本文主要是介绍追前沿,领略SET化架构衍化与设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BAT/TMD大厂单元化架构设计衍变之路分享
随着大型互联网公司业务的多元化发展,就拿滴滴、美团等大厂来讲,如滴滴打车、单车、外卖、酒店、旅行、金融等业务持续高速增长,单个大型分布式体系的集群,通过加机器+集群内部拆分(kv、mq、Mysql等),虽然具备了一定的可扩展性。但是,随着业务量的进一步增长,这个集群规模琢渐变的巨大,从而一定会在某个点达到瓶颈,无法满足扩展性需要,并且大集群内核服务出现问题,会影响全网所有用户。
-
以滴滴打车、美团外卖举例来说:
打车业务体量巨大,尤其在早晚高峰期。全年订单量已越10亿。
外卖业务体量庞大,目前单量突破1700w/天,对应如此庞大的单个大型分布式集群,会面临一下问题:- 容灾问题
- 资源扩展性问题
- 大集群拆分问
容灾问题
核心服务(比如订单服务)挂掉,会影影响全网所有的用户,导致整个业务不可用;
数据库主库集中在一个IDC,主机房挂掉,会影响全网所有用户,整个业务无法快速切换和恢复资源扩展问题
单IDC的资源(机器、网络带宽等)已经没法满足,扩展IDC时,存在跨机房访问延时问题(增加异地机房,时延问题严重);
数据库主库单点,连接数有限,不能支持应用程序的持续发展;大集群拆分问题
核心问题:分布式集群规模扩大后,会响应的带来资源扩展、大集群拆分以及容灾问题
所有处于对业务扩展性以及容灾需求的考虑,我们需要一套从底层架构彻底解决问题的方案,业界主流解决方案:
SET单元化架构方案(阿里、支付宝、饿了么、微信等)
-
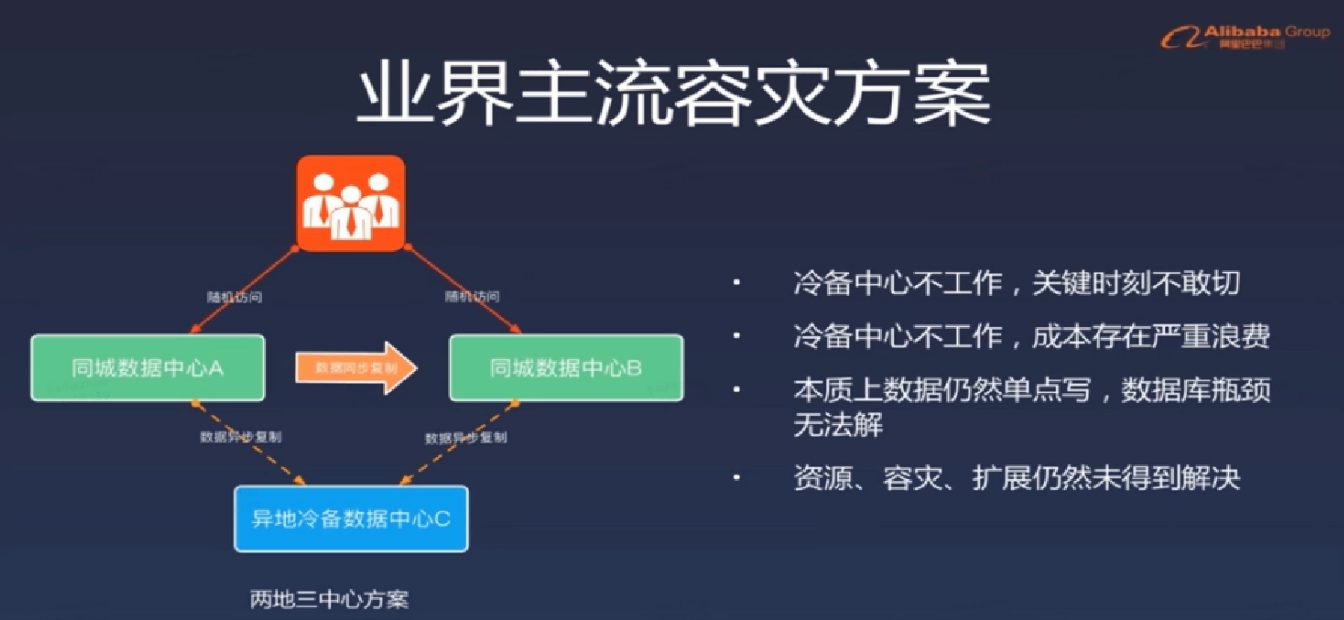
同城 "双活" 架构介绍
目前很多大型互联网公司的业务架构可以理解为同城"双活"架构,注意这里的“双活"是加引号的,具体可以这样理解:- 业务层面上已经做到的真正的双活(或者多活),分别承担部分流量;
- 存储层面比如定时任务、缓存、持久层、数据分析等都是主从架构,会有跨机房写的问题;
- 一个数据中心故障,可以手动切换流量,部分组件可以自动切换;
-
两地三中心架构介绍
使用灾备的思想,在同城“双活”的基础上,在异地部署一套灾备数据中心,每个中心都具有完备的数据处理能力,只有当主节点故障需要容灾时才会紧急启动备用数据中心;
SET化方案目标:
业务:解决业务遇到的扩展性和容灾等需求,支撑业务的高速方案
通用性:架构侧形成统一通用的解决方案,方面各业务线接入使用
SET化架构设计:
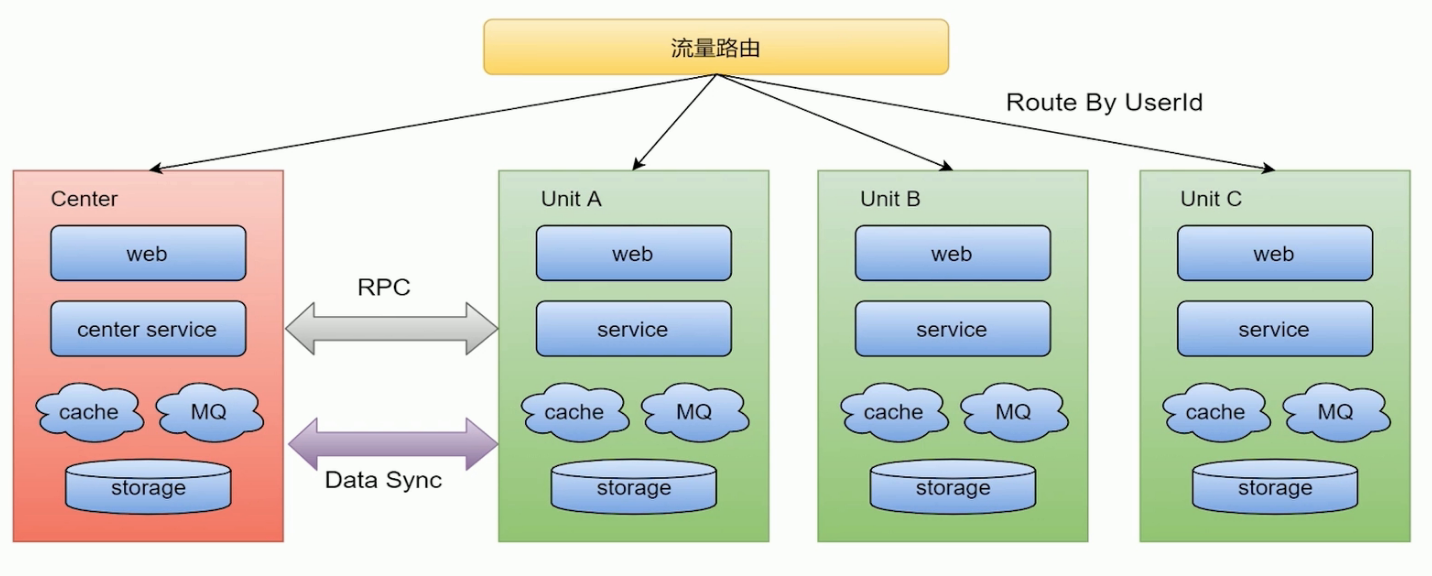
SET化架构策略
流量路由:
- 按照特殊的key(通常为userid)进行路由,判断某次请求该路由到中心集群还是单元化集群;
中心集群:
- 为进行单元化改造的服务(通常不在核心交易链路,比如供应链系统)称为中心集群,跟当前架构保持一致。
单元化集群:
- 每个单元化集群只负责本单元内的流量处理,以实现流量拆分以及故障隔离;
- 每个单元化集群前期只存储本单元产生的交易数据,后续会做双向数据同步,实现容灾切换需求;
中间件(RPC、KV、MQ等):
- RPC:对于SET服务,调用封闭在SET内;对于非SET服务,沿用现有的路由逻辑;
- KV:支持SET的数据生产和查询;
- MQ:支持分SET的消息生产和消费;
数据同步:
- 全局数据(数据量小且变化不大,比如商家的菜品数据)部署在中心集群,其他单元化集群同步全局数据到本单元化内;
- 未来演变为异地多活架构时,各单元化集群数据需要进行双向同步来实现容灾需要
异地容灾:
- 通过SET化架构的流量调度能力,将SET分别部署在不同地区的数据中心,实现跨地区容灾支持
高效的本地化服务:
- 利用前端位置信息采集和域名解析策略,将流量路由到最近的SET,提供最高效的本地化服务;
- 比如O2O场景天然具有本地生产,本地消费的特点,更加需要SET化支持
集装箱扩展:
- SET的封装性支持更灵活的部署扩展性,比如SET一键创建/下线,SET一键发布等。
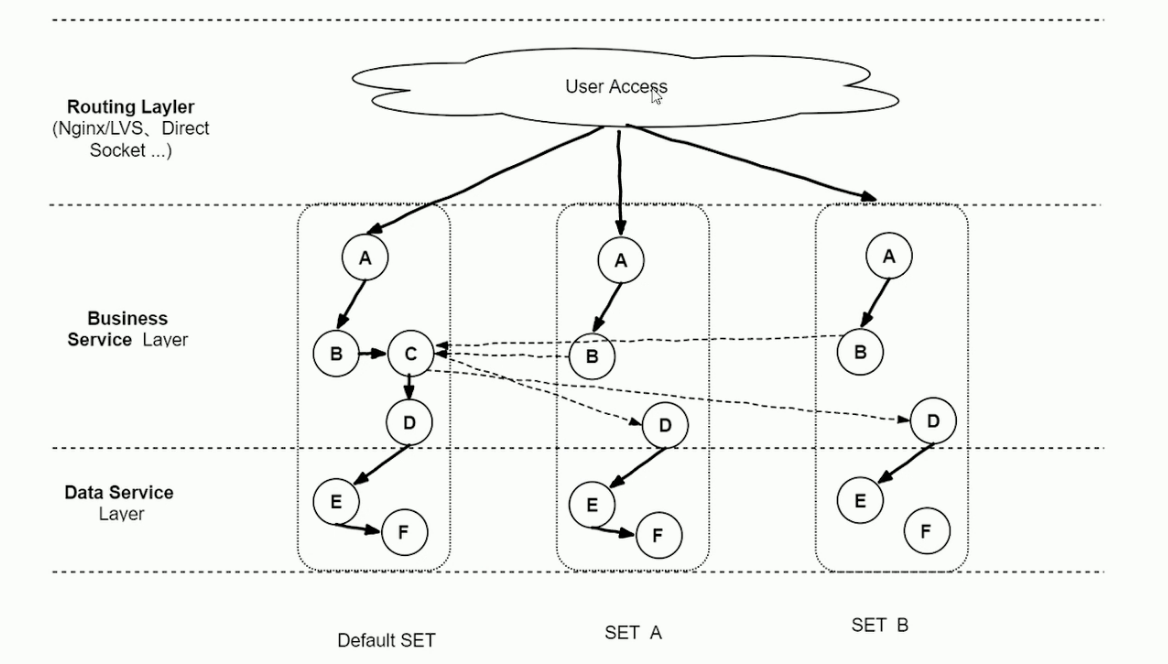
SET化架构落地原则
对业务透明原则:
SET化架构的实现对业务代码透明,业务代码层面不需要关系SET化规则,SET的部署等问题SET化切分的规则:
理论上,切分规则有业务层面按需定制;
实际上,建议优先选最大的业务维度进行切分;
比如海量用户的O2O业务,按用户位置信息进行切分。此外接入层、逻辑层和数据层可以由独立的SET切分规则,有利于实现部署和运维成本的最优化部署规范原则:
一个SET并不一定只限制在一个机房,也可以跨机房或者跨地区部署;为保证灵活性,单个SET内机器数不宜过多(如不超过1000台物理机)。
RabbitMQ-SET化架构实现
-
SET化消息中间件架构实现(RabbitMQ双活):
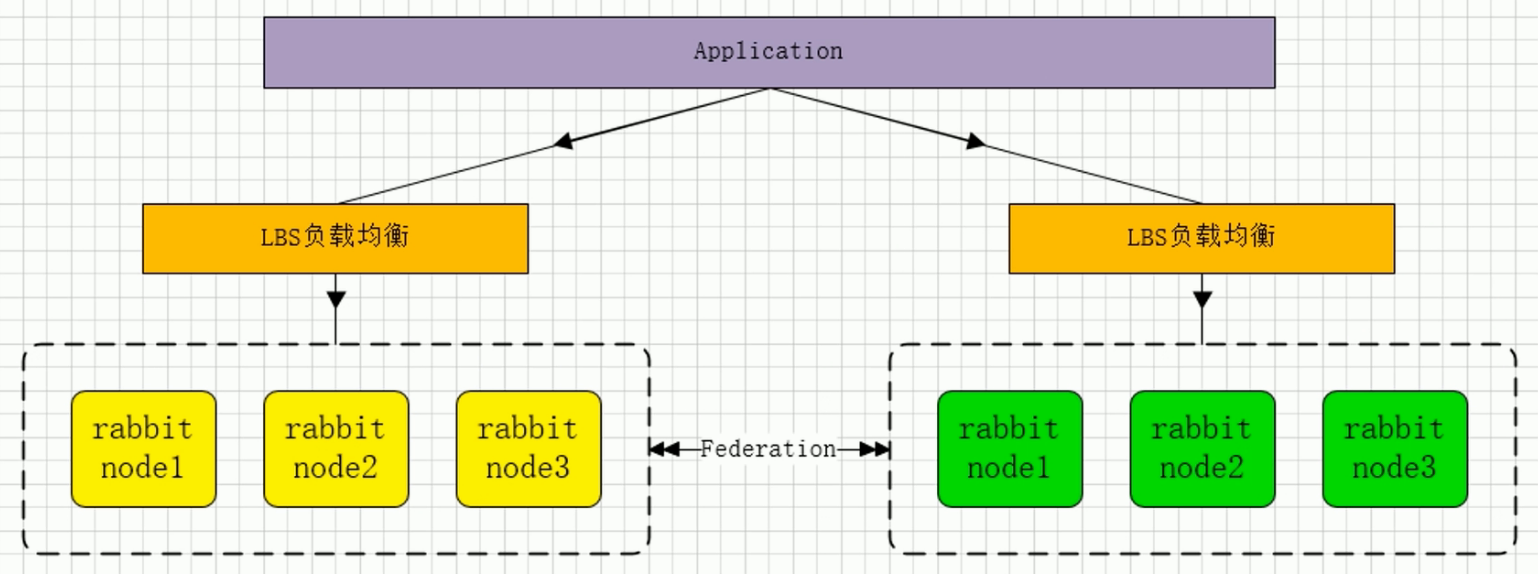
使用RabbitMQ异步消息通信插件 Federation(节点和节点、集群和集群之间通信) 安装与配置:
安装插件
rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_federation_management
备注:当你再一个cluster钟使用了federation插件,所有在集群中的 nodes都需要安装federation插件
使用RabbitMQ通信插件Rederation:
Federation插件是一个在不需要cluster进行数据同步的(选择一个cluster中的节点和另一个cluster节点同步),而brokers之间传输消息的高新性能插件。Federation插件可以在brokers或者cluster之间传输消息,链接的双方可以使用不同的users和virtual hosts、或者双方的rabbitmq和erlang版本不一致,federation插件使用AMQP协议通信,可以接受不连续的传输。
-
SET化配置规则:
第一,Federation Exchanges,可以看成Downstream(82节点)从Upstream(81节点)主动拉取消息,并不是拉取所有消息,必须是在Downstream上已经明确定义Bindings关系的Exchange,也就是有实际的物理Queue来接收消息,才会从Upstream拉取消息到Downstream。使用AMQP协议实施代理间通信,Downstream会将绑定关系组合在一起,绑定/解绑命令将发送到Upstream交换机。
-
第二,经过配置后,Upstream节点已经可以把消息直接通过Federation Exchanges路由给我们的Downstream节点,然后进行消费。
也就是说可以实现消息的转发,接下来也可以在Upstream添加具体的队列去进行消费Federation Exchanges里的消息,我们一条消息分别发送到2个RabbitMQ集群并且消费,这样我们可以实现SET化的关键要素,就是集群间的消息同步了。
第三,可以根据自己的业务规则去规划不同的集群去监听不同的消息队列,从而达到SET化的手段,保障了性能、可靠性、数据一致性。
这篇关于追前沿,领略SET化架构衍化与设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






