本文主要是介绍爬虫——ajax和selenuim总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么要写这个博客呢,这个代码前面其实都有,就是结束了。明天搞个qq登录,这个就结束了。
当然也会更新小说爬取,和百度翻译,百度小姐姐的爬取,的对比爬取。总结嘛!!!加油!!!
============================ajax====================================
,有时爬不到东西,可能是经过Ajax加载的数据,不是原始的HTML文档。
这样我们就要来模拟Ajax请求。
上实例:比如说我前几篇的,异步社区的爬取。
response = requests.get(url,headers=hearder,params=params).text用的不光有url,headers,还有params,params中是对页数等的请求。
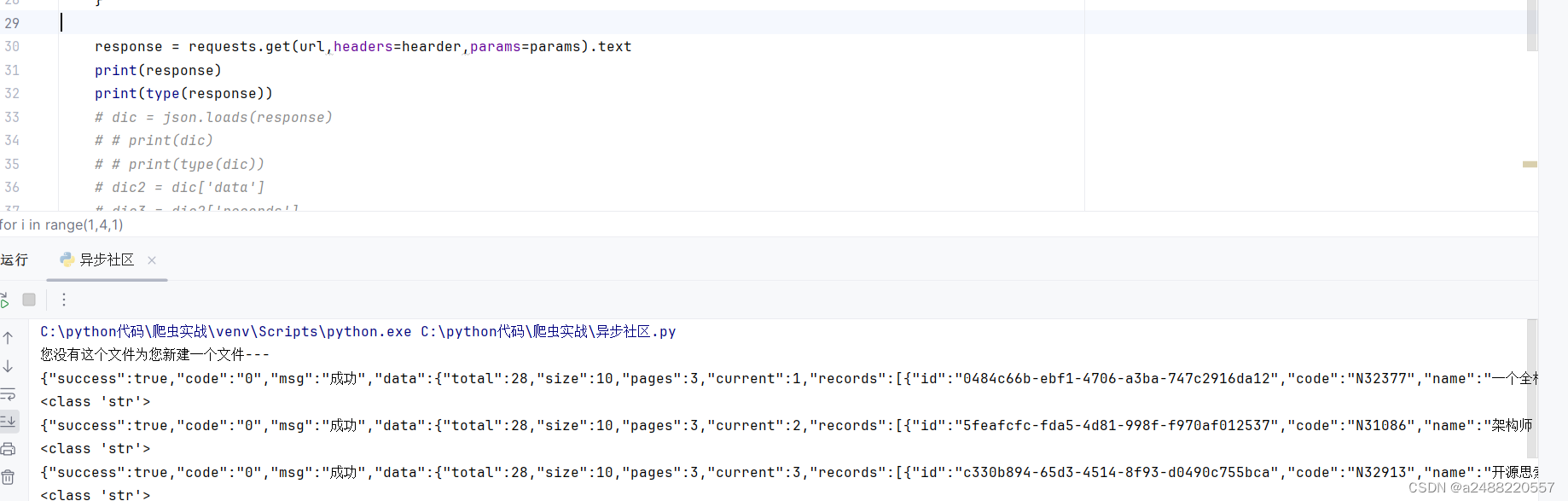
得到的是字典样子的数据,但是是字符串。
这就要用到json.loads(),来把字符串类型,转化为python的字典类型了
-----------------得到字典就是取值了。
同一个网站不用,params,就不会请求成功。
selenuim---用浏览器实现自动化(很强大的反爬工具)。
有些网站可能会有JavaScript动态加载数据,这种情况下,简单的获取初始HTML可能无法获取
这时就是用selenuim来模拟浏览器。
来复习一便selenuim自动化吧!!!-下一篇就是登录自动qq(目标)
第一篇代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Edge()# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.baidu.com')
#寻找(异常的捕获)
try:element = wd.find_element(By.ID,'kw')element.send_keys('通讯')caozuo = wd.find_element(By.ID,'su')caozuo.click()#点击wd.quit()#退出input('等待回车键结束程序')except NoSuchElementException:print('不存在')1.导库-最后一个是异常
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException2.这里try是如果抛出异常,就咋咋咋!
3. wd.find-element(),caozuo.click()-------------------------很重要
---------------------二-------------------------------
第二篇代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementExceptionurl = 'https://cdn2.byhy.net/files/selenium/sample1.html'
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Edge()# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get(url)
#根据ID查找
id_element = wd.find_element(By.ID,'searchtext')
id_element.send_keys('haha')
input("jix1")
#根据class的名字查找++
elements = wd.find_elements(By.CLASS_NAME,'plant')
for i in elements:print(i.text)
#根据标签查找
all_elements = wd.find_elements(By.TAG_NAME,'span')
for i in all_elements:print(i.text)
#退出
wd.quit()很简单和第一个差不多,就是变成了,找一个(element),变成了找所有(elements)
----------------------------------三-----------------------------------------------
第三篇代码:
import timefrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementExceptionurl = 'https://im.qq.com/index/'wd = webdriver.Edge()
wd.implicitly_wait(10)wd.get(url)elements = wd.find_element(By.NAME,'im.qq.com.login')
elements.click()
time.sleep(1)
element = wd.find_element(By.ID,'bottom_qlogin')
time.sleep(1)
element2 = wd.find_element(By.ID,'switcher_plogin')
time.sleep(1)
element2.click()
time.sleep(2)
wd.quit()这个也没啥就是-----wd.implicitly_wait(10)------因为爬取要时间,相当一个等待的代码。
------------------------------四-------------------------------
第四篇代码:
frame窗口转换
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementExceptionurl = "https://cdn2.byhy.net/files/selenium/sample2.html"
wd = webdriver.Edge()
wd.implicitly_wait(10)wd.get(url)
#切换到内frame里面
wd.switch_to.frame(wd.find_element(By.CSS_SELECTOR,'[src="sample1.html"]'))
elements = wd.find_elements(By.CSS_SELECTOR,'.plant')
for i in elements:print(i.get_attribute('outerHTML'))
#切换到外部
wd.switch_to.default_content()
wd.find_element(By.CSS_SELECTOR,'#outerbutton')
print(wd.find_element(By.CSS_SELECTOR,'#outerbutton').get_attribute('outerHTML'))
wd.find_element(By.CSS_SELECTOR,'#outerbutton').click()
time.sleep(2)
wd.quit()
input("jj")
这个很重要,加入了CSS,CSS也就是选择器,很强大。
1.wd.switch_to.frame(wd.find_element(By.CSS_SELECTOR,'[src="sample1.html"]'))
找么有‘ID’或者‘Class’的,并且进入frame窗口
2.print(i.get_attribute('outerHTML'))——这个将会打印标签在HTML是什么样的,打印出来就是什么样的
3.wd.switch_to.default_content()————返回到外部窗口
-------------------------------------------五-------------------------------------------
第五篇代码:
浏览器窗口的变化
import time
from selenium import webdriver
from selenium.webdriver.common.by import Byurl = "https://cdn2.byhy.net/files/selenium/sample3.html"
wd = webdriver.Edge()
wd.implicitly_wait(10)wd.get(url)element = wd.find_element(By.CSS_SELECTOR,'a')print(element.get_attribute('outerHTML'))
element.click()
#存储下来
mainWindow = wd.current_window_handletime.sleep(5)for handle in wd.window_handles:wd.switch_to.window(handle)print(wd.title)if '必应' in wd.title:breakwd.find_element(By.CSS_SELECTOR,'#sb_form_q').send_keys("hahahah")
time.sleep(1)
wd.find_element(By.CSS_SELECTOR,'#search_icon').click()time.sleep(5)
#返回窗口
wd.switch_to.window(mainWindow)wd.find_element(By.CSS_SELECTOR,'button').click()
wd.find_element(By.CSS_SELECTOR,'button').click()
time.sleep(5)wd.quit()
1.mainWindow = wd.current_window_handle-这个很有必要,就是存储当前窗口,以便返回。
2.
for handle in wd.window_handles:wd.switch_to.window(handle)print(wd.title)if '必应' in wd.title:break在目前浏览器窗口找,有必应两个字的窗口。并转到
为什么要写这个博客呢,这个代码前面其实都有,就是结束了。明天搞个qq登录,这个就结束了。
当然也会更新小说爬取,和百度翻译,百度小姐姐的爬取,的对比爬取。总结嘛!!!加油!!!
这篇关于爬虫——ajax和selenuim总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








