本文主要是介绍得物极光蓝纸箱尺寸设计实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
极光蓝包装盒成潮流标识,得物App成年轻潮人精神归属,特殊的包装材料已经在消费者之间形成了强大的心智,极光蓝等于得物。
但是由于早期箱型尺寸数据由人工经验设计,出现包装箱尺寸和商品尺寸匹配度不高的问题,一般会造成以下影响:
- 不合理的纸箱尺寸导致部分商品使用了较大的纸箱,造成了纸箱采购成本的浪费。
- 较大纸箱会造成运输成本的增加。
- 商品和纸箱之间的空隙过大,可能在运输过程中造成商品的损坏。
二、确定方案
考虑到纸箱招标节奏以及还需要留给仓内打样试装,试发货的时间,所以需要用比较快的速度完成建模和计算。
在这件事上,业务方也无法给出一些特别明确的准则,例如具体要算的综合目标中是包含运输成本的,这之中包含承运商的分配算法规则和他们的运费模板,将这些因素直接纳入到箱型建模之中基本是不可能的,再如箱子的数量是影响采购招标谈判的成本以及仓内的人效的,这里很难量化,也无法直接定义箱型数量值的评判标准。因此首先要和业务方产品分析现状定义目标,将问题全部量化,同时去简化问题。
2.1 问题分析
sku数据:过去一年的发货sku主数据及其对应的销量,再排除规则之外(只考虑用纸箱包装发货的商品、排除异性箱包装商品)和异常值(如sku尺寸异常)。
纸箱尺寸参数约束:考虑面单尺寸(纸箱尺寸下限定义)和便于仓内人员打包等合理性(纸箱尺寸上限定义),我们确定了纸箱上下限,形成数百万组合的空间。
箱型数约束:排除异型箱,需综合考虑装箱率、采购成本和仓内效率,一般来说单仓的箱型数量不宜超过15个。
覆盖率约束:在已经筛选出纸盒外包装打包的sku的前提下,接受部分异形、大件物品不可被箱型组覆盖,要求覆盖发货订单率>=99%。
基于以上对问题的分析可以看出,如果有了一组解K个箱型,去计算装箱率,这个问题的复杂度还好。但是如果正面去计算,则需对符合条件的sku去遍历箱型组合,这个基本上是无法在有效时间内算出结果的。
2.2 问题简化
2.2.1 箱型数约束
排除异型箱,基于得物当前的仓内实际情况,本次预计新设计的箱子数在8~15个,需综合考虑装箱率、采购成本和仓内效率,当箱型数量增加时,装箱率会提高,采购成本也会提高,仓内效率会降低。由于这里并不能量化它,例如给出具体综合指数,因此此处决定给出多个版本,供业务方抉择,而不作为建模的约束或目标,这里相当于直接简化为把M组箱型的M * 固定一种箱型的复杂度,在实际中开发中,只需要用M个容器同时执行一次计算即可。
2.2.2 覆盖率约束
覆盖率约束是个不等式约束,且当前问题,不可覆盖的sku部分的分布是非常显而易见的,集中在长宽高中一个或多个值超过仓内操控方便程度上限值,因此,这里将箱型上限值和接受不覆盖的部分,再建模之前先确定下来。
2.2.3 目标函数定义
对于采购成本来说,这不必说,一定和纸箱的用纸情况有关,纸箱用纸越小(纸箱展开面积越小)则成本越低;
对于运输成本来说,基本上3pl都是用MAX(抛重,实重)的方法来计算,那么这和纸箱展开面积的优化方向也是正的;
如果把各3pl运费模板加入到建模中,同时也需要考虑承运商分配的算法设计,那么问题会过于复杂,计算量也是很大。现在很显然,我们只要优化单均用纸面积,如果某单优化后的纸箱包装未触及运费模板的变动范围,则运费不变,若触及则运费成本必然会降低。
综上,最终考虑用装箱率这个间接指标作为目标,装箱率指的是测试的(数据集sku总体积 / 数据集发货箱子总体积),这个也是产品和业务方很熟悉且一直在关注的指标。
2.2.4 问题建模
经过上述简化,这里将目标函数定义成了装箱率,并且发货订单覆盖率、箱型数约束值放在了建模问题之外。

其中,S_i表示Sku_i的销量,R_i表示Sku_i的推荐箱型结果装箱率
推荐箱型应满足内部间隙大于最低要求,在箱型组中选择最小箱型,即

箱子的大小,应满足至少可以贴运单,也不能过大影响仓内人员打包效率

同时我们对sku进行长>宽>高的排序清洗,同时定义纸箱长>宽>高
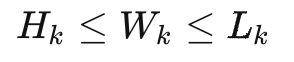
最后,我们要求箱子的长宽高数据均为整数,即
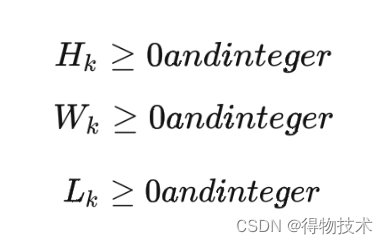
三、优化算法
3.1 一般求解方法概述
对于这个优化问题,通常主要包括精确解算法和启发式算法:
精确方法主要是用单纯形法(线性规划)或者一些迭代的方法(非线性规划)再结合分枝定界法找到我们要的整数解。精确方法如果是线性规划问题能通过单纯形法在可行域的顶点中找到全局最优解,非线性规划也是通过微分学方法或者有限次的迭代找到接近于最优解的,由于不是多项式时间的求解方法,故而往往在大规模实例上不可行。
启发算法如遗传算法、蚁群算法、进化算法、智能算法针对普遍的问题。可以将它当作一个黑箱子对几乎任何问题适用。启发式算法,说白了就是有方向的穷举法,在计算资源有限的情况下,需要根据问题场景和模型特点,选择合理的邻域结构或操作机制,在全局搜索能力和局部搜索能力之间做权衡。启发算法通常需要给定初始解;另外,算法不能保证在多项式时间收敛,但常常可以控制算法迭代次数。

3.2 精确解求法
- 线性规划
对于线性规划问题,它的可行解构成的集合为凸集或者无界域,基可行解对应凸集的顶点,通过凸集的性质得出最优解会在凸集的顶点上,然后通过遍历再排序的方法可以得出最优解,但是当顶点过多的时候,则需要用单纯形法找到线性规划的最优解。
- 非线性规划
如果目标函数或者约束条件中含有非线性函数,例如当前的问题中目标函数装箱率中具有非线性因素,这种规划问题为非线性规划问题。一般来说,解非线性规划问题要比解规划问题困难的多,它不像求解线性规划有单纯形法这一种通用方法,非线性规划目前还没有适用于各种问题的一般算法,各个方法都有自己特定的适用范围。
- 整数规划
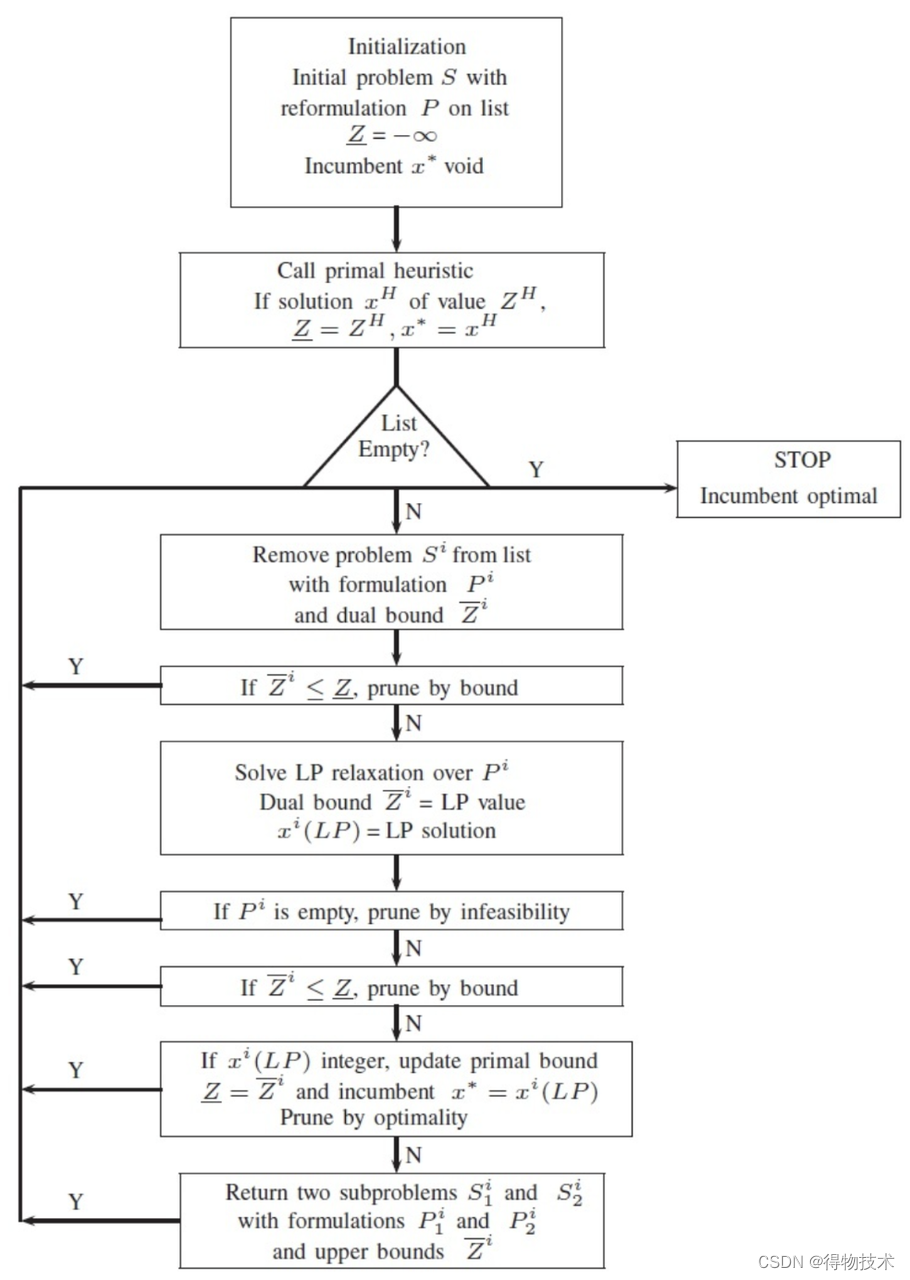
因为要求输出的结果是整数,所以需要用分支定界法来求解。
分支定界法的核心思想就是分枝和剪枝。当不考虑所求解必须是整数这个条件时,用单纯形法可求出最优解,但是这个解往往不全是整数,因此采用剪枝的方式一点一点缩小范围,直到所求解为整数解。
从图中可以看到,初始化阶段,需要给定输出的全局的上界和下界,如果能有一些启发式的方法获得稍微好点的上下界作为初始解导入那是最好的不过的了。如果没有的话可以先设置为正负无穷大。
接着进入到主循环中,通过求解整数规划的连续松弛问题(线性规划)来得到该子问题的上界;分解问题可以帮助对整数规划问题进行拆分,同时也可以帮助我们得到下界。
3.3 元启发式方法
以遗传算法为代表的这类算法,适合以下场景:
- 神经网络超参数优化
- 一部分结构和特性固定的组合优化问题
- 一部分机理模型难以建立的黑箱优化问题
- 多目标优化问题
3.3.1 遗传算法
- 基本概念
- 基因:可行解的元素
- 染色体:一条染色体为一个可行解
- 交叉:多条染色体切断拼接成新的染色体
- 变异:将染色体的部分基因进行修改
- 复制:完全遗传复制上一条染色体
- 执行流程

- 在算法初始阶段,它会随机生成一组可行解,也就是第一代染色体。
- 然后采用适应度函数分别计算每一条染色体的适应程度,并根据适应程度计算每一条染色体在下一次进化中被选中的概率。
- 通过“交叉”,生成N-M条染色体。
- 再对交叉后生成的N-M条染色体进行“变异”操作。
- 然后使用“复制”的方式生成M条染色体;
- 重复2~5。
四、具体建模
4.1 数据分析
首先粗略看下近一年得物发货的sku的长、宽、高主数据及其销量分布,这是我们设计箱型的依据数据。同时综合考虑仓内实际作业时候的效率以及采购的成本,因此箱子的种类数量也不可太多,否则会增加仓内打包人员取箱子的难度,采购成本也会相应提高。
在这一步,考虑到首先要准确和当前箱型 A/B ,同时8~15种这个数量加入到建模参数中也增加了计算复杂度,所以决定固定这个箱型数量的值,首先假设固定N种箱型,每个箱型长宽高三个数,即输出3 * N个参数。
接下来我们定义一下商品sku和箱型的 长>宽>高,首先对近一年的数据进行长宽高排序、异常值等清洗,例如固定了12种箱型,我们就将sku和箱型在长宽高维度用k-means聚类成12组。

做这个聚类分析,一方面,根据实际情况,例如结合面单尺寸定义箱型下限,再结合箱型覆盖率下限值,定义箱型上限尺寸;
另一方面,每个聚类的最大值可以作为箱型的初始化值(实际需要加上5mm作为缝隙)。
4.2 约束和目标
业务上约束来说,只需要将商品装入箱子,留下缝隙即可,且由于确定箱子的种类数量,这里还需要确定的是每组箱子的长>宽>高,即
constraint_ueq = (# 单个箱子长>宽>高lambda x: x[1] - x[0],lambda x: x[2] - x[1],lambda x: x[4] - x[3],lambda x: x[5] - x[4],... )目标则是max 装箱率,即
def cal_avg_r_cached(p):'''The objective function. input routine, return total distance.cal_total_distance(np.arange(num_points))'''total_r = 0for row in npd:r = [-1] * box_numfor i in range(box_num):if (row[0] <= p[3 * i]) and (row[1] <= p[3 * i + 1]) and (row[2] <= p[3 * i + 2]):r[i] = row[4] / (p[3 * i] * p[3 * i + 1] * p[3 * i + 2])total_r += max(r) * row[3]print(total_r)return -total_r / sum_cnt4.3 结论
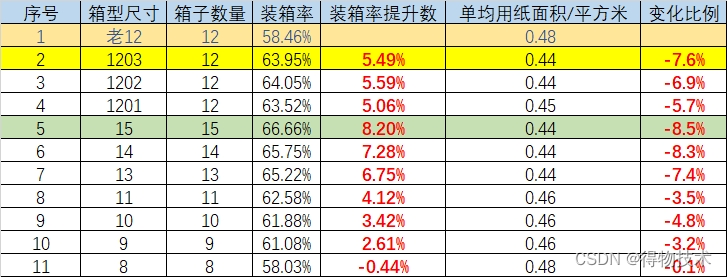
最终并行跑了几个版本,装箱率均有不等的提升,单均用纸面积有显著下降;
最终选择的1203方案作为工程侧的输出,装箱率提升5.49%,单均用纸面积节约7.6%,单均运费降低0.06元。
五、彩蛋 -- 使用遗传算法绘制NONO
在写这篇文章查相关资料发现的挺有脑洞的内容,用数个带有颜色的三角形,组装成图像。
这里试着用60个三角形绘制了下NONO。
效果大致如下:

在优化算法中,介绍了遗传算法的大致流程,那么绘制这个NONO和箱型设计有啥区别呢?
在箱型设计中,需要基于装箱率指标去计算箱子尺寸,因此,在定义适应度函数的时候,只要取Maximize装箱率这个指标即可,那么到了此处,只要将目标函数定义为不同颜色尺寸的透明三角形组装结果与目标图片的相似度即可。
5.1 适应度函数
首先需要找到能够量化透明三角形组成的图和目标NONO图的差异或者相似度的方法,那么如何定义相似度呢?图像的相似度即在某个颜色空间(例如RGB、HSV)下的值向量的相似度,每个点的差异值总和最小则越接近想要的目标图案,常用的评估函数例如MSE、RMSE、PSNR、ERGAS、SAM等。
下图是对于一些图像噪声方法,各种相似度评估方法对应的相似度结果。其中“Original”一栏显示的是原始图像与自身比较后的分数。
这里选择ERGAS来作为我们的适应度函数的依据。

5.2 选择
这里用不一定完全用轮盘赌方法来做选择,95%概率选择适应度函数靠前的解,5%的概率从其他解里面随机选择。
if random.random() < 0.95:'''选择基因的来源父母,95%几率从最优的祖先中随机'''poly_a = random.choice(polygons[:1])poly_b = random.choice(polygons[1:5])
else:'''选择基因的来源父母,5%从所有的祖先中随机'''poly_a = random.choice(polygons)poly_b = random.choice(polygons5.3 交叉和变异
这里也一样用随机数,大概率随机从父类中继承赋值基因,小概率修改基因值,坐标交叉变异大致如下,颜色交叉变异同理。
temp = random.random()if temp < 1 / polygon_num:'''设定一定几率坐标变异'''rnd_temp_coord = poly_a.coord_list[i][:]rnd_temp_coord[random.randint(0, vertices - 1)] = random.randint(0, img_width), random.randint(0, img_height)temp_coords.append(rnd_temp_coord)elif temp < 0.5:'''随机继承父母中的一个基因'''temp_coords.append(poly_b.coord_list[i])else:temp_coords.append(poly_a.coord_list[i])temp = random.random()*文 /酱油
关注得物技术,每周一三五晚18:30更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
这篇关于得物极光蓝纸箱尺寸设计实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






