本文主要是介绍Python自动刷题 P2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用Python实现云豆网自动刷题 P2
只做学习交流,不做任何商业用途
不同于P1的漏洞,这次是题库爬到本地进行匹配
没有第一篇详细,主要讲讲思路传送门
集刷题和补全题库为一体

所有代码全是Py3
代码注释是#和// #是写码码时加的 //是写文章加的
大体思路
- 控制浏览器模拟点击
- 将题目和答案存进txt , 用正则匹配
- 将txt里题目和答案补全(来回爬…)
需要导入的模块
- from selenium import webdriver 控制浏览器用
-
- selenium下载地址
-
- chrome浏览器下载地址
-
- chromedrive
-
- 火狐drive
-
- edge_drive
-
- 推荐篇配置教程
- import time 控制程序暂停防止网络延迟出现错误
-
- py3内置模块不用下载
- 这些可以不用直接用input也行主要识别验证码
-
- from PIL import ImageGrab#截图用的
-
- import pytesseract #识别图片用的
-
- from PIL import Image
导入模块
from selenium import webdriver #控制浏览器用
import time #控制延时的
"""识图不想用下面不用导入 可以用input"""
from PIL import ImageGrab#截图用的
import pytesseract #识别图片用的
from PIL import Image
定义几个变量为了代码整洁
"""先定义几个变量为了代码的整洁"""
name = '123456789@suibian.com' #这里填入你的账户
password = '123' #这里填入你的密码
用selenium控制浏览器
dr = webdriver.Chrome() # 用浏览器打开
dr.maximize_window()#最大化浏览器 识图要用好固定验证码位置
dr.get('http://s.bdqn.cn/login')#打开网页
输入用户名密码验证码
截图识图部分
def image():from PIL import ImageGrabimport pytesseractfrom PIL import Imageimg = ImageGrab.grab(bbox=(1468, 610, 1604, 660))//验证码的位置 根据自己调整img.save('111.png')#保存成图片pytesseract.pytesseract.tesseract_cmd = 'C:\AAB\tesseract'//这里放安装tesseract的位置text = pytesseract.image_to_string(Image.open('111.png'))//读取图片识图并存储进变量中print(text)return text
验证码用的识图 改成 input也可以
dr.find_element_by_id('LoginForm_username').send_keys(name) # 用户"""识图部分"""
while True://注意这里的Truedr.find_element_by_id('LoginForm_password').send_keys(password) # 密码text=image()//如果不用识图改成下面这行//text=input('输入验证码: ')dr.find_element_by_id("LoginForm_verifyCode").send_keys(text[:4])//控制浏览器输入验证码time.sleep(0.2)dr.find_element_by_id("login").click()//点击登录time.sleep(2)#去找主页面一个id如果找得到就证明没有登录进去重新执行while,否则就证明进入新的界面break退出whiletry:error_message = dr.find_element_by_id("LoginForm_verifyCode_em_").textexcept:break
进入新页面
dr.implicitly_wait(10) # 每0.5秒一次一共10秒//隐式等待全局性的 意思是无论我多快都要等你10秒如果你提前跟上来就一起走 跟不上就自己走 ||||在这程序里跟不上就会报错/xk
try:dr.find_element_by_xpath('/html/body/div[2]/div/div/div/div[2]/div[2]/div[1]/form/ul/li[1]/a').click()#选择课程time.sleep(2)//延时看网速更改dr.find_element_by_xpath('/html/body/div/div/ul/li[4]').click()#点击'云题库'
except:input("手动点入界面后回车来退出\n\t在这里输入: ")
time.sleep(3)
题库界面—>答题界面
windows = dr.window_handles # 获取当前会话所有句柄
dr.switch_to.window(windows[-1]) # 定位到新窗口
dr.implicitly_wait(10)"""进入题库"""
dr.find_element_by_xpath('/html/body/div[3]/div[1]/div/div[2]/div/div[2]/span[4]/a').click()//点击课程复习性
time.sleep(0.5)
dr.find_elements_by_id('unitexam')[0].click()//进入试卷
"""下面这个不稳定因素 看网速调"""
time.sleep(2)
正 文
初始一些变量
sui_bian = 0 # 控制循环的
"""还是测试.....啊啊啊啊"""
while sui_bian < 100: //次数,随便改adds = [] # 用来记录序号addd = [] # 用来记录序号对应的正确答案add_to = {} # 用来添加新的编码和答案Indexes = 0 # 用作索引的dr
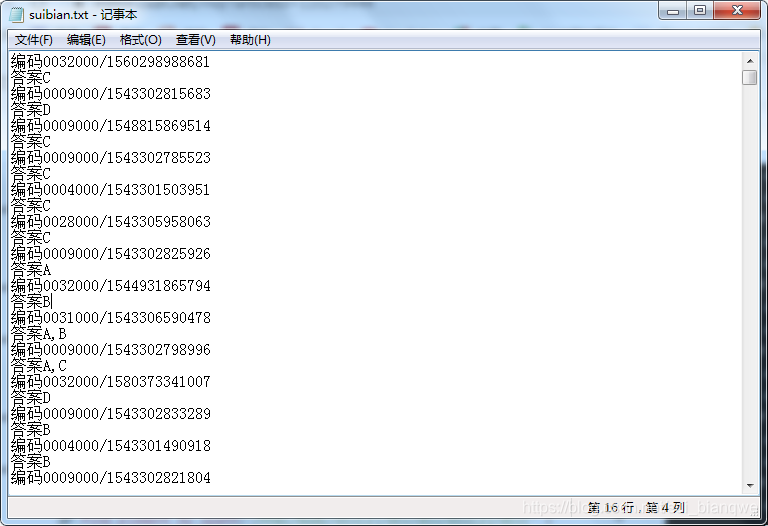
爬出图片地址, 再把txt里的地址和对应正确答案取出存好
try:reo = re.findall('relativePath=(\d*/\d*)', dr.page_source) # 正则表达式 取编码//在网页源码中提取图片的地址except: #云题库一次更新又出了新bug 得加上这些input("输入: ")reo = re.findall('relativePath=(\d*/\d*)', dr.page_source)print(reo)//下面在txt里拿出地址和对应正确答案with open(r'../suibian.txt', encoding='utf-8') as f:res = f.read()timu = re.findall('编码(.*?)\n', res)daan = re.findall('答案(.*?)\n', res)print(timu)print(daan)
这里重要
要把从网页中取出的图片地址 与txt比较找到对应的答案
受一大佬启发才写出这里,也许没大佬到死也完不成[万分感谢,向您鞠躬]
asls = []z = 1for i in reo: # 循环reo(存放图片位置的列表)并保存在i中if i in timu: # 判断i 在没在timu(就是存放所有编码的那个列表)asls.append(daan[timu.index(i)]) # 判断timu里的i(循环reo的)的位置并将对应位置去索引daan(存放<正确>答案的列表)将索引好的位置添加进asls里else:asls.append(str(z))//如果没有找到就执行这行 目的是标记方便寻找z += 1print(asls)
这些就比较简单 把上面剔出的正确答案填进去
//这东西也有优化的版本 就是不太稳,在下面贴出新的吗吗wzmzmfw = 2for i in asls:if i == "A":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[1]/pre').click()elif i == "B":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[2]/pre').click()elif i == "C":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[3]/pre').click()elif i == "D":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[4]/pre').click()elif i == "A,B":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[1]/pre').click()dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[2]/pre').click()elif i == "A,C":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[1]/pre').click()dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[3]/pre').click()elif i == "A,D":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[1]/pre').click()dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[4]/pre').click()elif i == "B,C":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[2]/pre').click()dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[3]/pre').click()elif i == "B,D":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[2]/pre').click()dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[4]/pre').click()elif i == "C,D":dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[3]/pre').click()dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[4]/pre').click()
- 视频效果
csdn用的→
这里目的是将错题的图片地址和错误序号存储进字典
else: # 文档中没有则会启动这个 <<<<主要在这里添加的>>>>dr.find_element_by_xpath('/html/body/div[2]/div/div/div[2]/div[' + str(wzmzmfw) + ']/ul/li[3]/pre').click()add = re.findall('<div class="sec2 grays Answer' + str(i) + '.>.*?relativePath=(\d*/\d*)',dr.page_source) # 用正则表达式爬取全部图片地址并保存在txt里里面大概就是['0078000/1543824395061','0078000/1543824395061']...这样的]try:#也是那个bug导致添加的add_to[add[-1]] = '' # 将爬到的图片地址存进字典里 值暂时空着except:print("多选没法避开")adds.append(i) # 将错误列号添加进去print("""写入txt中第{}题""".format(wzmzmfw-1))wzmzmfw += 1
交卷->查看解析(查看错题)
dr.find_element_by_xpath('//*[@id="putIn"]').click()time.sleep(0.2)dr.find_element_by_xpath('//*[@id="putInBtn"]').click()time.sleep(2)dr.find_element_by_xpath('//*[@id="closeReturnDialog"]').click()
也是那次bug加的,总是已经加载出所有东西就是不停转圈圈
dr.set_page_load_timeout(4)#设置超时try:dr.find_element_by_xpath('//*[@id="fixed"]/a[2]').click() # 点击那个分析的东东print("成功woc")#这gh玩意已经好久没见到了except:dr.execute_script("window.stop()")print("超时断开")time.sleep(3)
把存放错误题的字典处理好
for adds_z in adds: # 循环错误的列号再踢出没用的txt = re.findall('<div .*?> (.*?)</em>', dr.page_source) # 爬取全部正确答案 txt里面大概是["A","D","B"...这样的]addd.append(txt[int(adds_z) - 1]) # 用adds_z(没有答案的序号)索引txt(所有正确答案的abcd)添加到addd里去for code_a, answer_a in add_to.items(): # 循环addd_to并将键和值分别存储add_to[code_a] = addd[Indexes] # 更改值Indexes += 1
写入txt
write_in = open(r'./suibian.txt', 'a', encoding='utf-8') # 用可读写的权限打开txtfor code_a, answer_a in add_to.items(): # 同上一个for一样的道理write_in.write("编码" + code_a + "\n") # 存储正确的图片地址和正确答案write_in.write("答案" + answer_a + "\n") # 同上
210308更
-
尾巴
dr.find_element_by_xpath('//*[@id="againExam"]').click() # 点击在做一套time.sleep(3)sui_bian += 1
suibian()
。。。。。。。。。。。。正经分割线。。。。。。…。。。.。.。.。。。
很抱歉这篇隔了近一年才发
我错了,下次还敢

。。。。。。。。。。。。。。假装分割线。/xyx。。。。。。。。。。。
每个账号的图片地址都不一样
因为有这个, 如果有人会解请联系我,重谢

不过也别怕,我又有新思路了,一定更出来
一切只做学习与交流不作任何商业用途!!!
这篇关于Python自动刷题 P2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





