本文主要是介绍Python爬取前程无忧职位信息,保存成Excel文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取网页的方式:re
url="https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html"
a = urllib.request.urlopen(url)
html = a.read().decode('gbk')
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)" href="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)" href="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*?<span class="t5">(.*?)</span>.*?',re.S)#匹配换行符
items=re.findall(reg,html)
item是得到的所有数据组成的列表,里面含多个元组
爬取网页的方式:xpath
url="https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html"
res = requests.get(url).text
s = etree.HTML(res) # 将源码转化为能被 XPath 匹配的格式
#然后
requir = s.xpath(' 此处输从网页中复制的xpath或者自己写的索引 /text()')
完整代码如下:
采用输入方式
想要查看啥职位就输入啥
# -*- coding:utf-8 -*-
import urllib.request
import xlwt
import re
import urllib.parse
from lxml import etree
import requests#模拟浏览器
header={'Host':'search.51job.com','Referer':'https://mkt.51job.com/tg/sem/pz_2018.html?from=baidupz','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) 37abc/2.0.6.16 Chrome/60.0.3112.113 Safari/537.36'
}def getfront(page,item):result = urllib.parse.quote(item)ur1 = result+',2,'+ str(page)+'.html'ur2 = 'http://search.51job.com/list/000000,000000,0000,00,9,99,'res = ur2+ur1a = urllib.request.urlopen(res)html = a.read().decode('gbk') # 读取源代码并转为unicodereturn htmldef getInformation(html):reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)" href="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)" href="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*?<span class="t5">(.*?)</span>.*?',re.S)#匹配换行符items=re.findall(reg,html)return itemsexcel1 = xlwt.Workbook()
# 设置单元格
sheet1 = excel1.add_sheet('Job', cell_overwrite_ok=True)
sheet1.write(0, 0, '序号')
sheet1.write(0, 1, '职位')
sheet1.write(0, 2, '公司名称')
sheet1.write(0, 3, '公司地点')
sheet1.write(0, 4, '公司性质')
sheet1.write(0, 5, '薪资')
sheet1.write(0, 6, '学历要求')
sheet1.write(0, 7, '工作经验')
sheet1.write(0, 8, '公司规模')
sheet1.write(0, 9, '公司类型')
sheet1.write(0, 10,'公司福利')
sheet1.write(0, 11,'发布时间')
sheet1.write(0, 12,'任职要求')number = 1
item = input()
for j in range(1,1049):try:print("正在爬取第"+str(j)+"页数据...")html = getfront(j,item) #调用获取网页原码for i in getInformation(html):try:url1 = i[1]url2 = i[3]res1 = requests.get(url1).textres2 = requests.get(url2).texts1 = etree.HTML(res1) # 将源码转化为能被 XPath 匹配的格式s2 = etree.HTML(res2)persons = s2.xpath('/html/body/div[2]/div[2]/div[2]/div/p[1]/text()')[1].strip()comyany_avlue = s2.xpath('/html/body/div[2]/div[2]/div[2]/div/p[1]/text()')[0].strip()experience = s1.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()')[1].strip()education = s1.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()')[2].strip()comyany_type = s2.xpath('/html/body/div[2]/div[2]/div[2]/div/p/a/text()')welface = re.findall(re.compile(r'<span class="sp4">(.*?)</span>',re.S),res1)requir = s1.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p/text()')print(i[0],i[2],i[4],i[5],comyany_avlue,experience,education,persons,comyany_type,welface,i[6])sheet1.write(number,0,number)sheet1.write(number,1,i[0])sheet1.write(number,2,i[2])sheet1.write(number,3,i[4])sheet1.write(number,4,comyany_avlue)sheet1.write(number,5,i[5])sheet1.write(number,6,education)sheet1.write(number,7,experience)sheet1.write(number,8,persons)sheet1.write(number,9,comyany_type)sheet1.write(number,10,(" ".join(str(i) for i in welface)))sheet1.write(number,11,i[6])sheet1.write(number,12,requir)number+=1;except:passexcept:passexcel1.save("51job.xls")
爬取数据时两种方法都使用过
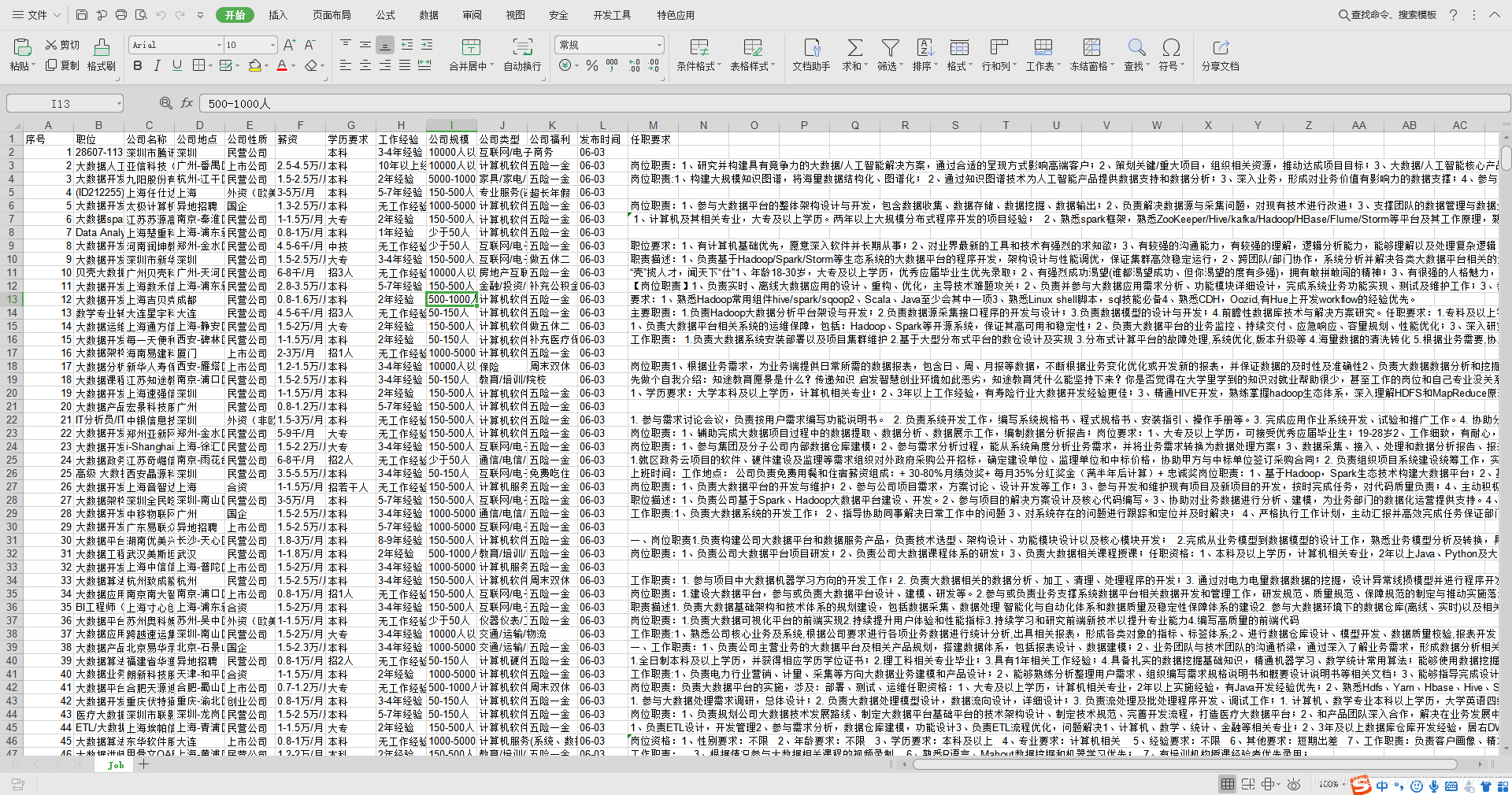
这篇关于Python爬取前程无忧职位信息,保存成Excel文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





