本文主要是介绍Impala-架构与设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
架构与设计
- 一、背景和起源
- 二、框架概述
- 1.设计特点
- 2.框架优点
- 3.框架限制
- 三、架构图
- 1.Impala Daemon
- 2.Statestore
- 3.Catalog
- 四、Impala查询流程
- 1.发起查询
- 2.生成执行计划
- 3.分配任务
- 4.交换中间数据
- 5.汇集结果
- 6.返回结果
- 总结
- 参考链接
一、背景和起源
现有的大数据查询分析工具Hive更适合长时间批处理查询分析,并不能满足实时交互式场景。因此根据谷歌的Dremel设计思想,Cloudera公司开发了一款高效率实时查询工具Impala,其性能比Hive快10到100倍。Impala没有使用MapReduce进行计算,而是将整个查询转化成执行计划树,分发到各个机器执行,然后通过拉的方式获取结果并组合成最终结果。
二、框架概述
Impala是一款基于Hive的大数据分析查询引擎,直接使用Hive的元数据Metastore,因此如果使用Impala需要先安装Hive并启动Metastore服务。Impala不依赖MapReduce而是将执行计划树进行并行计算,使用拉的方式获取结果数据,把结果数据按执行树流是传递汇集,减少中间结果落盘。
1.设计特点
- 本地化计算、减少数据的网络传输
- 采用Hive Metastore进行元数据存储和管理
- 无需进行格式转化
- 支持即席查询无延迟
- 采用大规模并行处理架构、硬件利用率高
- 不依赖MapReduce,并行处理执行计划,避免启动MapReduce开销
- 结果写入内存并通过网络汇总,节省读写磁盘开销
2.框架优点
- 基于内存进行计算,适合实时交互式SQL查询和分析
- 无需转化为MapReduce,直接访问HDFS以及Hbase数据,低延迟
3.框架限制
- 数据需要写入内存,对内存消耗比较大
- 没有容错逻辑,如果执行过程发生错误会直接返回错误
- 不支持UDF定制
三、架构图
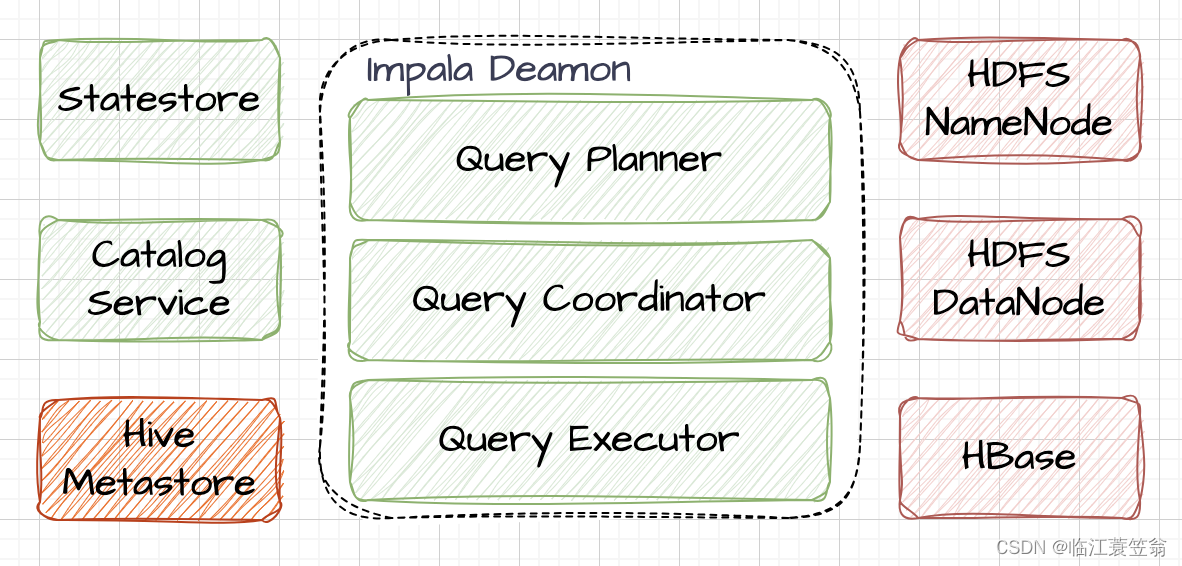
Impala采用MPP架构,主要由Impala Daemon、Statestore和Catalog等三个模块组成。
1.Impala Daemon
接收查询请求,将查询请求生成计划树,分发执行计划到其他节点。进行数据读写,将结果进行汇总并返回。
Impala Daemon服务包含三个模块:Query Planner、Query Coordinator和Query Executor。
2.Statestore
主要是收集集群中所有Deamon的节点信息和健康情况。每个Deamon会从Statestore拉取并缓存所有Deamon相关信息,用于执行计划的分配。
3.Catalog
Impala的元数据服务,集群启动时从Hive Metastore加载元数据信息,如需再次加载需要使用invalidate metadata、refresh命令。Catalog负责接收Statestore的元数据查询请求。在Impala执行SQL导致元数据发生变化时,Catalog会将元数据变化同步给Statestore,再由Statestore广播给所有Daemon节点。
四、Impala查询流程
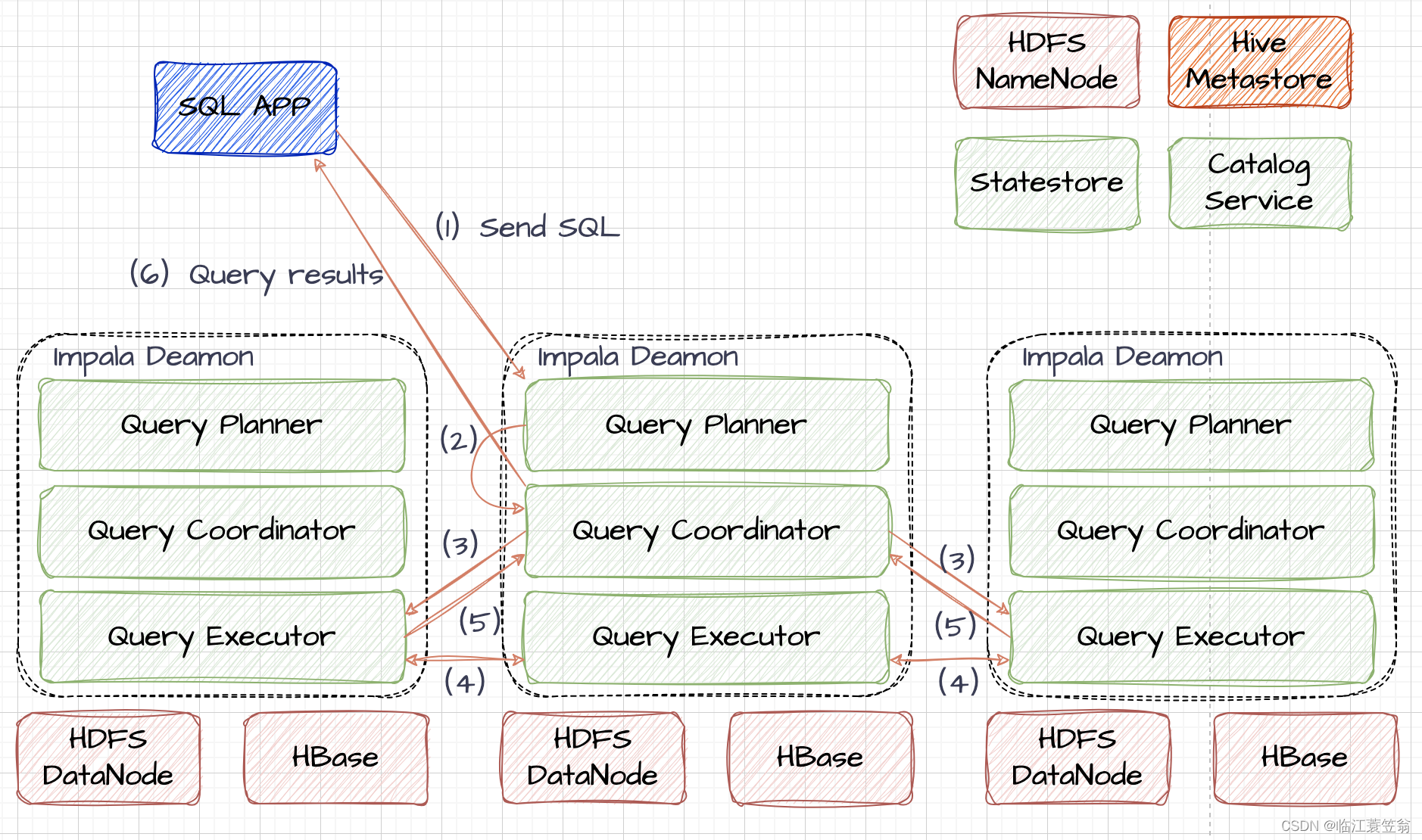
1.发起查询
客户端向Impala集群任意节点发送查询SQL语句
2.生成执行计划
Query Planner对查询语句进行解析生成解析树,然后将解析树变成执行计划。
3.分配任务
Query Coordinator根据执行计划和从Statestore获取的集群Daemon节点情况,将任务分配给Query Executor节点进行计算。
4.交换中间数据
Query Executor对计算的中间结果进行交换。
5.汇集结果
Query Coordinator从集群中的Query Executor节点拉取结果并进行汇集。
6.返回结果
Query Coordinator将汇总后的结果返回给客户端。
总结
Impala是大数据进行实时交互式分析查询的一个工具,没有依赖MapReduce执行任务,而是将任务分配到各个Impala节点进行计算和汇总,从而避免了MapReduce的启动时间。直接使用内存进行结果的保存减少了读写磁盘的时间。经过以上架构设计Impala的性能比Hive高出10到100倍,非常适用于即席查询和交互式分析场景。
参考链接
1.Apache Impala
2.Impala: A Modern, Open-Source SQL Engine for Hadoop
这篇关于Impala-架构与设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








