本文主要是介绍【Python基础】案例分析:泰坦尼克分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
泰坦尼克分析
1 目的:
- 熟悉数据集
- 熟悉seaborn各种操作作
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
home = r'data'
df = sns.load_dataset('titanic', data_home=home)
df.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
2 数据整理
- 缺省值统计
- 缺省值处理:删除或补齐
- 数据二次处理
2.1 统计缺省值计缺省值
df.isnull().sum()
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
2.2 删除与填充
- 删除deck列
pdata = df.drop('deck', axis=1)
pdata.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | Southampton | no | True |
- 年龄使用均值填充
#填充均值
pdata = pdata.fillna(pdata.mean(numeric_only=True)) #Notes:添加numeric_only=True只对数字做处理
#年龄分类
pdata['age_level'] = pd.cut(pdata.age,bins = [0,18,60,100], labels=['child','mid', 'old'])
pdata.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | embark_town | alive | alone | age_level | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | Southampton | no | False | mid |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | Cherbourg | yes | False | mid |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | Southampton | yes | True | mid |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | Southampton | yes | False | mid |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | Southampton | no | True | mid |
3 数据统计
3.1 基础数据统计
- 年龄分布
- 船舱人数分布
- 男女分布
- 团队人数分布
年龄较分散,使用直方图进行展示方图进行展示
sns.distplot(pdata.age)
UserWarning: `distplot` is a deprecated function and will be removed in seaborn v0.14.0.Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751sns.distplot(pdata.age)<AxesSubplot: xlabel='age', ylabel='Density'>

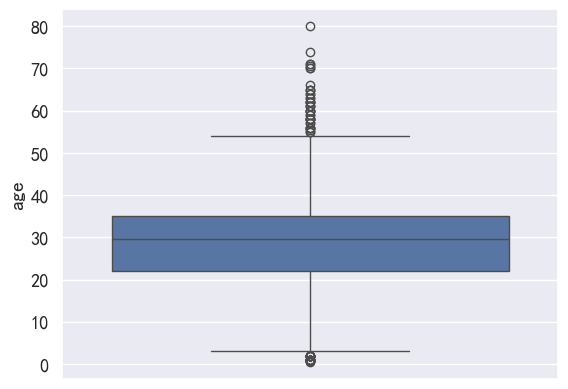
sns.boxplot(pdata.age)
<AxesSubplot: ylabel='age'>
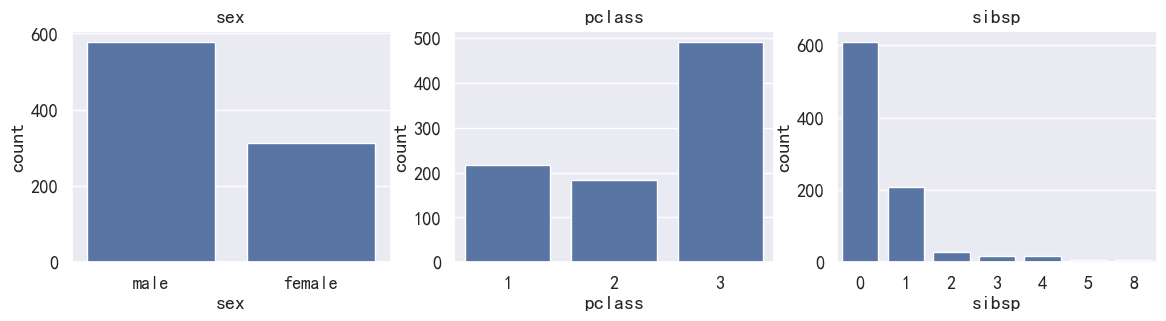
船舱人数,男女人数,团队人数(1个人,两个人,三个人对应的数量)使用柱状图进行展示
cols = ['sex', 'pclass', 'sibsp']
lens = len(cols)
plt.figure(figsize=(14,3))
for index, col in enumerate(cols):plt.subplot(1, lens,index+1)ax = sns.countplot(x=col, data=pdata)ax.set_title(col)
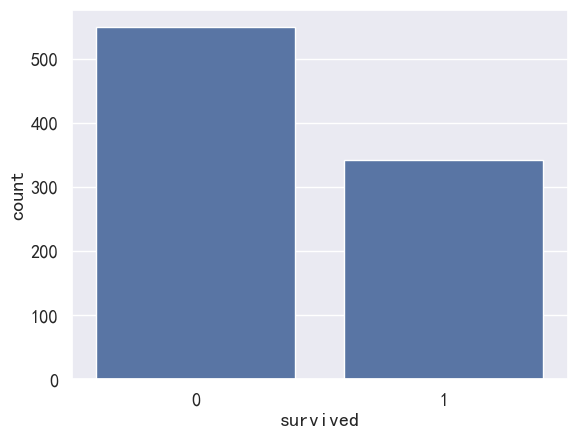
3.2 获救数据
- 获救人数与遇难人数
- 根据性别,统计获救与遇难人数
- 根据年龄段,统计获救与遇难人数
- 根据年龄段,性别,统计获救与遇难人数
- 根据年龄段,性别,船舱,统计获救与遇难人数
sns.countplot(x='survived', data=pdata)
<AxesSubplot: xlabel='survived', ylabel='count'>
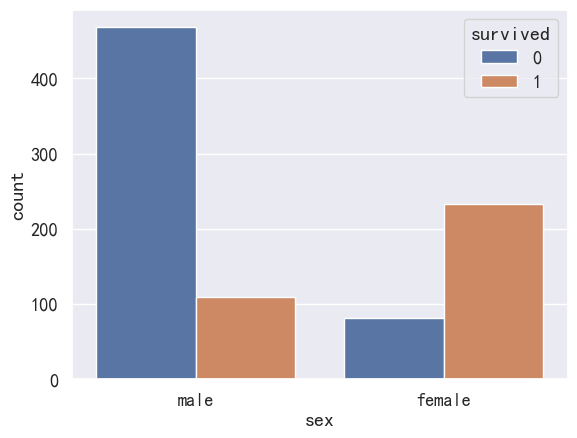
- 根据性别进行分类
sns.countplot(x='sex', data=pdata, hue='survived')
<AxesSubplot: xlabel='sex', ylabel='count'>
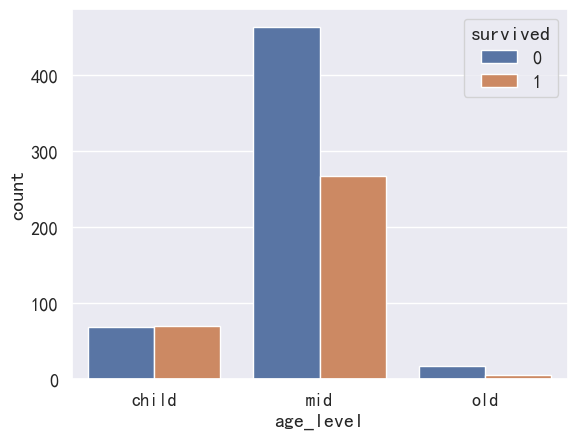
- 年龄与获救关系
sns.countplot(x='age_level', data=pdata, hue='survived')
<AxesSubplot: xlabel='age_level', ylabel='count'>
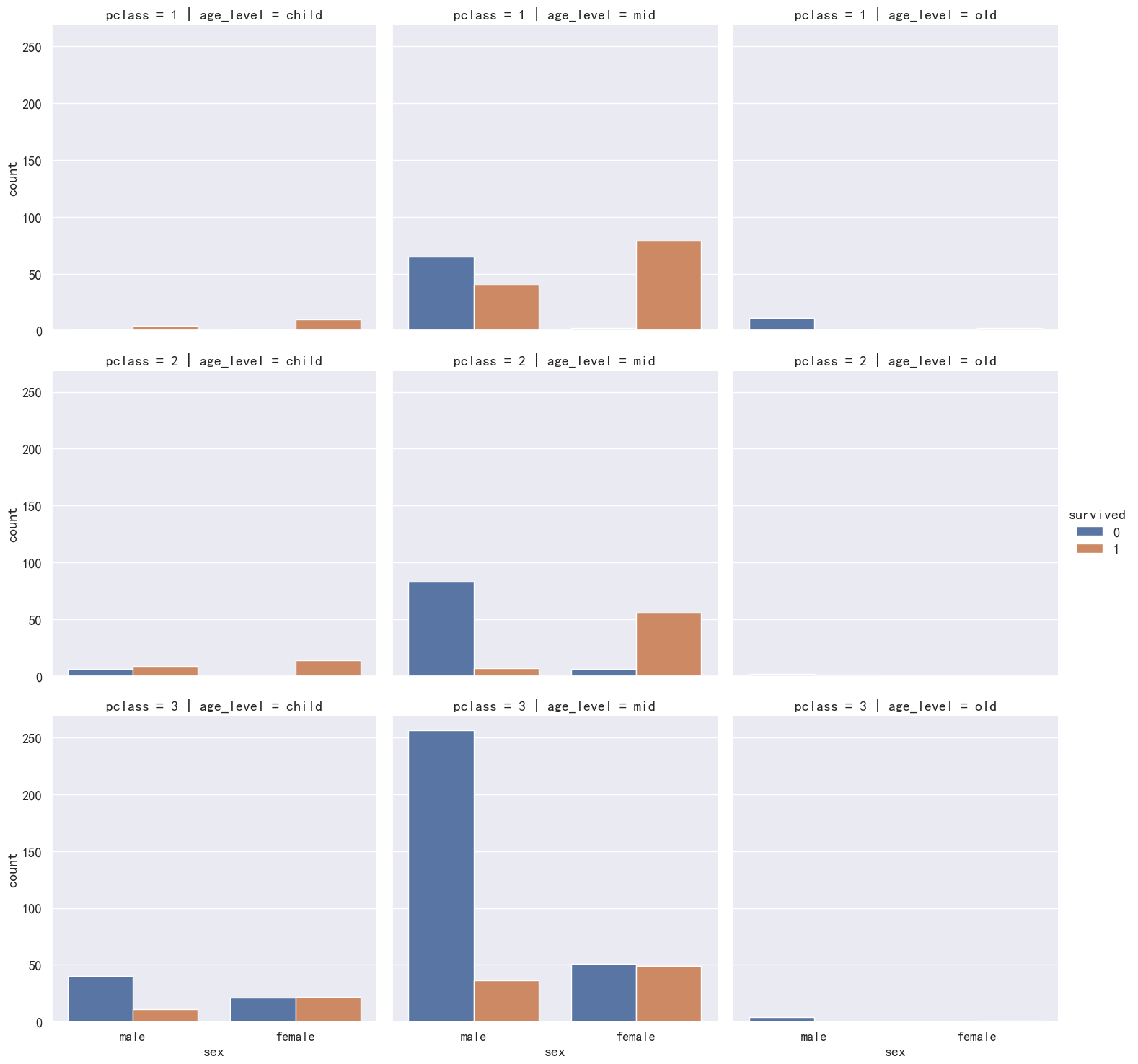
- 性别,获救,年龄段,船舱获救统计
sns.catplot(x='sex', hue='survived', data=pdata, kind='count', col='age_level', row='pclass')
<seaborn.axisgrid.FacetGrid at 0x1d4d126dc10>
这篇关于【Python基础】案例分析:泰坦尼克分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





