本文主要是介绍RAG (Retrieval Augmented Generation)简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 背景
目前大模型很多,绝大部分大模型都是通用型大模型,也就是说使用的是标准的数据,比如wikipedia,百度百科,。。。。 中小型企业一般都有自己的知识库,而这些知识库的数据没有在通用型的大模型中被用到或者说训练到。如果中小型企业要适合自己本身业务需要的大模型,当然理想的方法是重新训练数据,而这些数据有其自身业务场景的数据。 现实是自身训练无论是人力成本,数据成本,计算成本都是不可行的。那么一种基于通用大模型,并外挂本地知识库的人工智能方法RAG(Retrieval Augmented Generation)就运用而生。通过这种方法,中小型企业可以用很少的人力,物力,在不改动通用大模型的情况下,就能结合自身需要,为自己的业务场景服务。
2. 框架图和简单介绍
接下来,我们就来介绍RAG。我们先看标准的RAG流程或框架图,然后在下面的文字中介绍两种优化的RAG,我们还会给出处于研究中或朦胧状态的新的RAG的出处或文献参考。本文是基于下面的LLM或RAG课程的总结。【1】【2】【3】。
2.1 入库
那么现在,让我们先看标准的RAG流程或框架图:先是第一步入库,入库就是把原始分本分割,然后每个分割后的短文本,进行分词(chunk),然后向量映射(embedding),最后入库。
RAG 第一步入库
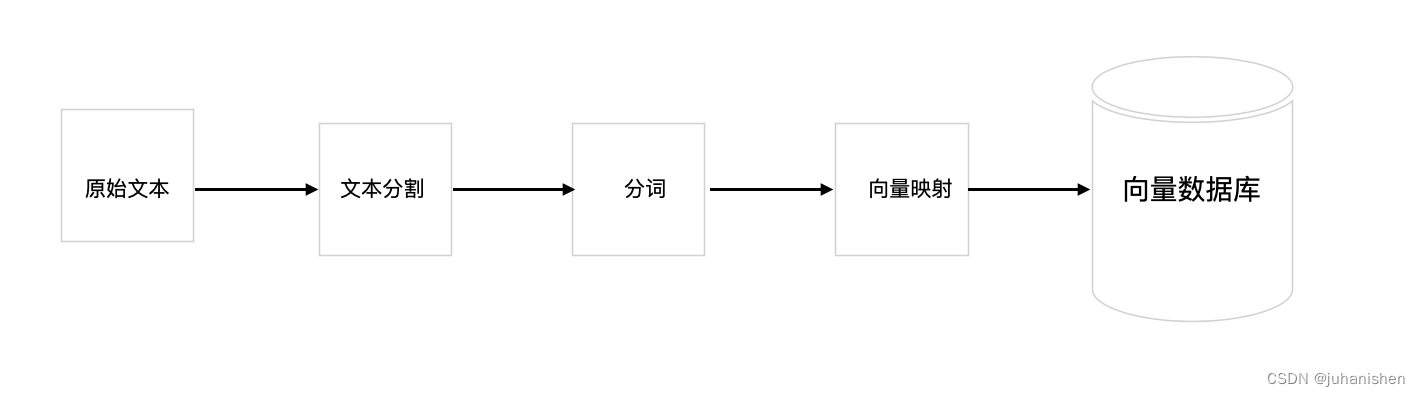
图 1
图1 是RAG的第一步,文本入库。库可以是一般数据库,文件系统都可以,我们这里用向量数据库作为例子。像目前的智能客服机器人,一般就是使用向量数据库。
2.1.1 分本分割
其中,文本分割是因为背景提示窗口大小的限制,一般只有几千个Token。Token是指最小的单词,字符和词组的向量。
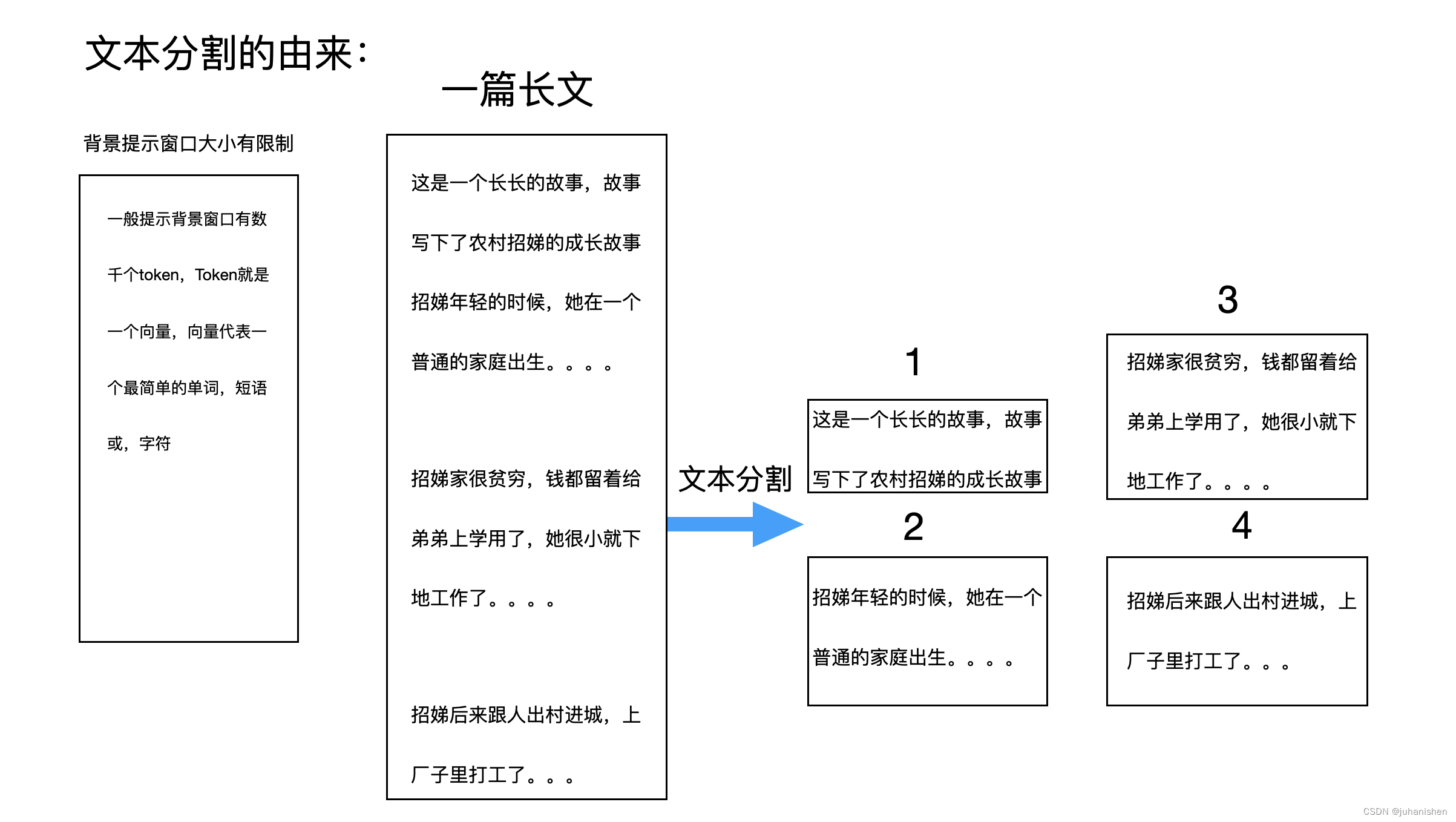
图 2
我们的原始文件很长,但提示窗口一般只容纳几千个Token,所以,要将文本分割,这个就是文本分割。图2中,我们将一篇长文分割成4篇小文。
2.2 RAG 查询
入库成功以后,就是查询,然后就是augmented,augmented在这里是指将查询和向量数据库查出的结果合成作为一个新的提示,然后查询LLM(大语言模型)。
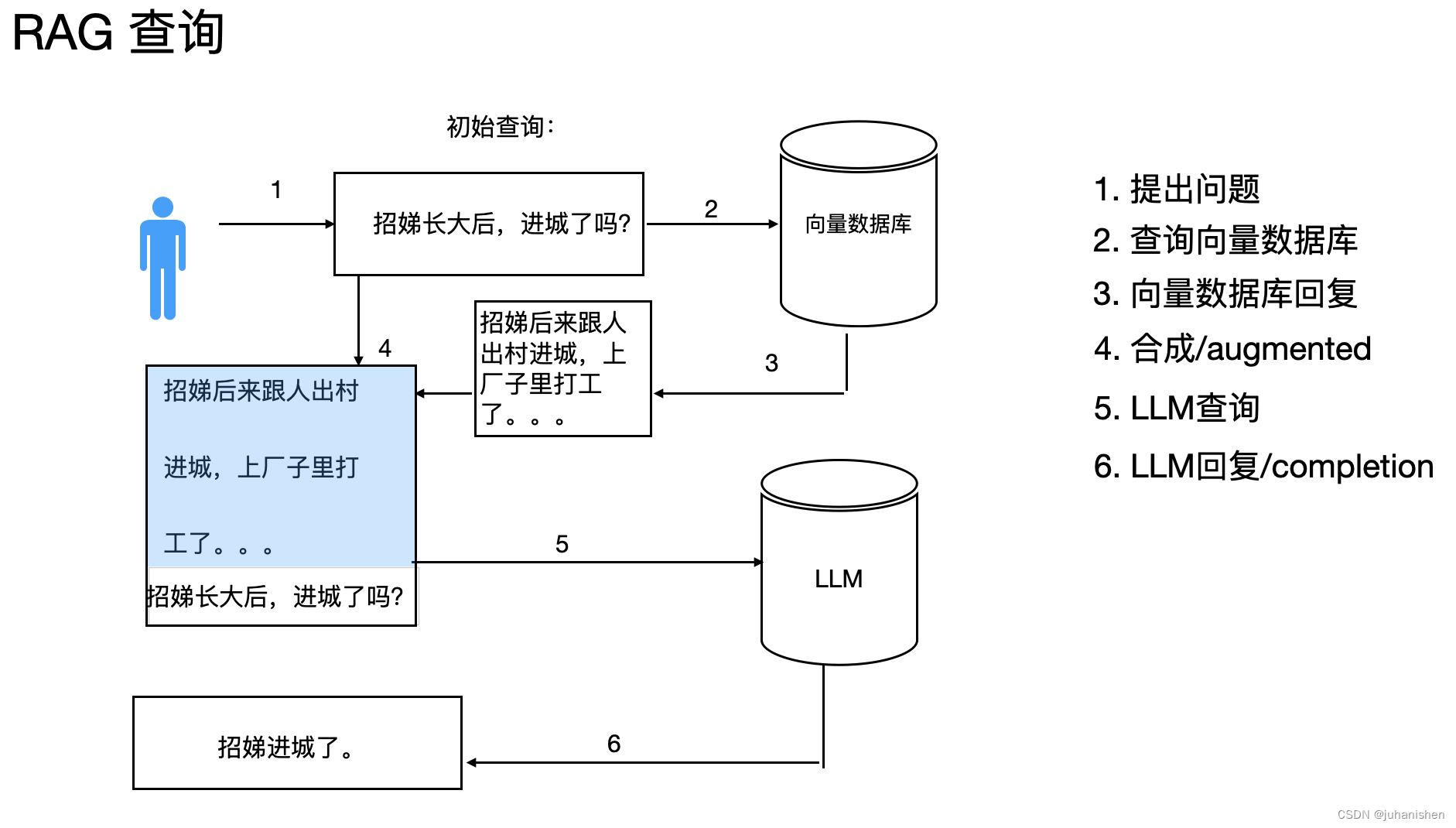
图 3
从图3中,我们看出框架图组件有向量数据库(Vector Database)和大模型。向量数据库存储着中小企业的业务场景的本地知识库,用户先从向量数据库,就是本地知识库查询,然后将查询的结果作为大模型的输入,进行查询。
2.2.1 提示查询
当我们开始查询时,我们先查询本地知识库,就是向量数据库,然后向量数据库抽取数据,回复提问。就是图3中的第1,2,3步骤。
2.2.2 合成答复和查询
当向量数据库回复后,我们将查询向量数据库的问题和向量数据库的回答合成一个提示,再查询大语言模型。就是图3中的4,5步骤。
2.2.3 大模型回复/completion
合成后的提示输入到大模型中,得到回复/completion,就完成了一次RAG。
3. 高级/优化的RAG
A. Query expansion
待下文发表
B. Cross-encoding DeRank
待下文发表
4. 处于朦胧时期的高级RAG

图 4
5. 参考资料
[1]. coursera.org:Generative AI with large language model
[2]. deepLearning.ai:Advanced Retrieval for AI with Chroma
[3]. deep learning.ai: Building and Evaluating Advanced RAG Applications
[4] 领英LLM的一些专栏
沈建军于上海 2024年2月14日周三
2)2024年2月15日小修改
这篇关于RAG (Retrieval Augmented Generation)简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




