本文主要是介绍机器学习11-前馈神经网络识别手写数字1.0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这个示例中,使用的神经网络是一个简单的全连接前馈神经网络,也称为多层感知器(Multilayer Perceptron,MLP)。这个神经网络由几个关键组件构成:
1. 输入层
输入层接收输入数据,这里是一个 28x28 的灰度图像,每个像素值表示图像中的亮度值。
2. Flatten 层
Flatten 层用于将输入数据展平为一维向量,以便传递给后续的全连接层。在这里,我们将 28x28 的图像展平为一个长度为 784 的向量。
3. 全连接层(Dense 层)
全连接层是神经网络中最常见的层之一,每个神经元与上一层的每个神经元都连接。在这里,我们有一个包含 128 个神经元的隐藏层,以及一个包含 10 个神经元的输出层。隐藏层使用 ReLU(Rectified Linear Unit)激活函数,输出层使用 softmax 激活函数。
4. 输出层
输出层产生神经网络的输出,这里是一个包含 10 个元素的向量,每个元素表示对应类别的概率。softmax 函数用于将网络的原始输出转换为概率分布。
5. 编译模型
在编译模型时,我们指定了优化器(optimizer)和损失函数(loss function)。在这里,我们使用 Adam 优化器和稀疏分类交叉熵损失函数。
6. 训练模型
使用训练数据集对模型进行训练,以学习如何将输入映射到正确的输出。在训练过程中,模型通过优化损失函数来调整权重和偏置,使其尽可能准确地预测输出。
总的来说,这个神经网络是一个经典的多层感知器(MLP),它在输入层和输出层之间包含一个或多个隐藏层,通过学习逐步提取和组合特征来进行分类或回归任务。
代码:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten# 加载 MNIST 数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()# 数据预处理
train_images = train_images / 255.0
test_images = test_images / 255.0# 构建神经网络模型
model = Sequential([Flatten(input_shape=(28, 28)),Dense(128, activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(train_images, train_labels, epochs=5)# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)# 保存模型
model.save('mnist_model.h5')# 加载模型
loaded_model = tf.keras.models.load_model('mnist_model.h5')# 使用加载的模型进行预测
predictions = loaded_model.predict(test_images)
结果:
Epoch 1/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.2586 - accuracy: 0.9265
Epoch 2/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.1136 - accuracy: 0.9656
Epoch 3/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.0773 - accuracy: 0.9768
Epoch 4/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.0587 - accuracy: 0.9823
Epoch 5/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0462 - accuracy: 0.9855
313/313 [==============================] - 0s 1ms/step - loss: 0.0750 - accuracy: 0.9775
Test accuracy: 0.9775000214576721
识别准确率挺高,然后我们也得到了训练好的模型。
应用测试:
import tensorflow as tf
import numpy as np
from PIL import Image# 加载保存的模型
loaded_model = tf.keras.models.load_model('mnist_model.h5')# 打开手写图片文件
image_path = 'pic/handwritten_digit_thick_5.png' # 修改为你的手写图片文件路径
image = Image.open(image_path).convert('L') # 转换为灰度图像# 调整图片大小为 28x28 像素
image = image.resize((28, 28))# 将图片转换为 NumPy 数组并进行归一化处理
image_array = np.array(image) / 255.0# 将图片转换为模型输入的格式(添加批次维度)
input_image = np.expand_dims(image_array, axis=0)# 使用模型进行预测
predictions = loaded_model.predict(input_image)# 获取预测结果(最大概率的类别)
predicted_class = np.argmax(predictions)print('Predicted digit:', predicted_class)
准备了4张图片,3张自己手写,1张摘自minst:

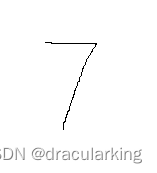


前两张画笔比较细,第三张是minst的5,第四张是用了粗笔自己写的5,最终结果是就minst预测对了。
Predicted digit: 2
Predicted digit: 8
Predicted digit: 5
Predicted digit: 3
结论:
可见这个模型的扩展适应性能还是不够,只能预测正确训练过的minst数字。
改进:
想办法提升训练的质量,让预测能力达标。
这篇关于机器学习11-前馈神经网络识别手写数字1.0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






