本文主要是介绍Python-jenkins模块获取所有节点的概况信息(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍如何使用python-jenkins获取jenkins服务上所有节点的概况信息,重点关注节点名称、label、ip及连接状态。
执行结果:
[root@bogon /home/Sudley/python-jenkins]#python3 get_node_summary.py password
0::master::NA::NA::NA
1::test_node::test_slave::192.168.37.133::False
2::version_compile_baniryname_IP::version_baniryname::IP::True
[root@bogon /home/Sudley/python-jenkins]#
get_node_summary.py脚本源码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: Sudley
# ctime: 2020/1/05import sys
import jenkins
import xml.etree.ElementTree as ETdef get_nodes_summary(passwd):#获取nodes节点的name、label、ip、status(连接状态)username = 'sudley'password = passwdserver = jenkins.Jenkins('http://%s:%s@192.168.37.133:8081', username, password)nodes = server.get_nodes()for count in range(0,len(nodes)):node_name = nodes[count]['name']#print(node_name)#无法获取master的配置信息if node_name == 'master':node_label,node_ip,node_status = "NA","NA","NA"else:node_label,node_ip = get_node_label_and_ip(server,node_name)#print(node_label,node_ip)node_info = server.get_node_info(node_name)node_status = node_info['offline']print("%s::%s::%s::%s::%s"%(count,node_name,node_label,node_ip,node_status))def get_node_label_and_ip(server,node_name):try:node_config = server.get_node_config(node_name)except:print('get node_config failed')for i in range(0,2):f = open('/tmp/node_config.xml','w')f.write(node_config)f.write('\n')f.closetree = ET.parse('/tmp/node_config.xml')root = tree.getroot()try:node_label = root.find('label').textexcept:node_label = 'NA'try:for launcher in root.findall('launcher'):host = launcher.find('host')node_ip = host.textexcept:node_ip = 'NA'return node_label,node_ipif __name__ == '__main__' :passwd = sys.argv[1]get_nodes_summary(passwd)为了使用方便,可以绘制一个表格方便查看和管理节点
根据jenkins节点信息使用绘制表格(html格式)
后记:
不知道为什么需要写入两遍才能把数据保存到本地文件
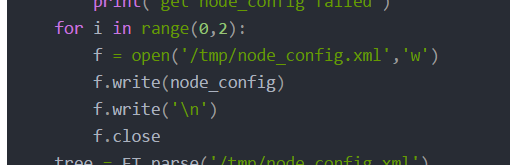
在这里使用with语句规避上述问题
with open('/tmp/node_config.xml','w') as f:f.write(node_config)f.write('\n')
这样可以避免打开的文件忘记关闭,而且只需要执行一次就能将数据成功保存到xml中。
这篇关于Python-jenkins模块获取所有节点的概况信息(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



