本文主要是介绍FlinkSql 窗口函数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Windowing TVF
以前用的是Grouped Window Functions(分组窗口函数),但是分组窗口函数只支持窗口聚合
现在FlinkSql统一都是用的是Windowing TVFs(窗口表值函数),Windowing TVFs更符合 SQL 标准且更加强大,支持window join、Window aggregations、Window Top-N、Window Deduplication
Windowing TVFs是 Flink 定义的多态表函数(Polymorphic Table Function,缩写PTF),PTF 是 SQL 2016 标准中的一种特殊的表函数,它可以把表作为一个参数
窗口函数
Flink 认为窗口把流分割为有限大小的 “桶”,这样就可以在其之上进行计算
有以下几种用法
- 滚动窗口
- 滑动窗口
- 累积窗口
- 会话窗口 (即将支持)
滚动窗口(TUMBLE)
TUMBLE 函数指定每个元素到一个指定大小的窗口中。滚动窗口的大小固定且不重复。
例如:假设指定了一个 5 分钟的滚动窗口。Flink 将每 5 分钟生成一个新的窗口,如下图所示:

TUMBLE 函数通过时间属性字段为每行数据分配一个窗口。 在流计算模式,时间属性字段必须被指定为事件或处理时间属性。在批计算模式,这个窗口表函数的时间属性字段必须是 TIMESTAMP 或 TIMESTAMP_LTZ 的类型
--TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
data :拥有时间属性列的表。
timecol :列描述符,决定数据的哪个时间属性列应该映射到窗口。
size :窗口的大小(时长)。
offset :窗口的偏移量 [非必填]。SELECT * FROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES));SELECT window_start, window_end, SUM(price)FROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))GROUP BY window_start, window_end;滑动窗口(HOP)
滑动窗口函数指定元素到一个定长的窗口中。和滚动窗口很像,有窗口大小参数,另外增加了一个窗口滑动步长参数。如果滑动步长小于窗口大小,就能产生数据重叠的效果。在这个例子里,数据可以被分配在多个窗口。
例如:可以定义一个每5分钟滑动一次。大小为10分钟的窗口。每5分钟获得最近10分钟到达的数据的窗口,如下图所示:

HOP 函数通过时间属性字段为每一行数据分配了一个窗口。 在流计算模式,这个时间属性字段必须被指定为事件或处理时间属性。在批计算模式,这个窗口表函数的时间属性字段必须是 TIMESTAMP 或 TIMESTAMP_LTZ 的类型
-- HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data:拥有时间属性列的表。
timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。
slide:窗口的滑动步长。
size:窗口的大小(时长)。
offset:窗口的偏移量 [非必填]。SELECT * FROM TABLE(HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES));SELECT window_start, window_end, SUM(price)FROM TABLE(HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))GROUP BY window_start, window_end;累积窗口(CUMULATE)
CUMULATE 函数指定元素到多个窗口,从初始的窗口开始,直到达到最大的窗口大小的窗口,所有的窗口都包含其区间内的元素,另外,窗口的开始时间是固定的。 你可以将 CUMULATE 函数视为首先应用具有最大窗口大小的 TUMBLE 窗口,然后将每个滚动窗口拆分为具有相同窗口开始但窗口结束步长不同的几个窗口。 所以累积窗口会产生重叠并且没有固定大小。
例如:1小时步长,24小时大小的累计窗口,每天可以获得如下这些窗口:[00:00, 01:00),[00:00, 02:00),[00:00, 03:00), …, [00:00, 24:00)
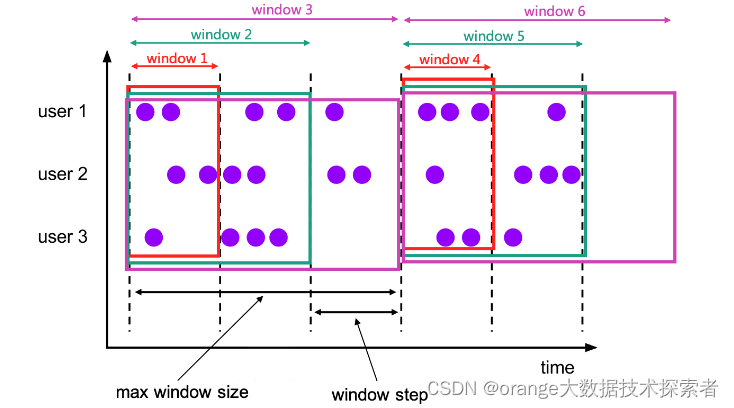
-- CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
data:拥有时间属性列的表。
timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。
step:指定连续的累积窗口之间增加的窗口大小。
size:指定累积窗口的最大宽度的窗口时间。size必须是step的整数倍。
offset:窗口的偏移量 [非必填]。SELECT * FROM TABLE(CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES));SELECT window_start, window_end, SUM(price)FROM TABLE(CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))GROUP BY window_start, window_end;窗口偏移
上诉窗口都有一个 offset 参数,默认值就是 0,所以窗口默认都是整点启动的
比如10分钟的滚动窗口:TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES),只会生成[2021-06-29 23:40:00, 2021-06-29 00:50:00),[2021-06-29 23:50:00, 2021-06-30 00:00:00),window_start 和 window_end 和数据的时间无关
offset 就是用来调整窗口偏移的,当 offset 为 -16 MINUTE,时间戳为 2021-06-30 00:00:04 的数据会分配到窗口 [2021-06-29 23:54:00, 2021-06-30 00:04:00)。
窗口函数进阶用法
flink开窗需要写上windowend,否则只是带了一个windowstart的时间而已,并没有真正开启窗口
Window Aggregation
窗口聚合是通过 GROUP BY 子句定义的,其特征是包含 窗口表值函数 产生的 “window_start” 和 “window_end” 列。和普通的 GROUP BY 子句一样,窗口聚合对于每个组会计算出一行数据。
SELECT window_start, window_end, SUM(price)FROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+并且支持多级窗口聚合
-- tumbling 5 minutes for each supplier_id
CREATE VIEW window1 AS
-- Note: The window start and window end fields of inner Window TVF are optional in the select clause. However, if they appear in the clause, they need to be aliased to prevent name conflicting with the window start and window end of the outer Window TVF.
SELECT window_start as window_5mintumble_start, window_end as window_5mintumble_end, window_time as rowtime, SUM(price) as partial_priceFROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES))GROUP BY supplier_id, window_start, window_end, window_time;-- tumbling 10 minutes on the first window
SELECT window_start, window_end, SUM(partial_price) as total_priceFROM TABLE(TUMBLE(TABLE window1, DESCRIPTOR(rowtime), INTERVAL '10' MINUTES))GROUP BY window_start, window_end;下面是分组窗口聚合的写法,分组窗口聚合已经过时,官网不推荐使用了
SELECTuser,TUMBLE_START(order_time, INTERVAL '1' DAY) AS wStart,SUM(amount) FROM Orders
GROUP BYTUMBLE(order_time, INTERVAL '1' DAY),userWindow Join
在流式查询中,与其他连续表上的关联不同,窗口关联不产生中间结果,只在窗口结束产生一个最终的结果。另外,窗口关联会清除不需要的中间状态
目前使用时有一些限制:
目前,窗口关联需要在 join on 条件中包含两个输入表的 window_start 等值条件和 window_end 等值条件
目前,关联的左右两边必须使用相同的窗口表值函数。这个规则在未来可以扩展,比如:滚动和滑动窗口在窗口大小相同的情况下 join。
语法上支持 INNER、LEFT、RIGHT、FULL OUTER、ANTI、SEMI JOIN。而且,窗口关联可以在其他基于 窗口表值函数 的操作后使用,例如 窗口聚合,窗口 Top-N 和 窗口关联
SELECT l.id as l_id,r.id as r_id,l.window_start,l.window_end
FROM (SELECT * FROM TABLE(TUMBLE(TABLE t_left, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))) l
INNER JOIN (SELECT * FROM TABLE(TUMBLE(TABLE t_right, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))) r
ON l.id = r.id
AND l.window_start = r.window_start
AND l.window_end = r.window_end;Window TopN
与普通Top-N不同,窗口Top-N只在窗口最后返回汇总的Top-N数据,不会产生中间结果。窗口 Top-N 会在窗口结束后清除不需要的中间状态
窗口 Top-N 适用于用户不需要每条数据都更新Top-N结果的场景,相对普通Top-N来说性能更好
SELECT *FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY price DESC) as rownumFROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))) WHERE rownum <= 3;还可以在窗口聚合后在进行窗口 Top-N
SELECT *FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY price DESC) as rownumFROM (SELECT window_start, window_end, supplier_id, SUM(price) as price, COUNT(*) as cntFROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))GROUP BY window_start, window_end, supplier_id)) WHERE rownum <= 3;Window Deduplication
窗口去重是一种特殊的 去重,它根据指定的多个列来删除重复的行,保留每个窗口和分区键的第一个或最后一个数据
对于流式查询,与普通去重不同,窗口去重只在窗口的最后返回结果数据,不会产生中间结果。它会清除不需要的中间状态。 因此,窗口去重查询在用户不需要更新结果时,性能较好
Window Deduplication是一种特殊的窗口 Top-N:N是1并且是根据处理时间或事件时间排序的(目前只支持根据事件时间属性进行排序),支持在其他窗口操作上进行去重操作,比如 窗口聚合,窗口TopN 和 窗口关联
SELECT *FROM (SELECT bidtime, price, item, supplier_id, window_start, window_end, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY bidtime DESC) AS rownumFROM TABLE(TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))) WHERE rownum <= 1;这篇关于FlinkSql 窗口函数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

