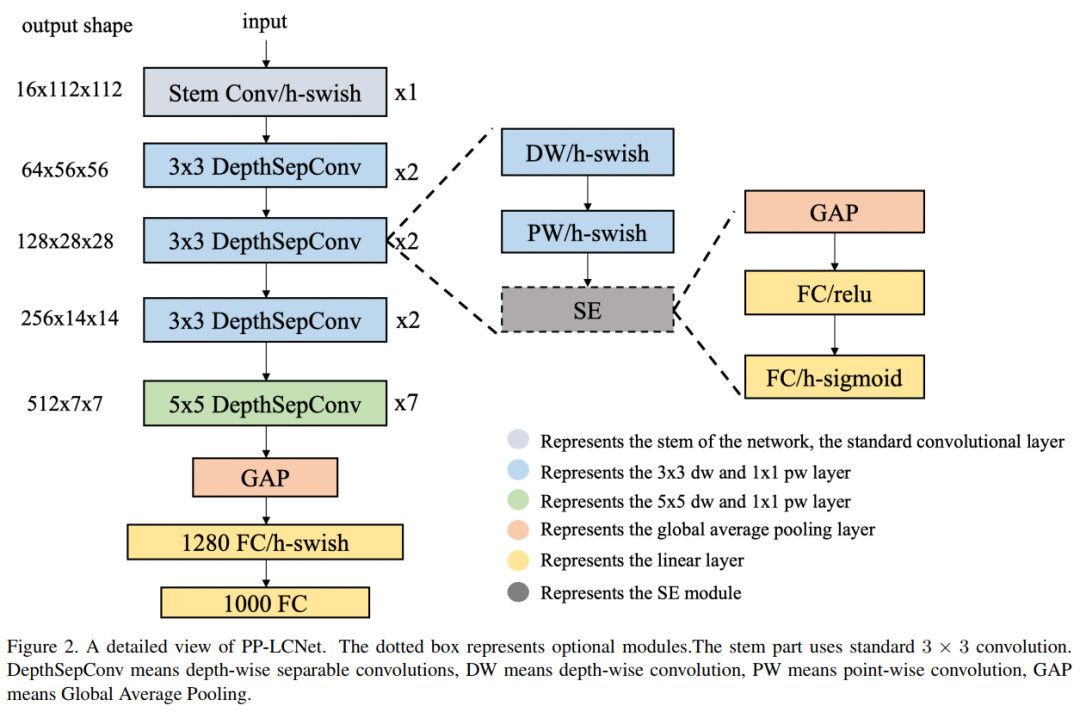
作者使用MobileNetV1提到的DepthSepConv作为基本块。该块没有shortcut方式之类的操作,因此没有concat或elementwise-add之类的附加操作,这些操作不仅会降低类的推理速度模型,而且对小模型也不会提高精度。
此外,该块经过Intel CPU加速库的深度优化,推理速度可以超过其他轻量级块,如 inverted-block或shufflenet-block。将这些块堆叠起来形成一个类似于MobileNetV1的BaseNet。将BaseNet和一些现有的技术结合在一起,形成一个更强大的网络,即PP-LCNet。
3.1 更好的激活函数
众所周知,激活函数的质量往往决定着网络的性能。由于网络的激活函数由Sigmoid变为ReLU,网络的性能得到了很大的提高。近年来,出现了越来越多超越ReLU的激活函数。当EfficientNet使用Swish激活函数表现出更好的性能后,MobileNetV3的作者将其升级为HSwish,从而避免了大量的指数运算。从那时起,许多轻量级网络也使用这个激活函数。作者还将BaseNet中的激活函数从ReLU替换为HSwish,性能有了很大的提高,而推理时间几乎没有改变。
3.2 将SE Block放在适当的位置
自SE-Block被提出以来,它已经被大量的网络所使用。该模块还帮助SENet赢得了2017年ImageNet分类竞赛。它在权衡网络通道以获得更好的特性方面做得很好,它的速度改进版本也用于许多轻量级网络,如MobileNetV3。
但是,在Intel cpu上,SE模块增加了推理时间,所以不能将其用于整个网络。事实上作者做了大量的实验和观察,当SE模块位于网络的末端时,它可以起到更好的作用。因此,只需将SE模块添加到网络尾部附近的模块中。这带来了一个更好的精度-速度平衡。与MobileNetV3一样,SE模块的2层激活函数分别为ReLU和HSigmoid。
3.3 更大的卷积核
卷积核的大小常常影响网络的最终性能。在MixNet中,作者分析了不同大小的卷积核对网络性能的影响,最终在网络的同一层中混合了不同大小的卷积核。但是这样的混合降低了模型的推理速度,所以作者尝试在单层中只使用一种大小的卷积核,并确保在低延迟和高精度的情况下使用大的卷积核。
实验发现,类似于SE模块的位置,取代3x3卷积内核只有5x5卷积内核的末端网络将实现替换的影响几乎所有层的网络,所以只在网络的末端做了这个替换操作。
3.4 Larger dimensional 1×1 conv layer after GAP
PP-LCNet中,经过GAP后的网络输出维数很小。而直接添加最终的分类层会失去特征的组合。为了使网络具有更强的拟合能力,在最后的GAP层之后增加了一个1280维尺寸为1×1 conv(相当于FC层),这将允许更多的模型存储,而不增加推断时间。
4实验
4.1 图像分类
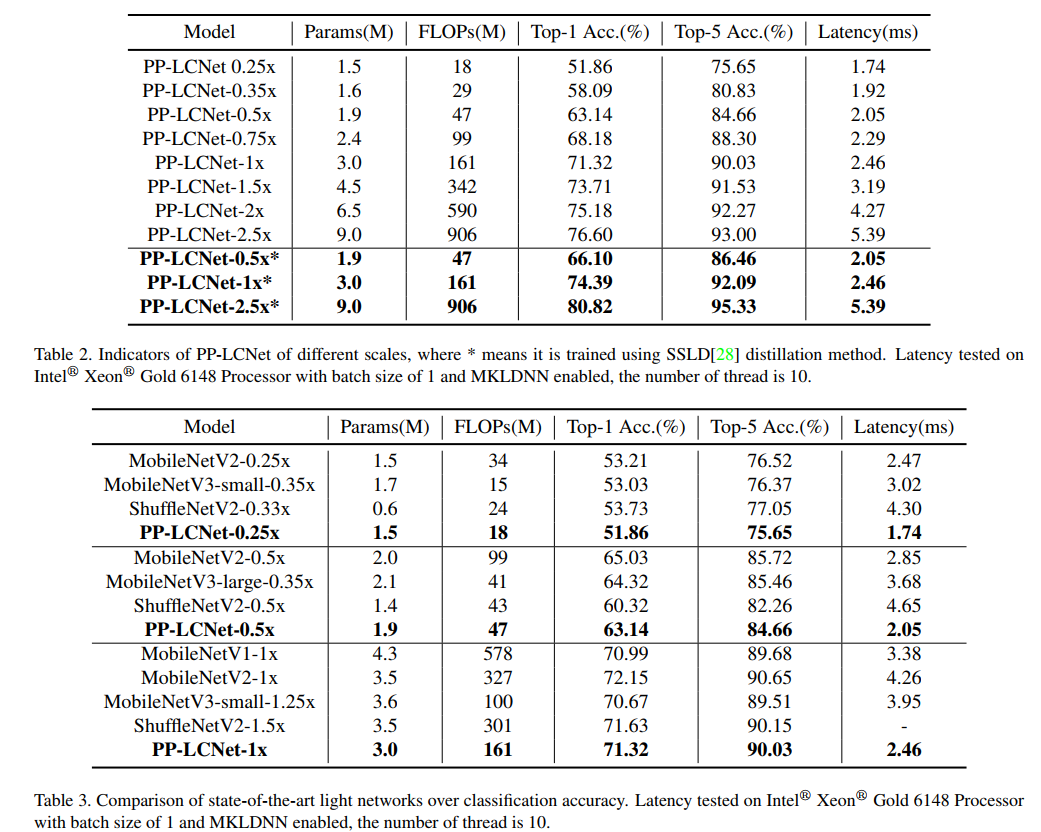
表2显示了PP-LCNet在不同尺度下的top-1和top-5的验证精度和推断时间。此外,采用SSLD精馏法可大大提高模型的精度。表3显示了PP-LCNet与最先进模型的比较。与其他模型相比,PP-LCNet显示出强大的竞争力。
4.2 目标检测
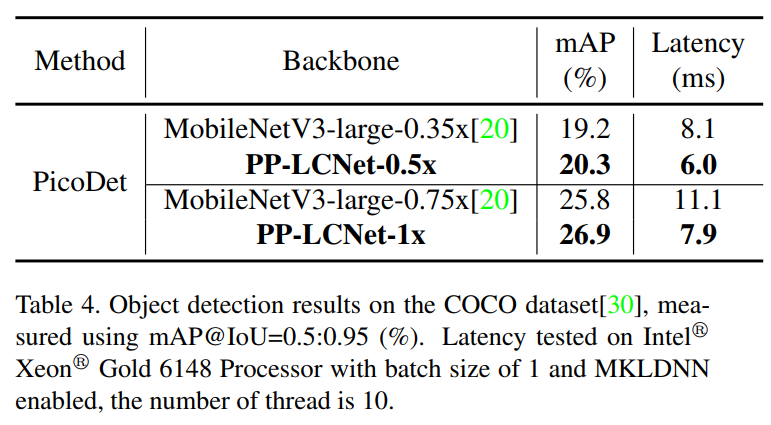
对于目标检测任务,使用PaddleDection3开发的轻量级PicoDet作为Baseline方法。表4显示了PP-LCNet和MobileNetV3为Backbone的目标检测结果。与MobileNetV3相比,PP-LCNet大大提高了COCO上的mAP和推理速度。
4.3 语义分割
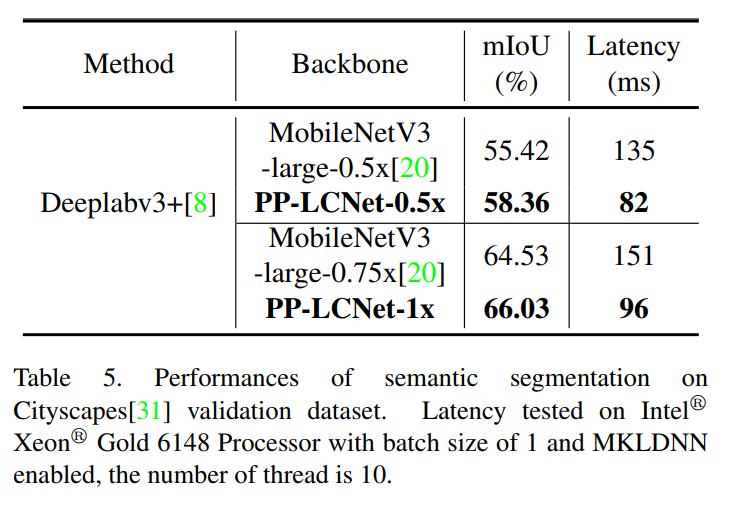
使用MobileNetV3作为Backbone进行比较。如表5所示,PP-LCNet-0.5x表现更好MobileNetV3-large-0.5x在mIoU上提高了2.94%,但推断时间减少了53ms。与 larger models相比,PP-LCNet也具有较强的性能。以PPLCNet-1x为Backbone时,模型的mIOU比MobileNetV3-large-0.75x提高了1.5%,但推理时间缩短了55ms。
4.4 消融实验
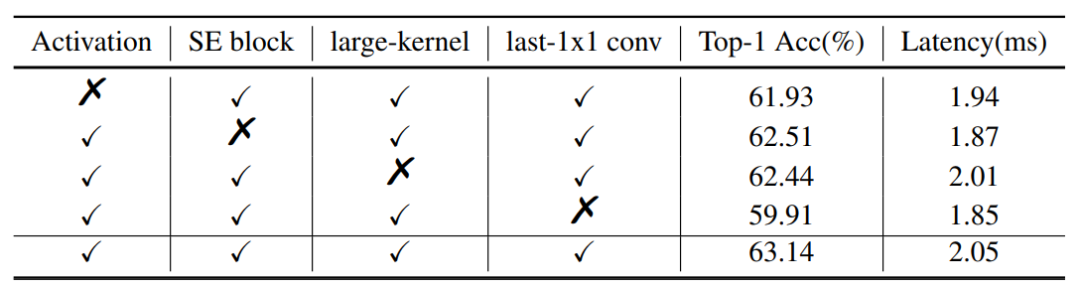
1、SE模块在不同位置的影响:
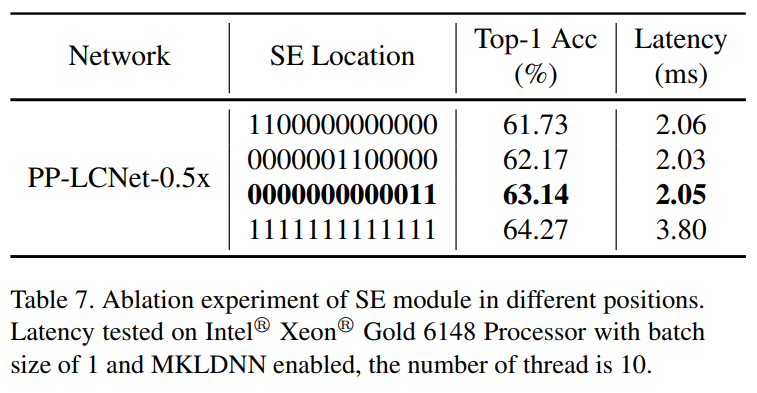
SE模块是通道间的注意力机制,可以提高模型的准确性。但如果盲目增加SE模块的数量,则会降低模型的推理速度,因此如何在模型中适当添加SE模块是值得研究和探索的。通过实验发现SE模块会对网络的末端产生较大的影响。如表7所示仅在网络中不同位置添加2个SE模块的结果。该表清楚地显示,对于几乎相同的推断时间,添加最后两个块更有利。因此,为了平衡推理速度,PP-LCNet只在最后两个块中添加了SE模块。
2、Large-kernel在不同位置的影响:
虽然Large-kernel可以提高精度,但在网络的所有位置都添加它并不是最好的方法。通过实验,给出了正确添加Large-kernel的一般规律。表8显示了5x5深度卷积所添加的位置。1表示DepthSepConv中的深度卷积核为5x5, 0表示DepthSepConv中的深度卷积核为3x3。从表中可以看出,与添加SE模块的位置相似,在网络尾部添加5x5卷积也更具竞争力。PP-LCNet选择了表的第3行中的配置。

3、不同技术的影响
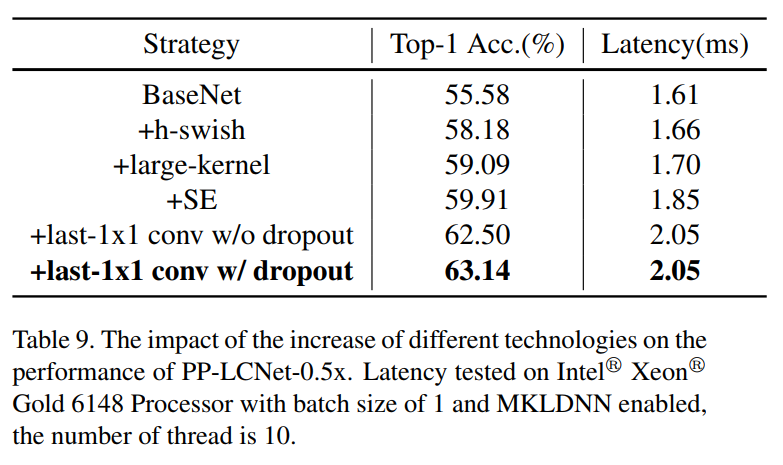
在PP-LCNet中使用了4种不同的技术来提高模型的性能。表9列出了不同技术对PP-LCNet的累积增长,表6列出了减少不同模块对PP-LCNet的影响。从这2个表中可以看出,H-Swish和large-kernel可以在几乎不增加推断时间的情况下提高模型的性能。添加少量的SE模块可以进一步提高模型的性能。GAP后使用更大的FC层也将大大提高精度。同时,也许因为这里涉及的矩阵比较大,使用dropout策略可以进一步提高模型的准确性。
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看这篇关于超越MobileNetV3!这个轻量级网络PP-LCNet在CPU上快到起飞!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






