本文主要是介绍【Python 3 爬虫学习笔记】使用Python3 爬取猫眼《西虹市首富》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自微信公众号《数据森麟》
直接上代码:
# 调用相关包
import json
import random
import requests
import time
import pandas as pd
import os
from pyecharts import Bar, Geo, Line, Overlap
import jieba
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from collections import Counter# 设置headers和cookie
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win32; x32; rv:54.0) Gecko/20100101 Firefox/54.0','Connection': 'keep-alive'
}
cookies = '你的Cookies'
cookie = {}
for line in cookies.split(';'):name, value = cookies.strip().split('=', 1)cookie[name] = value# 爬取数据
tomato = pd.DataFrame(columns=['data', 'score', 'city', 'comment', 'nick'])
for i in range(0, 1000):j = random.randint(1, 1000)print(str(i) + ' ' + str(j))try:time.sleep(2)url = 'http://m.maoyan.com/mmdb/comments/movie/1212592.json?_v_=yes&offset=' + str(j)html = requests.get(url=url, cookies=cookie, headers=headers).contentdata = json.loads(html.decode('utf-8'))['cmts']for item in data:tomato = tomato.append({'data': item['time'].split(' ')[0],'city': item['cityName'],'score': item['score'],'comment': item['content'],'nick': item['nick']}, ignore_index=True)tomato.to_excel('西虹市首富.xlsx', index=False)except:continue# 可以直接读取已经爬取的数据进行分析
tomato_com = pd.read_excel('西虹市首富.xlsx')
grouped = tomato_com.groupby(['city'])
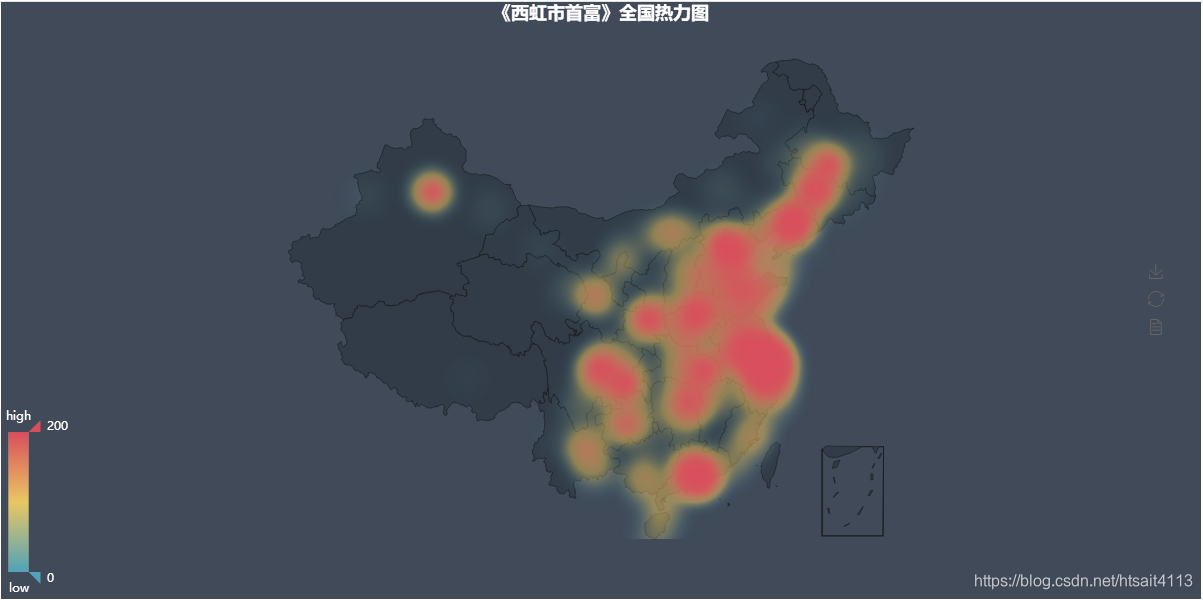
grouped_pct = grouped['score']# 全国热力图
city_com = grouped_pct.agg(['mean', 'count'])
city_com.reset_index(inplace=True)
city_com['mean'] = round(city_com['mean'], 2)
data = [(city_com['city'][i], city_com['count'][i]) for i in range(0, city_com.shape[0])]
geo = Geo('《西虹市首富》全国热力图', title_color="#fff",title_pos="center", width=1200, height=600, background_color='#404a59')
attr, value = geo.cast(data)
geo.add("", attr, value, type="heatmap", visual_range=[0, 200],visual_text_color="#fff", symbol_size=10, is_visualmap=True,is_roam=False)
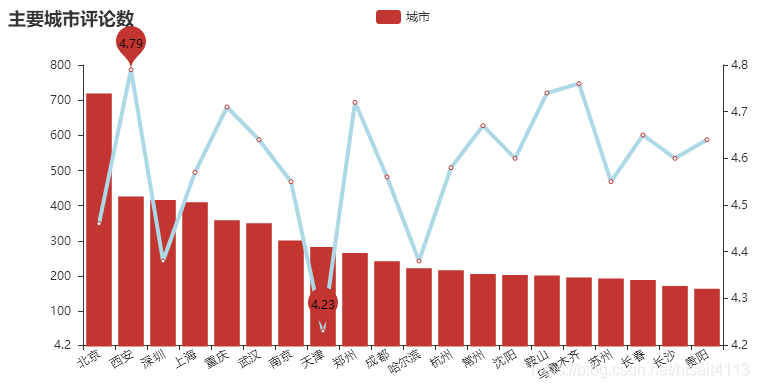
geo.render('西虹市首富.html')# 主要城市评论数与评分
city_main = city_com.sort_values('count', ascending=False)[0:20]
attr = city_main['city']
v1 = city_main['count']
v2 = city_main['mean']
line = Line("主要城市评分")
line.add("城市", attr, v2, is_stack=True, xaxis_rotate=30, yaxis_min=4.2,mark_point=['min', 'max'], xaxis_interval=0, line_color='lightblue',line_width=4, mark_point_textcolor='black', mark_point_color='lightblue',is_splitline_show=False)
bar = Bar("主要城市评论数")
bar.add("城市", attr, v1, is_stack=True, xaxis_rotate=30, yaxis_min=4.2,xaxis_interval=0, is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.add(line, yaxis_index=1, is_add_yaxis=True)
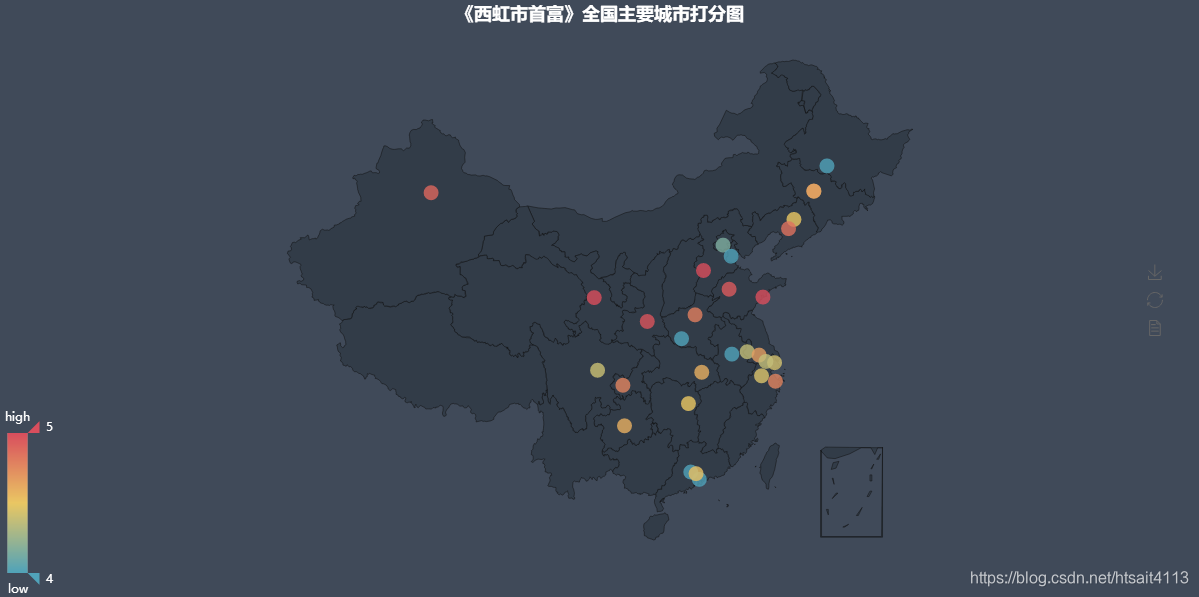
overlap.render('主要城市评论数_平均分.html')# 主要城市评分全国分布
city_score_area = city_com.sort_values('count', ascending=False)[0:30]
city_score_area.reset_index(inplace=True)
data = [(city_score_area['city'][i], city_score_area['mean'][i]) for i in range(0, city_score_area.shape[0])]
geo = Geo('《西虹市首富》全国主要城市打分图', title_color="#fff", title_pos="center",width=1200, height=600, background_color='#404a59')
attr, value = geo.cast(data)
geo.add("", attr, value, visual_range=[4.4, 4.8],visual_text_color="#fff", symbol_size=15, is_visualmap=True, is_roam=False)
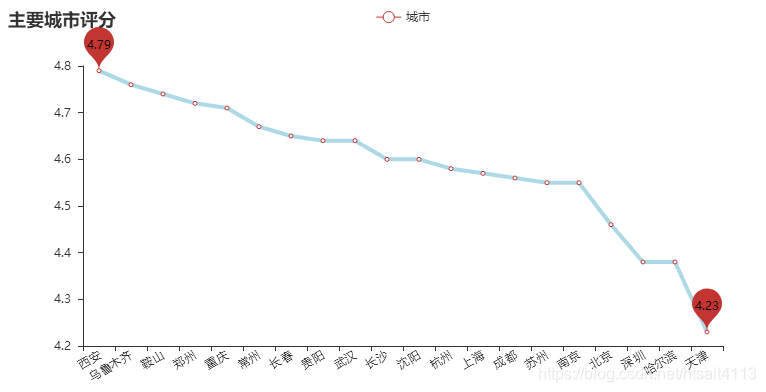
geo.render('西虹市首富全国主要城市打分图.html')# 主要城市评分降序
city_score = city_main.sort_values('mean', ascending=False)[0:20]
attr = city_score['city']
v1 = city_score['mean']
line = Line("主要城市评分")
line.add("城市", attr, v1, is_stack=True, xaxis_rotate=30, yaxis_min=4.2, mark_point=['min', 'max'], xaxis_interval=0,line_color='lightblue', line_width=4, mark_point_textcolor='black',mark_point_color='lightblue', is_splitline_show=False)
line.render('主要城市评分.html')# 绘制词云
tomato_str = ' '.join(tomato_com['comment'])
words_list = []
word_generator = jieba.cut_for_search(tomato_str)
for word in word_generator:words_list.append(word)
words_list = [k for k in words_list if len(k)>1]
back_color = imread('西红柿.jpg')
wc = WordCloud(background_color='white',max_words=200,mask=back_color,max_font_size=300,font_path="C:/Windows/Fonts/SimHei.ttf",random_state=42,)
tomato_count = Counter(words_list)
wc.generate_from_frequencies(tomato_count)
image_colors = ImageColorGenerator(back_color)
plt.figure()
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
plt.savefig('wordcloud.png', dpi=200)
plt.show()

这篇关于【Python 3 爬虫学习笔记】使用Python3 爬取猫眼《西虹市首富》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



