本文主要是介绍机器学习---贷款违约行为预警预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
#一 、数据预处理
我们拿到的原始数据是12张表格,包含了150多个字段,总共3万多条记录。拿到这么多数据,我们该怎么预处理呢?
首先第一步对各个表格单独预处理,其次合并后对合并后的数据预处理。
##1.每张表格单独处理
我们以其中一张表为例,来具体讲解怎么处理。这张表包含下列字段
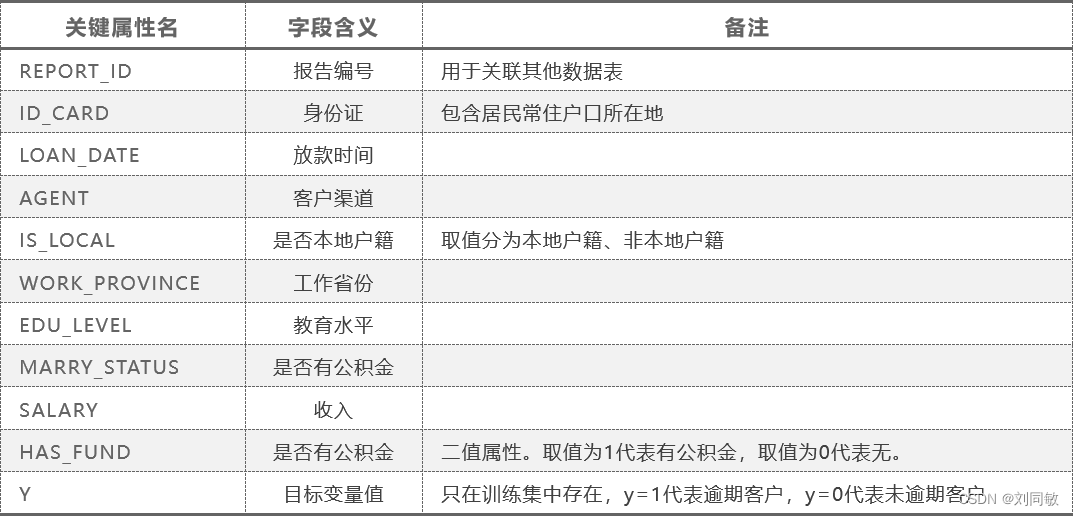
处理的内容包括:变量属性识别与标注、空值处理、异常值处理、维规约、独热编码、标准化
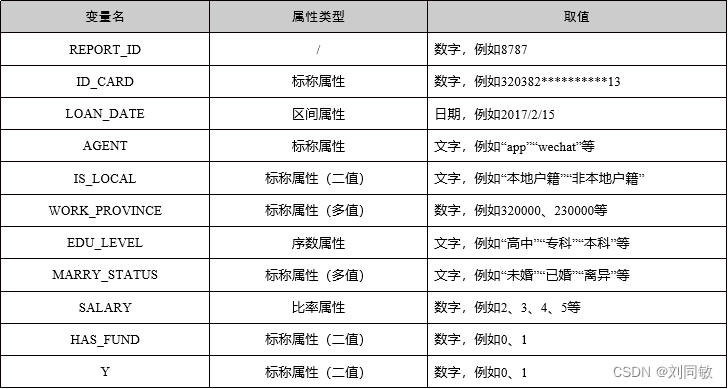
变量属性分为定性属性和定量属性,而定性属性分为标称属性(例如性别)和序数属性(例如学历),定量属性分为区间属性(例如日期)和比率属性(例如年龄、工资)。对不同变量属性的处理方法都不相同。
首先通过代码对每个表的变量进行自动化的变量属性识别,并结合人工进行标注,得到每个变量的属性类型。如“gender”一项可按身份证号标记男女为1和0,“MARRY_STATUS”根据其不同的婚姻状态可以标记为0~5。
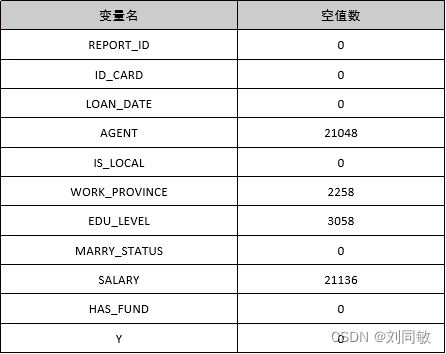
对空值的统计如下表所示,可以发现空值较多的变量为WORK_PROVINCE、EDU_LEVEL、AGENT和SALARY。首先评判该属性是否重要、其影响是否显著。若该变量重要,则处理的方法有:使用其他信息的相关内容进行填补(如身份证号前6位可代表出生地区),使用样本均值或建立模型。若该变量不重要,则可直接使用.drop()方法将变量剔除。
异常值处理主要针对连续变量,防止出现某些远超分布范围的值对整个分布造成影响。
本案例只有一个连续变量(SALARY),变量属性类型为比率属性。选择winsorize变换处理异常值,其思想是通过上下分位数对特征的分布进行约束,选择99%和1%分位数作为阈值,当值超过99%分位数时,用99%分位数的值进行替换;当值低于1%分位数时,用1%分位数的值进行替换。
维归约就是指数据特征维度数目减少或者压缩,摒弃掉不重要的维度特征,尽量只用少数的关键特征来描述数据。人们总是希望看到的现象主要是由少数的关键特征造成的,找到这些关键特征也是数据分析的目的。 如果数据经过归约处理得当,不影响数据重新构造而不丢失任何信息,则该数据归约是无损的。
对变量WORK_PROVINCE进行空值处理后,发现该变量的值比较多,这将导致对该变量独热编码时,产生大量的二元特征,且非常稀疏,因此将其进行维规约,将城市变量规约到省份变量中,最终得到近30个代表省份的虚拟变量。
独热编码又称为一位有效编码,采用N为状态寄存器对N个状态进行编码,每个状态都有它的独立寄存器位,并且在任意时候只对一位有效。例如“性别”这一属性可选值为[”男”、“女],可以定义值为[01,10]。
针对标称变量IS_LOCAL、WORK_PROVINCE、MARRY_STATUS,进行独热编码,生成该变量每一个类别对应的虚拟变量,同时需要注意虚拟变量陷阱,剔除作为对照组的虚拟变量,以防止多重共线性。
数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响。
针对比率属性变量SALARY、区间属性变量LOAN_DATE、序数属性变量EDU_LEVEL,为了防止计算距离时量纲不统一带来的问题,对其进行标准化,即用该变量值减去均值后除以标准差。
##2.合并12张表格且预处理
###合并
每张表预处理完毕后,通过report_id属性将table_1至table_11合并成一张表train_all.csv。
###合并后预处理
合并完毕后,pre_train.py将对合并的数据进行最终的预处理,包括去除空值、去除非重要信息。得到最后数据存在trainafter.csv中。
#二、客户聚类分析
##1 聚类
我们要做预警分析,势必要对客户做聚类,聚类最常见的算法就是k均值,但k均值算法如何确定合适的k值呢?也就是具体聚成几类比较合适呢?我们常用使用手肘法最合适的聚类数k。比如本案例的最合适聚类数是4
手肘法的核心指标是误差平方和(SSE),随着k值的增加,sse值会慢慢变小,最后趋近于一个稳定值。变化过程举例如图:
##2 添加标记
通过上述处理后,我们可以把客户分成4个类,但那个类别的是风险大的,那个是风险小的,我们没办法判断。这时候我们根据聚类标记“1”,“2”,“3”,"4"和违约标记“0”,“1” 来确定类别。我们计算每个聚类的违约比率,比率由高到低分别标记为“危险客户”,“高风险客户”,“中风险客户”,“低风险客户”。
#三、贷款行为违约预警预测
我们的实现思路是:
1.根据已知数据生成两个模型,一个是根据危险程度分类的预警模型,另一个是根据违约与否分类的违约预测模型。
2.现在有新增客户,我们首先用预警模型分类,看他是否是危险客户或高风险客户,如果是,我们需要进一步使用违约预测模型判断他是否存在违约可能。
##1.预警
拿到包含聚类标记的数据,我们使用带正则的Logistic回归模型对数据进行分类,生成相应的分类模型。
##2 预测
基于trainafter.csv,我们使用带正则的Logistic回归模型对违规与否进行分类,生成相应的分类模型。
这篇关于机器学习---贷款违约行为预警预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





