本文主要是介绍APIfox自动化编排场景(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
测试流程控制条件
你可以在测试场景中新增流程控制条件(循环、判断、等待、分组)等。进一步满足了更复杂的测试场景/流程配置的使用,最终借助自动化测试功能解决复杂场景的测试工作。

分组
当测试流程中多个步骤存在相关联关系时,可以进行归类并放入到同一个分组中。通过对测试步骤的分组,让测试场景具备更好的可读性和操作性。
示例: 将查看详情宠物详情、修改宠物信息、再次查看详情等步骤归类成分组。
-
- 点击底部的按钮「添加步骤」,并选择「分组」。
-
- 将要归类的步骤,拖到分组步骤下或在分组中直接添加步骤。
ForEach 循环
在 ForEach 循环中,可以根据设定的某数组内的元素个数,循环执行编排内的全部步骤,循环次数等于数组内的元素个数。还支持提取当前循环的元素值以及当前循环的索引值。
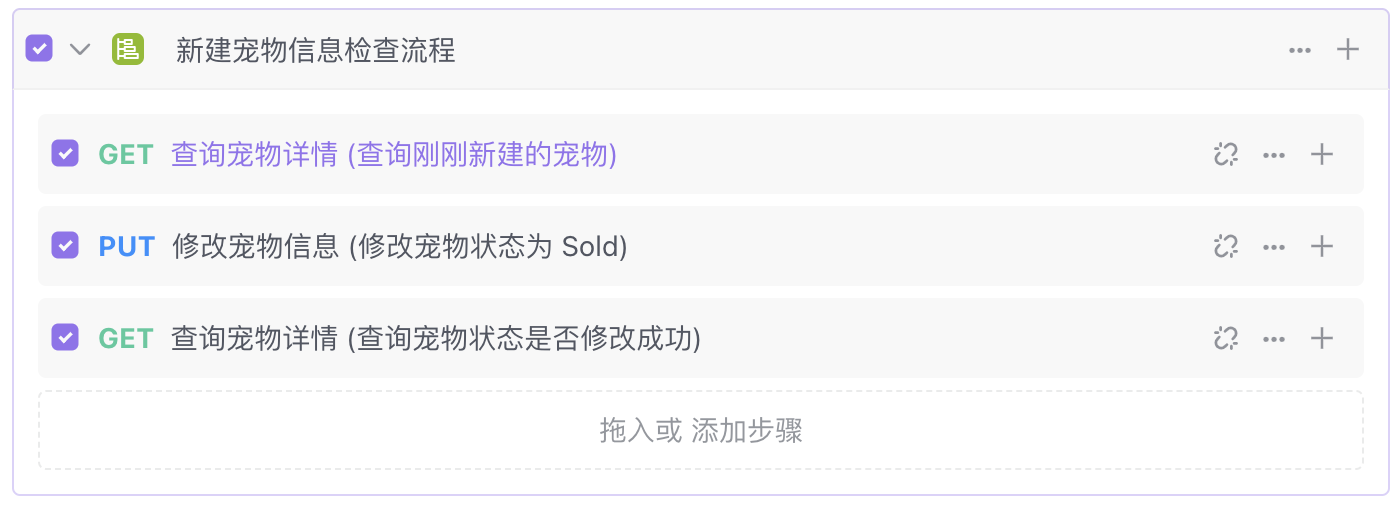
示例:有两个接口分别是获取宠物信息列表和获取单个宠物详情。我们的需求是查询在宠物列表中的刚刚新添加进来的宠物详情,按照以下操作即可使用 ForEach 循环在自动化测试中编排出这个场景。
-
- 循环外的第一步是先请求获取宠物信息列表接口,获取到实际的列表数据。一般这种情况接口内是会有一个数组涵盖多个宠物的基本信息,例如宠物 ID、名称。
-
- 设置 ForEach 循环,在循环上设置数组的来源是上一步的响应结果中的宠物信息数组部分。在本例中,写上
data.tags[*].id可以提取tags里的全部 id 值作为一个数组。
- 设置 ForEach 循环,在循环上设置数组的来源是上一步的响应结果中的宠物信息数组部分。在本例中,写上

-
- 在循环内设置“新建宠物信息”接口请求,并且在此接口设置请求参数 ID 中使用 ForEach 循环(element)里的元素值进行请求。
-
- 若从列表中返回了 3 个宠物信息(数组内有 3 个元素),那么你可以在测试报告中看到“获取宠物信息列表”接口执行了 3 次,每次实际请求的宠物 ID 值是对应“获取单个宠物详情”真实返回的 3 个元素内的 ID 值。

运行“测试报告”后,可以在详情内看到实际请求的值和响应数据相一致。

提示
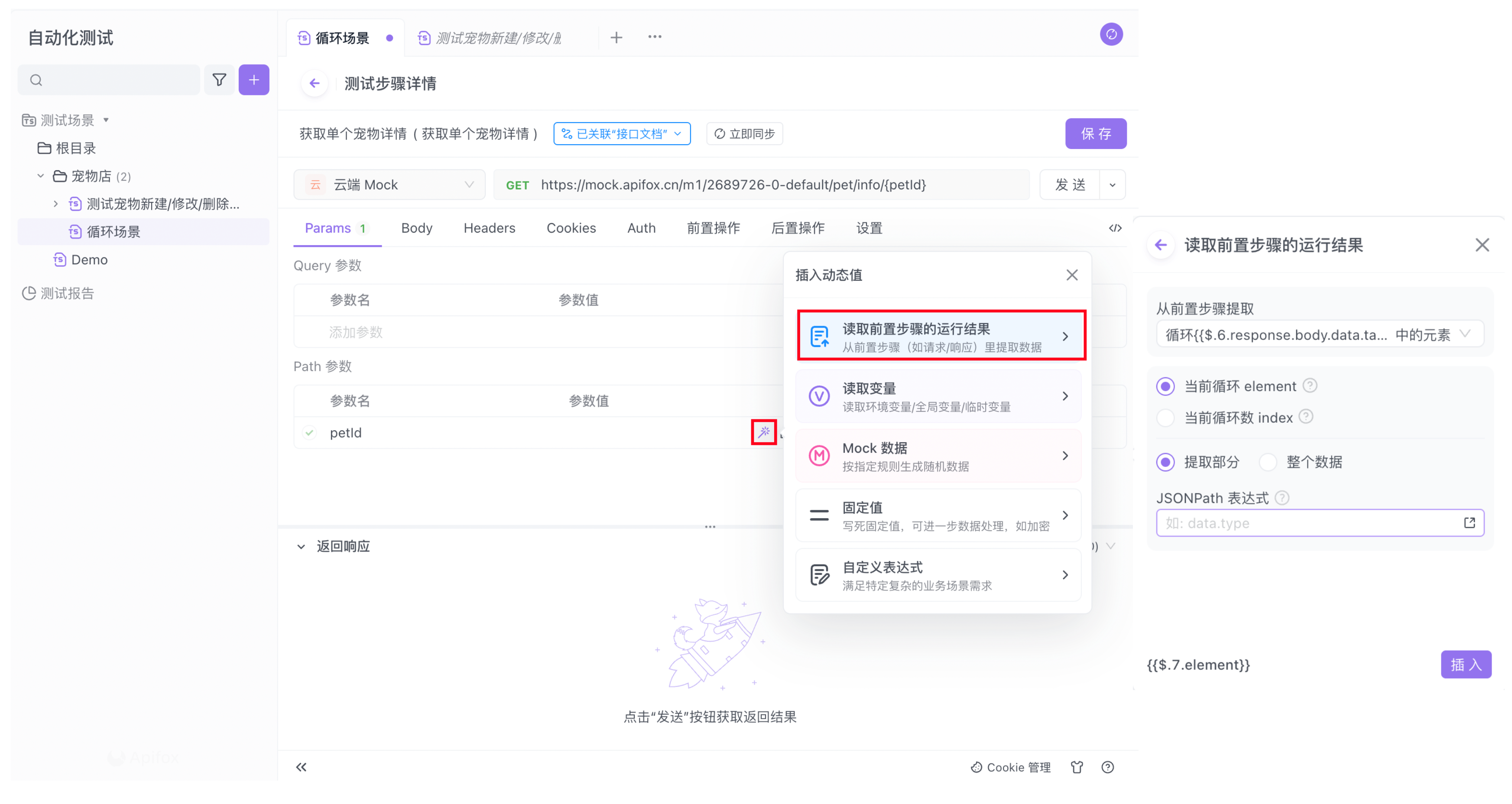
- 当前循环 element
系统自动将 ForEach 循环中设置的数组中的元素提取出来保存在此处指定的变量中。每次循环开始时,会基于当前循环的数组素更新这个变量的实际值。如果元素是个对象,可以通过使用 JSONPath 来提取对象中的某个子级字段。例如 {{$.1.element.data.name}}。
- 当前循环 index
当前循环的索引值,会保存在此变量中。从 0 开始,之后每次循环开始时会 +1 更新实际值。
以上两个变量除了可以通过“动态值”交互框进行可视化提取外,同样支持使用变量表达式。
For 循环
当测试步骤需要重复执行时,可以指定相应的循环次数重复执行。在循环的附加设置中,支持添加“中断条件”和“遇到错误时”的循环异常处理选项。
示例:宠物店 IT 管理员登录宠物库存管理后台,将今日出售的 10 个宠物的在售状态自动批量变更为已售出。
-
- 点击底部的按钮“添加步骤”,并选择“循环”。
-
-
在循环次数中选择“固定值”,输入 10 次。

-
-
-
将和宠物信息有关的接口拖入该条件下内框中,或直接在该条件下直接添加测试步骤。

-
提示
当前循环 index
当前循环的索引值,会保存在此变量中。从0开始,之后每次循环开始时,会+1更新实际值。
除了使用“动态值”功能可视化提取使用之外,同样支持使用变量表达式。
条件分支
当测试流程中存在多条件判断时,可以通过添加条件分支(If 语法)来区分流程执行的步骤。即当判断配置的条件满足时,该判断条件下的子步骤才会执行, 相反子步骤则会被跳过。
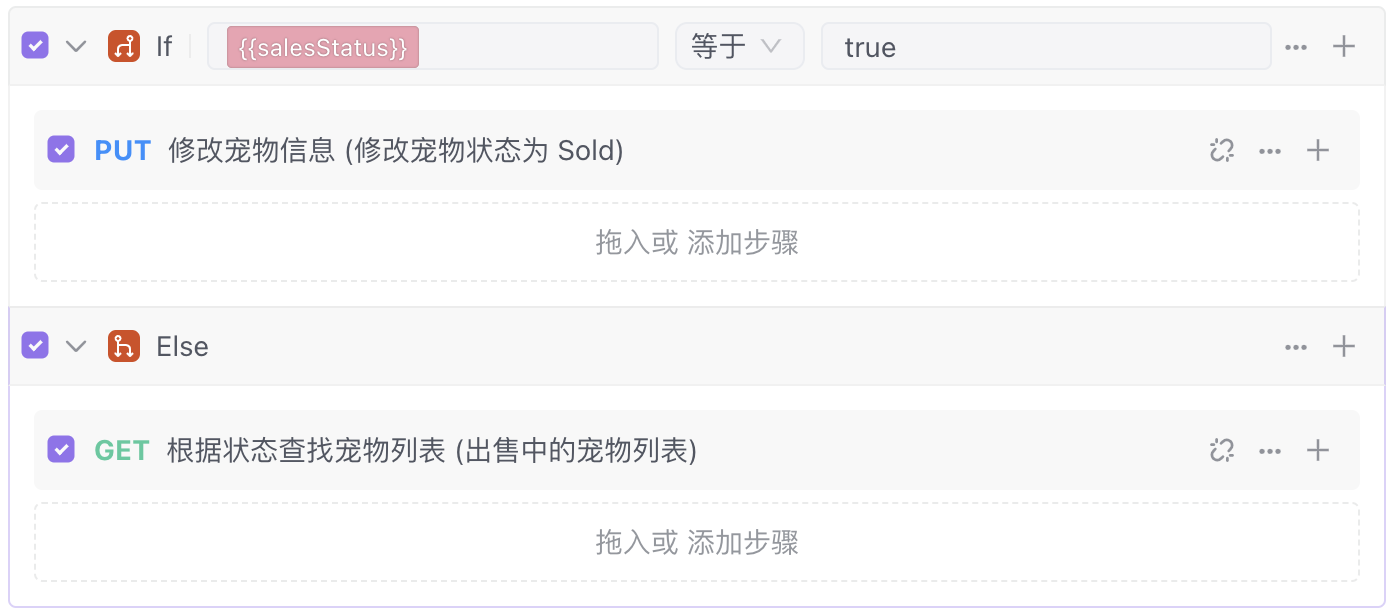
示例:宠物店店主根据昨日宠物出售情况,若判断为售出,将该宠物的出售状态设置为“已售出”。否则( else ),查询在售中列表。
-
- 点击底部的按钮「添加步骤」,并选择「条件分支」。
-
- 在 lf 条件后面的输入框填写请求接口得到的变量 saleStatus ,然后选择条件"等于",最后输入比较数值为 true。(当销售状态判断为 true 的时候,则更改宠物信息为「已售出」)
-
- 将鼠标悬浮在该条件分支操作拦会出现「+ Else 」,点击并新增「出售中的宠物列表」步骤(否则,即查询在售中的宠物列表。)。
-
- 将测试步骤拖入到相应的条件分支中。
等待
当测试流程中某个步骤需要执行后需要等待一段时间时,比如 A 步骤需要等待若干时间后再执行 B 步骤,可以通过新增等待条件来解决。
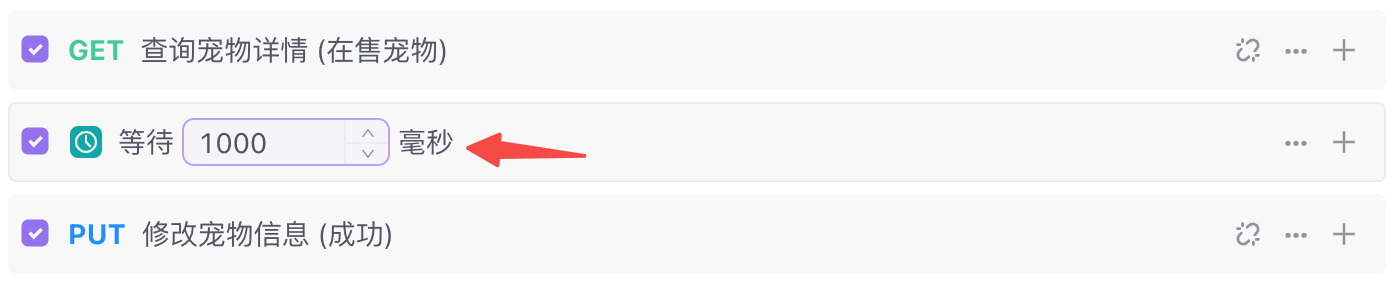
示例:模拟用户查看宠物详情,浏览 1000ms 后,将该宠物详情信息中的浏览状态进行更新。
-
- 点击底部的按钮「添加步骤」,并选择「等待」。
-
- 输入需要等待的时间 1000(单位毫秒)。
从接口文档/用例同步数据
简介
针对从接口文档/用例导入的测试步骤,其请求数据可以和关联的接口文档/用例进行同步。
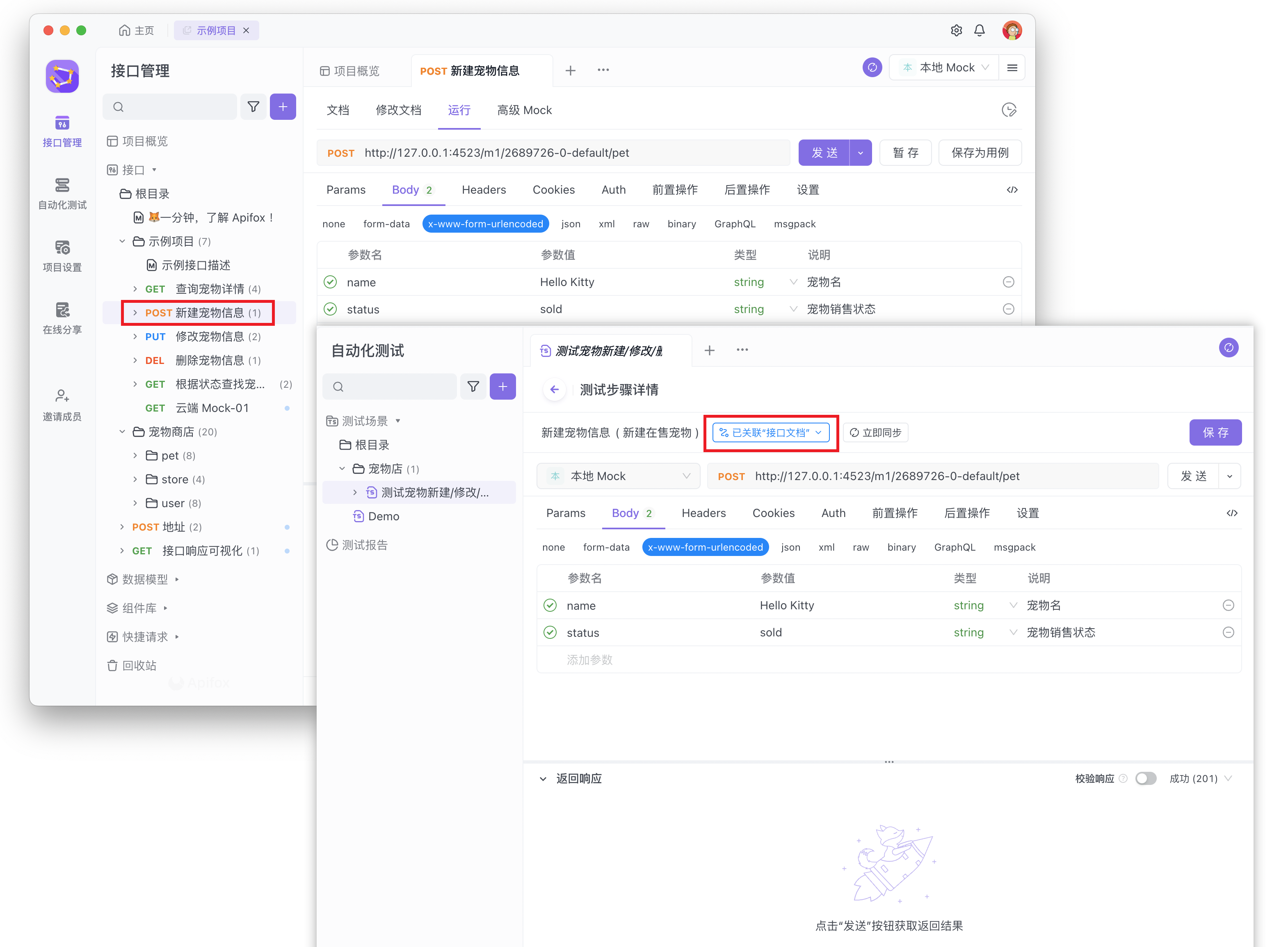
在测试步骤中导入接口文档/用例时可以选择手动同步或自动同步模式。
手动同步模式适合多人分工协作场景,即一个项目中的接口定义、研发、测试流程有着明确分工,每个流程有专门的负责人。流程之间要求数据独立,避免意料之外的改动相互影响。待确保接口文档/用例数据稳定后,测试人员再手动同步至测试步骤。
自动同步模式适合小团队或独立开发者场景,即一个项目中的接口定义、研发、测试流程均由一个角色负责,提升接口维护与测试的效率。当「接口管理」中的接口文档/用例发生变动时,测试步骤中的接口文档/用例数据也将联动调整,确保「接口管理」和「自动化测试」中的数据相一致。

手动同步
选择手动同步模式,关联按钮将显示为“蓝色”。当「接口管理」中的接口文档有任何改动时,测试步骤中的数据不会实时同步改动内容。测试人员可以在「测试步骤」详情中手动点击「立即同步」按钮将接口文档/用例改动同步至此。
此模式适用于测试角色在保存有大量的接口微调请求参数的实际提测场景,避免这些测试数据受到预期之外的影响,确保测试数据与正在开发的接口数据作出隔离。
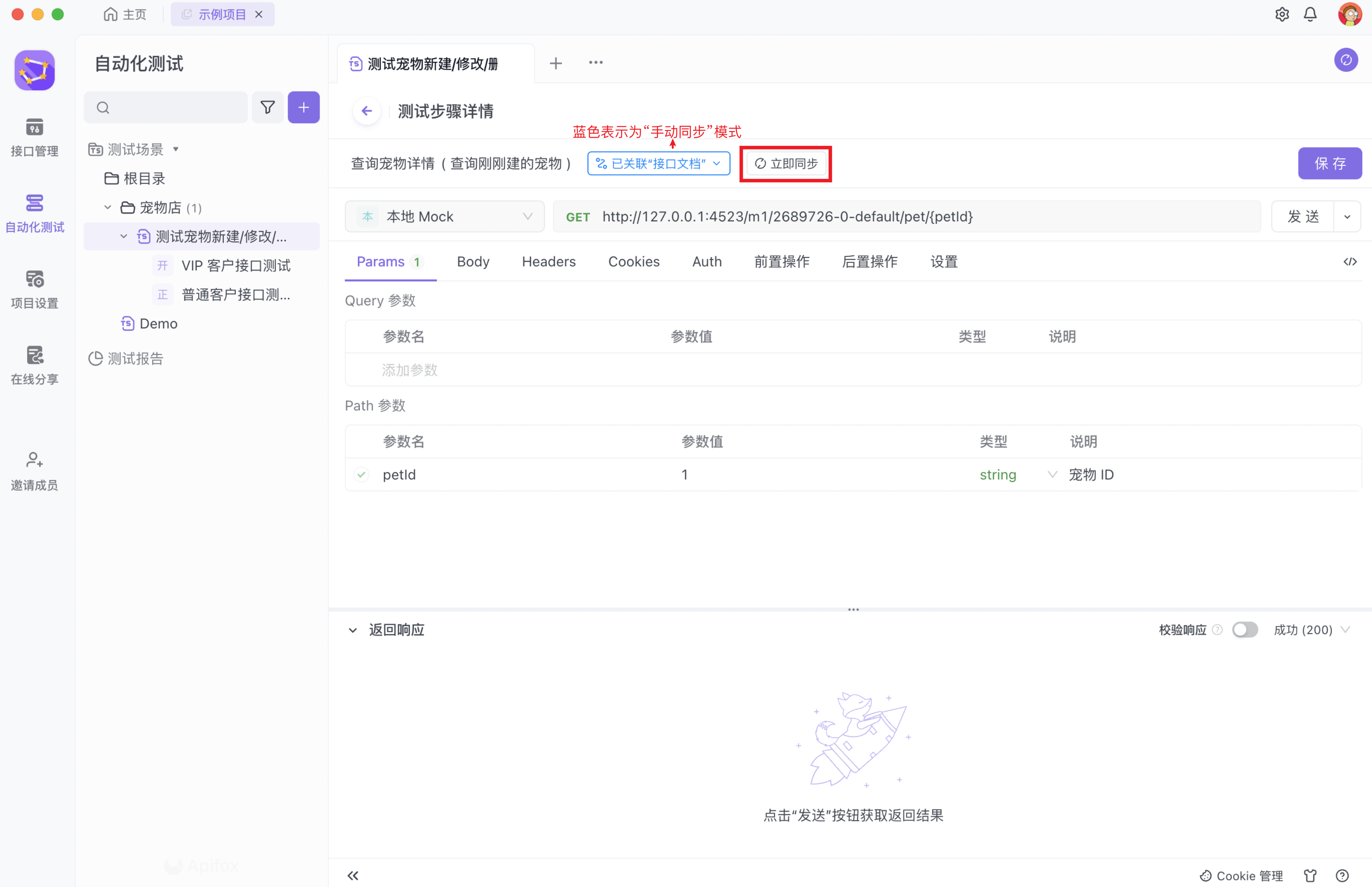
在手动同步模式下,关联按钮的下拉框中还支持手动筛选数据的同步范围。

同步接口文档
如果是从接口文档导入的测试步骤,则其关联内容为接口文档。跟接口文档关联的测试步骤,数据同步方式为手动同步时,通过点击“立即同步”按钮触发同步后,会将接口文档内容同步到此测试步骤中。
信息
触发手动同步后,测试步骤将同步接口文档中的数据,包括参数名及前后置脚本。
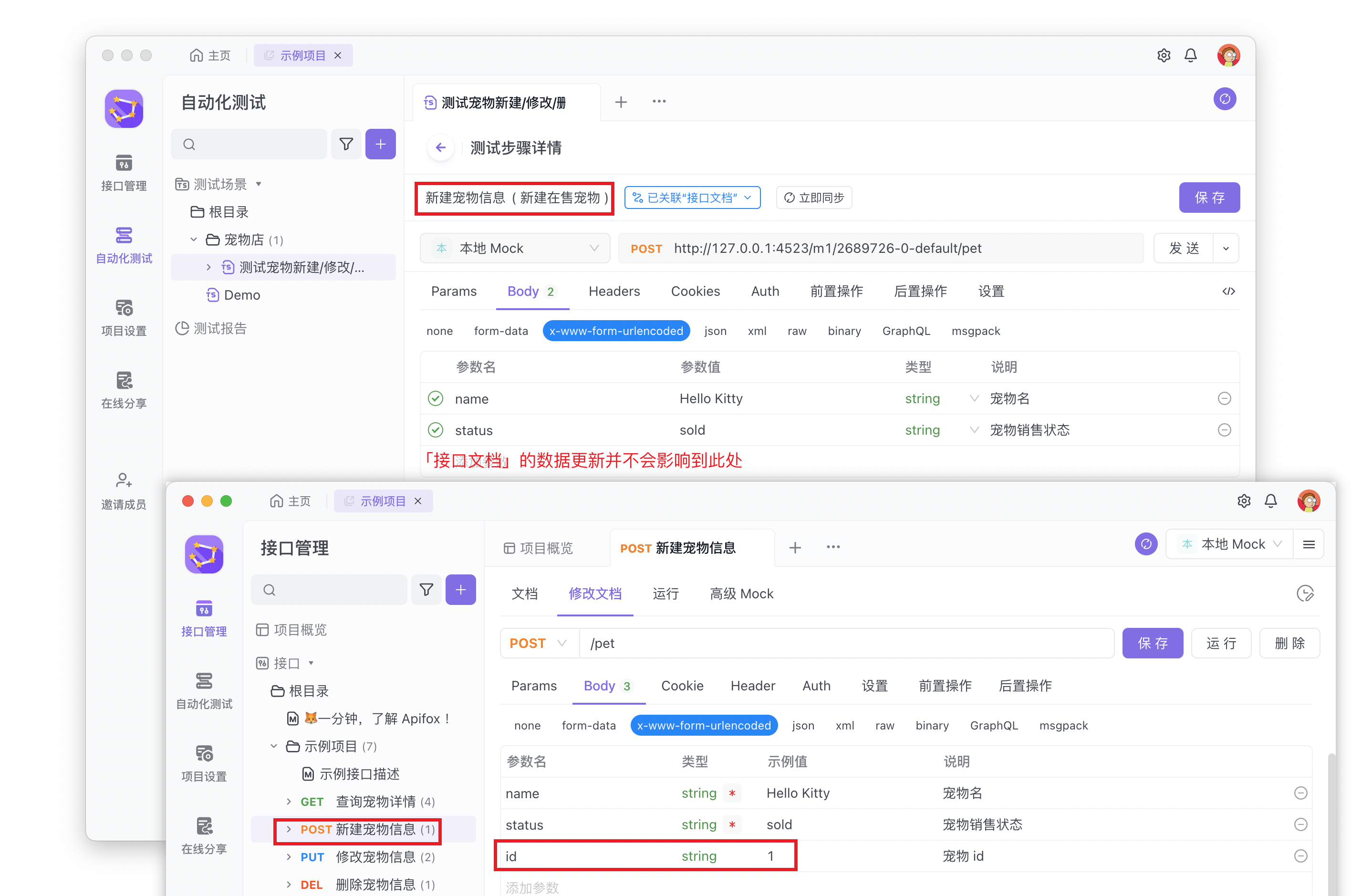
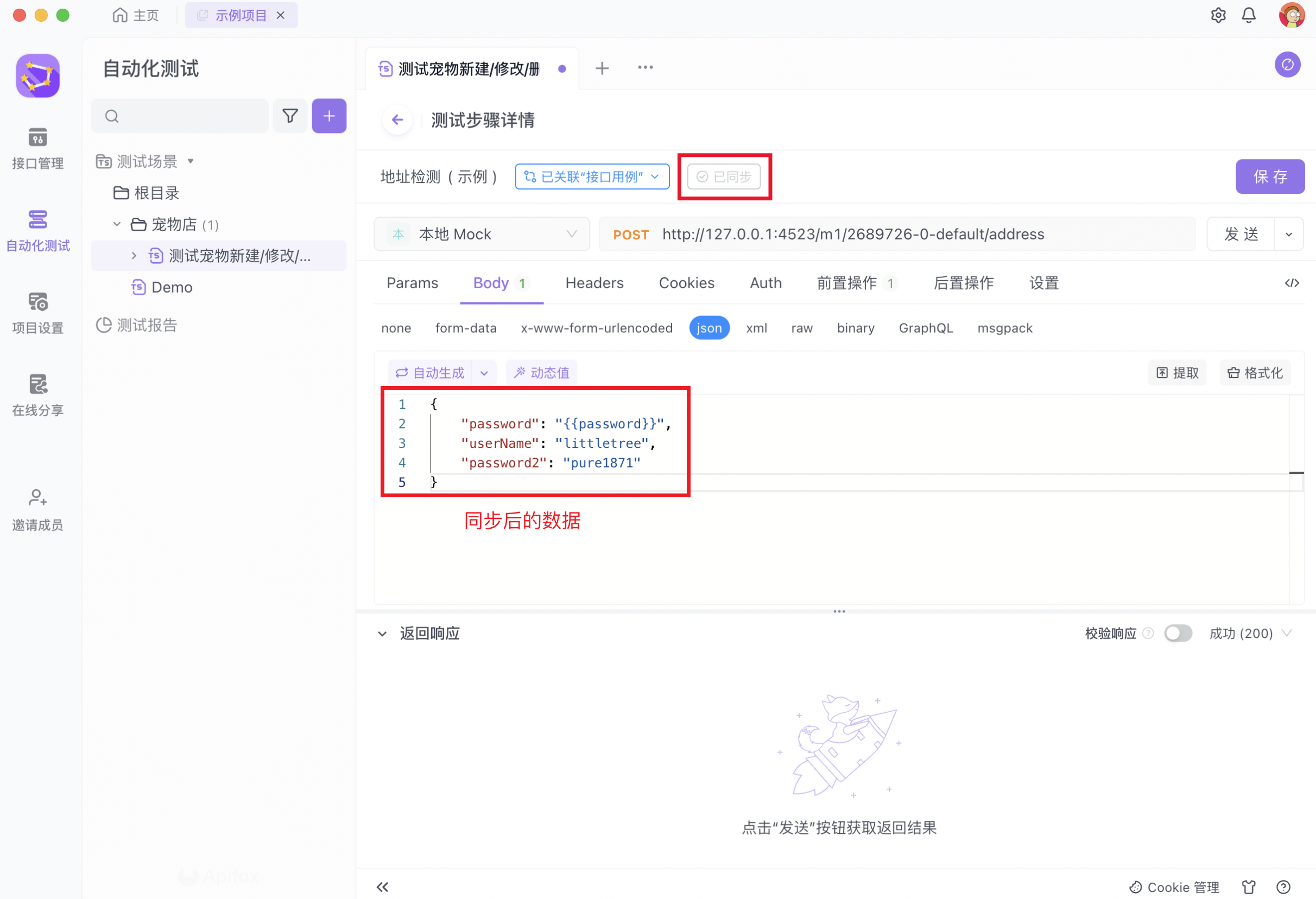
测试角色需要在测试步骤中手动点击「立即同步」按钮触发数据同步机制,点击后将提示为“已同步”。确认同步后的数据无误后,还需点击右上角的“保存”按钮保存测试步骤。

同步接口用例
如果是从接口用例导入的测试步骤,则其关联内容为接口用例。跟接口文档关联的测试步骤,数据同步方式为手动同步时,通过点击“立即同步”按钮触发同步后,会将接口用例内容同步到此测试步骤中。
信息
触发手动同步后,测试步骤将同步接口用例中的数据,包括参数名、参数值及前后置脚本。
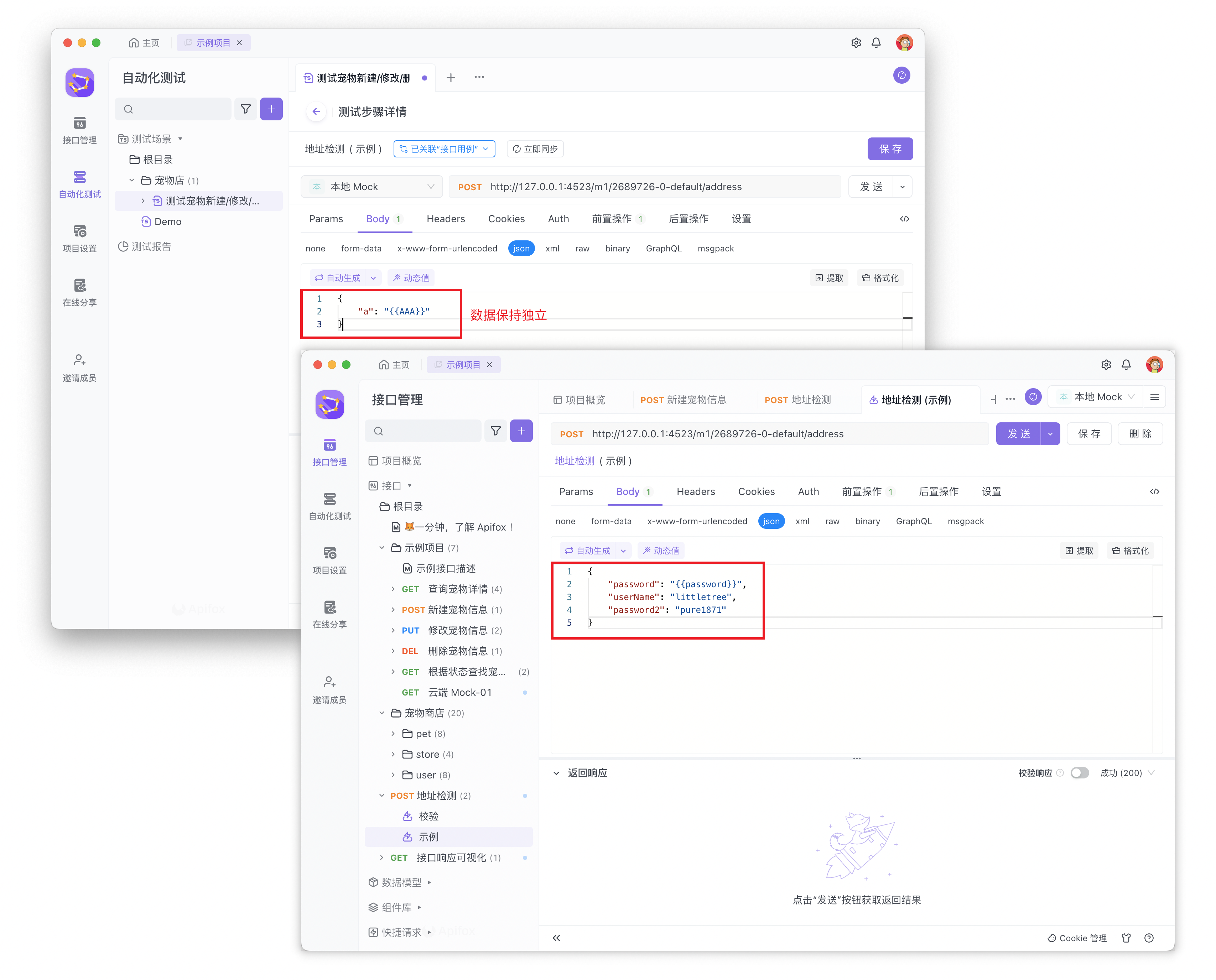
在测试步骤中手动点击「立即同步」按钮后触发数据同步机制,点击后将提示为“已同步”。确认同步后的数据无误后,还需点击右上角的“保存”按钮保存测试步骤。
批量同步数据
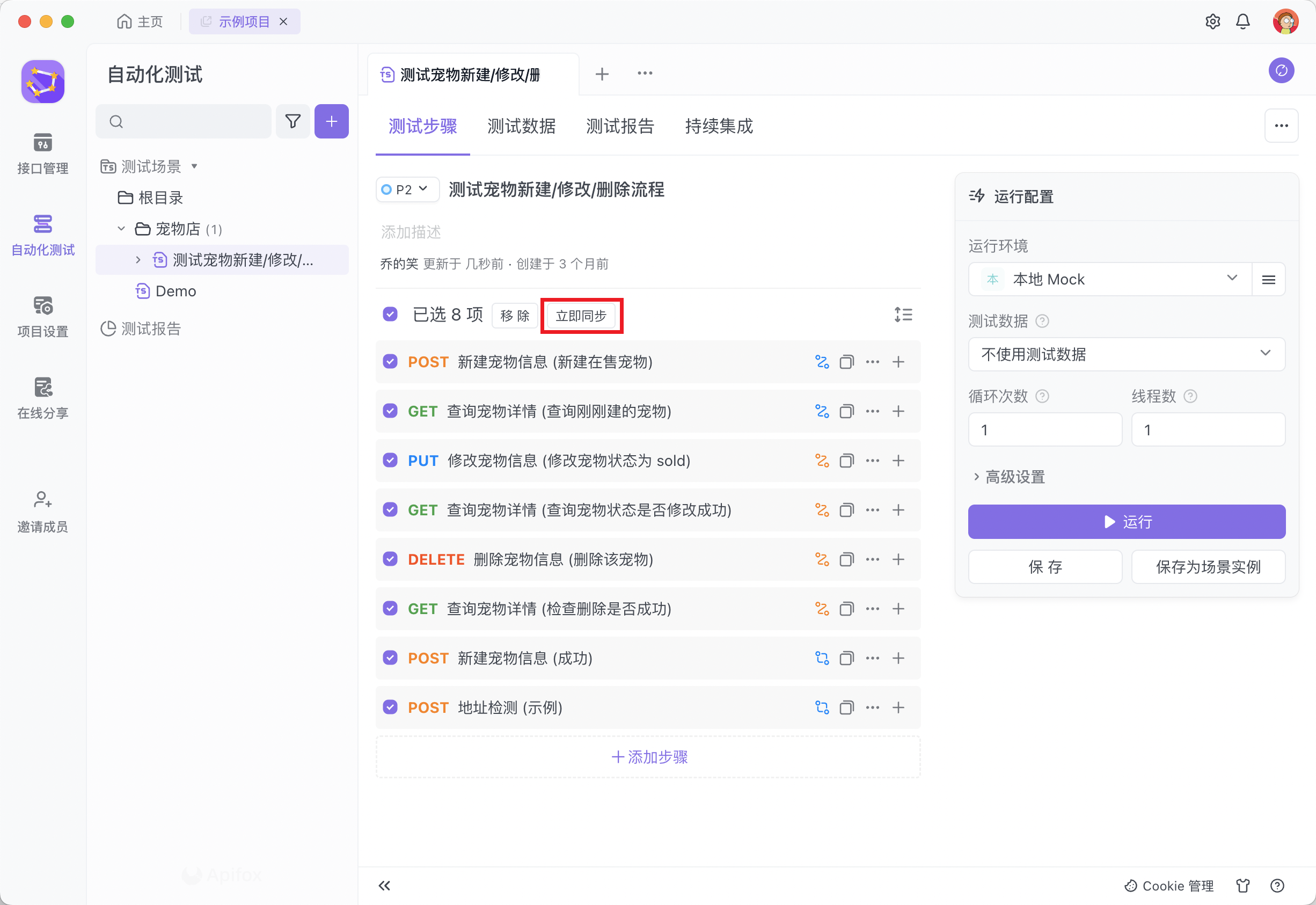
若当前测试步骤中大部分引用的接口文档/用例数据采用手动同步模式,而测试人员已经确认这些接口文档/用例的数据无误,希望将数据快速同步至测试步骤中,那么可以在测试步骤页点击“立即同步”按钮执行批量同步操作。
自动同步
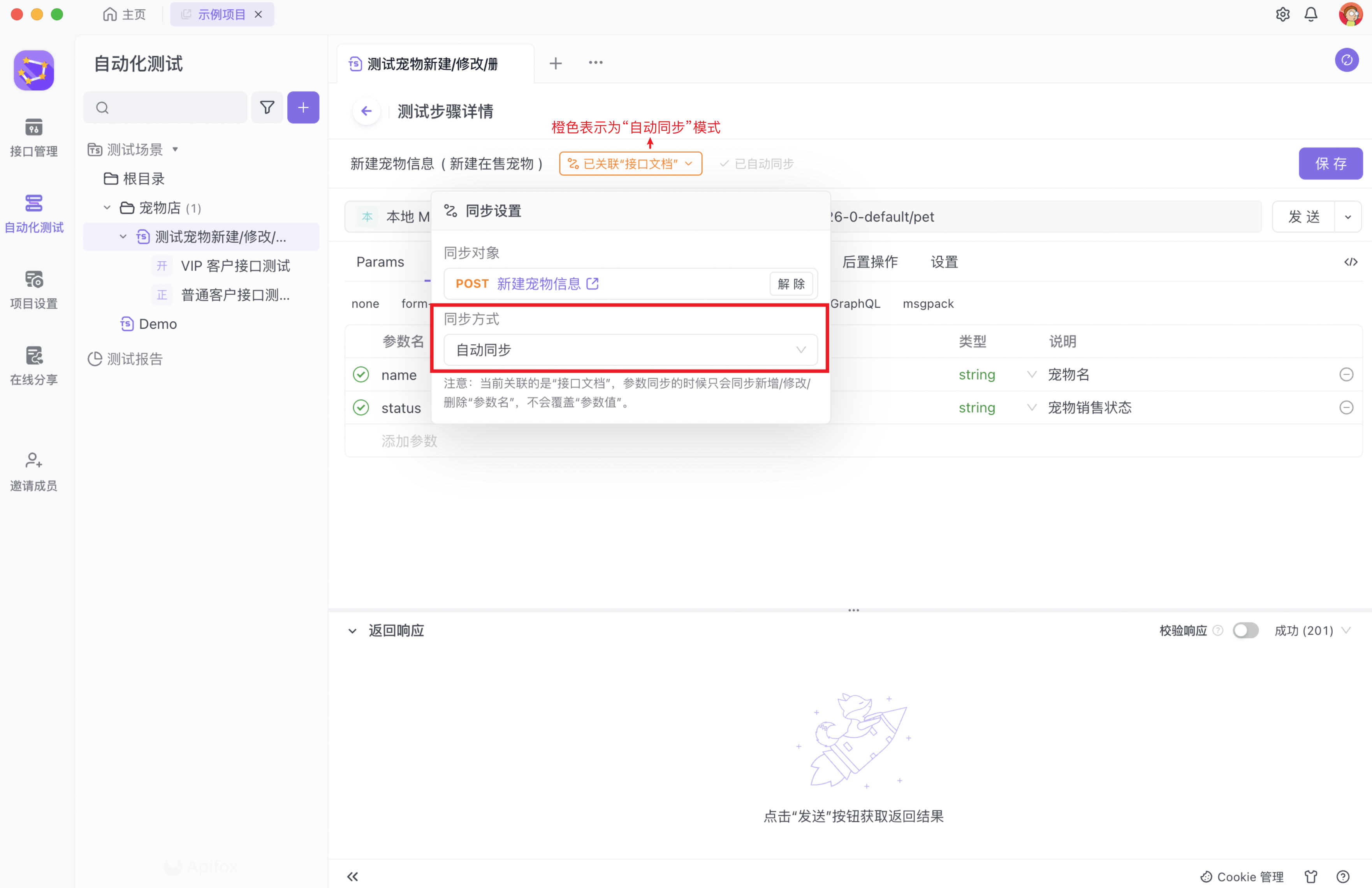
关联按钮将显示为“橙色”。此模式适合小团队或独立开发者场景,即一个项目中的接口定义、研发、测试流程均由一个角色负责。当「接口管理」中的接口文档或用例发生变动时,测试步骤中关联的数据将自动同步并保持一致,提升接口维护与测试的效率。
同步接口文档
跟接口文档关联的测试步骤,数据同步方式为自动同步时,接口文档有变更被保存,数据将实时更新至此测试步骤中。

在自动同步模式下,测试步骤内的数据与接口文档的数据的不一致会被高亮呈现出来,测试人员可以选择「复原」来保持跟接口文档完全一致;也可以选择「保存到文档」,此时测试步骤内的数据将反向覆写回接口文档,使得两者保持一致。

反向同步后,在接口文档中可以看到新增的参数。

同步接口用例
与接口用例关联的测试步骤,数据同步方式为自动同步时,接口用例与测试步骤将使用同一套请求数据。为了让这个逻辑更加清晰直观,同时也为了确保「接口管理」对于接口用例数据的管理唯一性,所以变更都需要在「接口管理」中进行调整。
点击测试步骤页面指引中的「去修改」按钮后,前往关联的接口用例页进行调整。测试步骤将自动同步接口用例变更后的数据,包括参数名、参数值及前后置脚本。


这篇关于APIfox自动化编排场景(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




