本文主要是介绍深度学习方法(十一):卷积神经网络结构变化——Google Inception V1-V4,Xception(depthwise convolution),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld。
技术交流QQ群:433250724,欢迎对算法、机器学习技术感兴趣的同学加入。
上一篇讲了深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling,本篇讲一讲Google的Inception系列net,以及还是Google的Xception。(扯一下,Google的Researcher们还是给了很多很棒的idea的,希望读者朋友和我自己在了解paper之余,可以提出自己的想法,并实现。)
如果想看Xception,就直接拉到最后看,有手画示意图。
Inception V1-V4
Inception V1:
V1是大家口头说的Googlenet,在之前的深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning有简单介绍,这里再凝练一下创新点:
图1

要想提高CNN的网络能力,比如分类准确率,一般的想法就是增大网络,比如Alexnet确实比以前早期Lenet大了很多,但是纯粹的增大网络——比如把每一层的channel数量翻倍——但是这样做有两个缺点——参数太多容易过拟合,网络计算量也会越来越大。
以下重点:目前很多工作证明,要想增强网络能力,可以:增加网络深度,增加网络宽度;但是为了减少过拟合,也要减少自由参数。因此,就自然而然有了这个第一版的Inception网络结构——同一层里面,有卷积1* 1, 3* 3,5* 5 不同的卷积模板,他们可以在不同size的感受野做特征提取,也算的上是一种混合模型了。因为Max Pooling本身也有特征提取的作用,而且和卷积不同,没有参数不会过拟合,也作为一个分支。但是直接这样做,整个网络计算量会较大,且层次并没有变深,因此,在3*3和5*5卷积前面先做1*1的卷积,降低input的channel数量,这样既使得网络变深,同时计算量反而小了;(在每一个卷积之后都有ReLU)
Inception V2-V3:
V2和V3版本比较接近,就不绝对区分了,具体可以看[3]。讲一讲其中的创新点:
首先,用两层堆叠的3*3代替了一层5*5,我们可以看到,这样做参数量少了,计算量少了,但是层数变深了,效果也变好了:
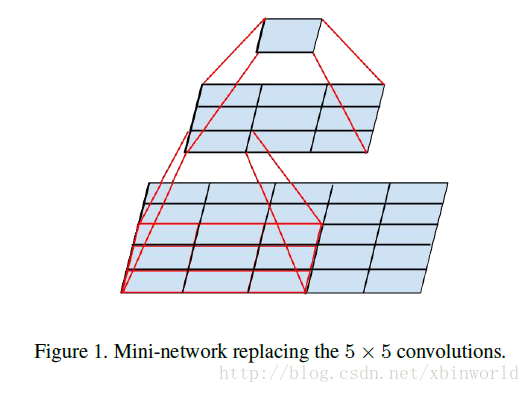
用1*3和3*1卷积替代3*3卷积,计算量少了很多,深度变深,思路是一样的。(实际上是1*n和n*1替代n*n,n可以变)

放到Inception结构里,下面是原始的Inception

下面图5-6-7是改进版本:



总体的网络结构:

我们看到,Inception并不是全程都用,是在图像比较小了采用,并且,图5-6-7的结构是依次用的,他们适合不同size的图像。
Inception V4:
v4研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能 [7]
Inception-resnet-v1 and Inception-ResNet v2都是用的这个结构图,区别在于下图的注释中,

这篇文章通篇就是各种微结构变化,我在这里贴也没什么意思,希望读者移步论文[4],找到对应的图号,看一下。


其实我也有疑惑,虽然paper总可以说出一些道道,结果也确实有一定提升,但是对于不同层设计了完全不同的微结构,这样会不会模式上太不统一了?有没有用更简洁统一的方式,达到一样的效果呢?我相信是有的,自我感觉Inception V1的模式很简单,Resnet的跳层结构也很简单,美,但是到了V4这里,结构变化太多,很难理解为什么是必须的呢?**
就好比我们以前做电影推荐比赛,最终获胜的结果往往是多模型混合,但是我个人还是最感兴趣那个最最有效果的单模型是什么样的。
Xception
非常新的一个工作[5],前面讲了那么多Inception网络,那么Inception网络的极限是什么呢?其中一个极限版本如下:

在1*1卷积之后,对每一个channel,做3*3的*1的独立卷积,然后再concat。认为每一个spatial conv对cross channel feature是没有关系的。
[5]作者提出了Depthwise Separable Convolution,或者简称Depthwise Convolution,是下面这个样子:先做channel-wise conv,然后再过1*1卷积,中间没有ReLU,最后有ReLU。

上面提到两种结构的区别,文中这一段写的很清楚:

整个网络结构:

OK,本篇到这里,只是作为一个记录和引导,让大家发现更多结构设计的idea。
参考资料
下面参考资料部分paper还带了test error
[1] Going Deeper with Convolutions, 6.67% test error
http://arxiv.org/abs/1409.4842
[2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error
http://arxiv.org/abs/1502.03167
[3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error
http://arxiv.org/abs/1512.00567
[4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error
[5] Xception: Deep Learning with Depthwise Separable Convolutions
[6] 深入浅出——网络模型中Inceptionv1到 v4 的作用与结构全解析
[7] Inception in CNN
[8] 论文笔记 | Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
这篇关于深度学习方法(十一):卷积神经网络结构变化——Google Inception V1-V4,Xception(depthwise convolution)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




