本文主要是介绍深度学习的activation function,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自:https://zhuanlan.zhihu.com/p/25110450
优先使用ReLU (Rectified Linear Unit) 函数作为神经元的activation function:
背景
深度学习的基本原理是基于人工神经网络,信号从一个神经元进入,经过非线性的activation function,传入到下一层神经元;再经过该层神经元的activate,继续往下传递,如此循环往复,直到输出层。正是由于这些非线性函数的反复叠加,才使得神经网络有足够的capacity来抓取复杂的pattern,在各个领域取得state-of-the-art的结果。显而易见,activation function在深度学习中举足轻重,也是很活跃的研究领域之一。目前来讲,选择怎样的activation function不在于它能否模拟真正的神经元,而在于能否便于优化整个深度神经网络。
下面我们简单聊一下各类函数的特点以及为什么现在优先推荐ReLU函数。
Sigmoid函数
Sigmoid函数是深度学习领域开始时使用频率最高的activation function。它是便于求导的平滑函数,其导数为,这是优点。然而,Sigmoid有三大缺点:
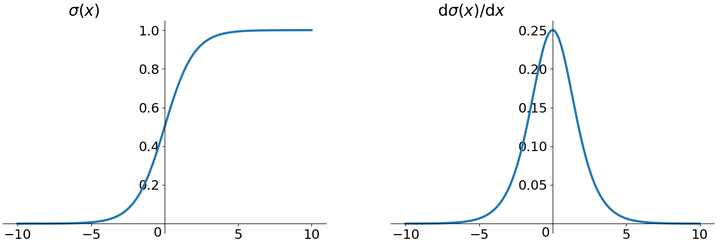 Sigmoid函数是深度学习领域开始时使用频率最高的activation function。它是便于求导的平滑函数,其导数为
Sigmoid函数是深度学习领域开始时使用频率最高的activation function。它是便于求导的平滑函数,其导数为- 容易出现gradient vanishing
- 函数输出并不是zero-centered
- 幂运算相对来讲比较耗时
优化神经网络的方法是Back Propagation,即导数的后向传递:先计算输出层对应的loss,然后将loss以导数的形式不断向上一层网络传递,修正相应的参数,达到降低loss的目的。 Sigmoid函数在深度网络中常常会导致导数逐渐变为0,使得参数无法被更新,神经网络无法被优化。原因在于两点:(1) 在上图中容易看出,当中较大或较小时,导数接近0,而后向传递的数学依据是微积分求导的链式法则,当前层的导数需要之前各层导数的乘积,几个小数的相乘,结果会很接近0 (2) Sigmoid导数的最大值是0.25,这意味着导数在每一层至少会被压缩为原来的1/4,通过两层后被变为1/16,…,通过10层后为1/1048576。请注意这里是“至少”,导数达到最大值这种情况还是很少见的。
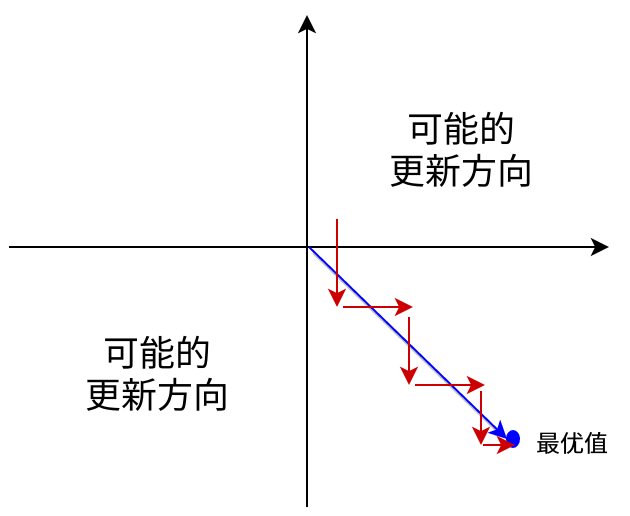
输出不是zero-centered
Sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。举例来讲,对,如果所有均为正数或负数,那么其对的导数总是正数或负数,这会导致如下图红色箭头所示的阶梯式更新,这显然并非一个好的优化路径。深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。
幂运算相对耗时
相对于前两项,这其实并不是一个大问题,我们目前是具备相应计算能力的,但面对深度学习中庞大的计算量,最好是能省则省 :-)。之后我们会看到,在ReLU函数中,需要做的仅仅是一个thresholding,相对于幂运算来讲会快很多。
tanh函数
tanh读作Hyperbolic Tangent,如上图所示,它解决了zero-centered的输出问题,然而,gradient vanishing的问题和幂运算的问题仍然存在。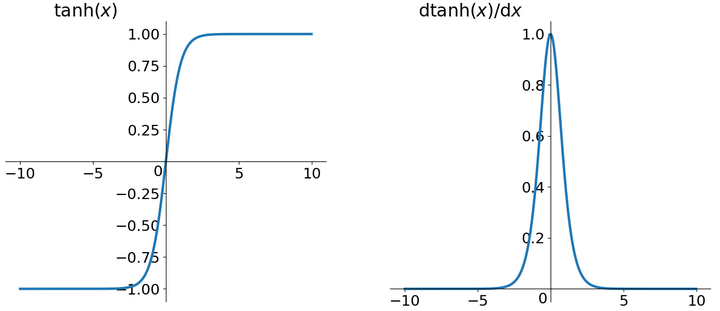 tanh读作Hyperbolic Tangent,如上图所示,它解决了zero-centered的输出问题,然而,gradient vanishing的问题和幂运算的问题仍然存在。
tanh读作Hyperbolic Tangent,如上图所示,它解决了zero-centered的输出问题,然而,gradient vanishing的问题和幂运算的问题仍然存在。 ReLU函数
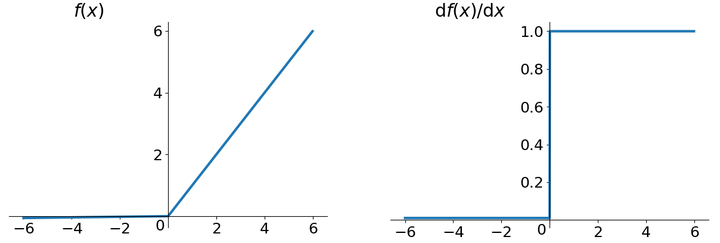
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
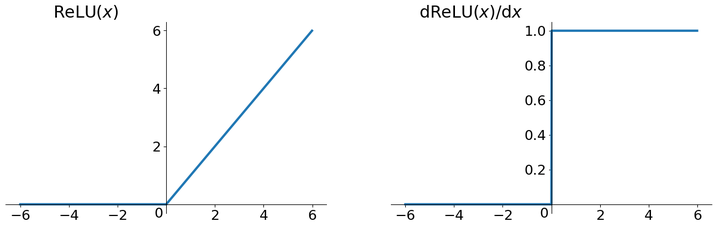 ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:
ReLU函数其实就是一个取最大值函数,注意这并不是全区间可导的,但是我们可以取sub-gradient,如上图所示。ReLU虽然简单,但却是近几年的重要成果,有以下几大优点:- 解决了gradient vanishing问题 (在正区间)
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度远快于sigmoid和tanh
- ReLU的输出不是zero-centered
- Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
Leaky ReLU函数
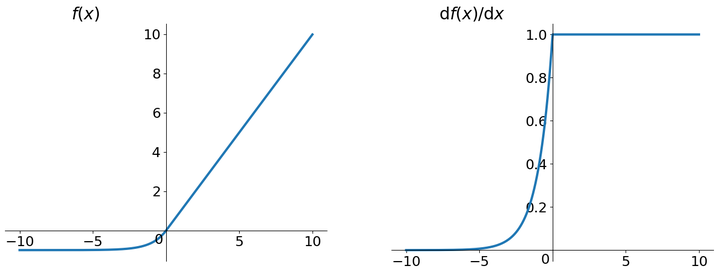
人们为了解决Dead ReLU Problem,提出了将ReLU的前半段设为而非0。另外一种直观的想法是基于参数的方法,即Parametric ReLU:,其中可由back propagation学出来。理论上来讲,Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
ELU (Exponential Linear Units) 函数
ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,以及:
- 不会有Dead ReLU问题
- 输出的均值接近0,zero-centered
小结
建议使用ReLU函数,但是要注意初始化和learning rate的设置;可以尝试使用Leaky ReLU或ELU函数;不建议使用tanh,尤其是sigmoid函数。
参考资料
- Udacity Deep Learning Courses
- Stanford CS231n Course
这篇关于深度学习的activation function的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





