本文主要是介绍A64指令集架构之PCS过程调用标准,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Arm架构对通用寄存器的使用几乎没有限制。简而言之,整数寄存器和浮点寄存器都是通用寄存器。然而,如果你希望你的代码与他人编写的代码互动,或者与编译器生成的代码互动,那么你需要就寄存器的使用达成一致的规则。对于Arm架构,这些规则被称为过程调用标准(Procedure Call Standard),或者PCS。
PCS规定了:
- 用于将参数传递给函数的寄存器。
- 用于将值返回给调用函数(称为调用者caller)的寄存器。
- 被调用的函数(称为被调用者callee)可以破坏哪些寄存器。
- 被调用者不能破坏哪些寄存器。
考虑一个从main()调用的函数foo():
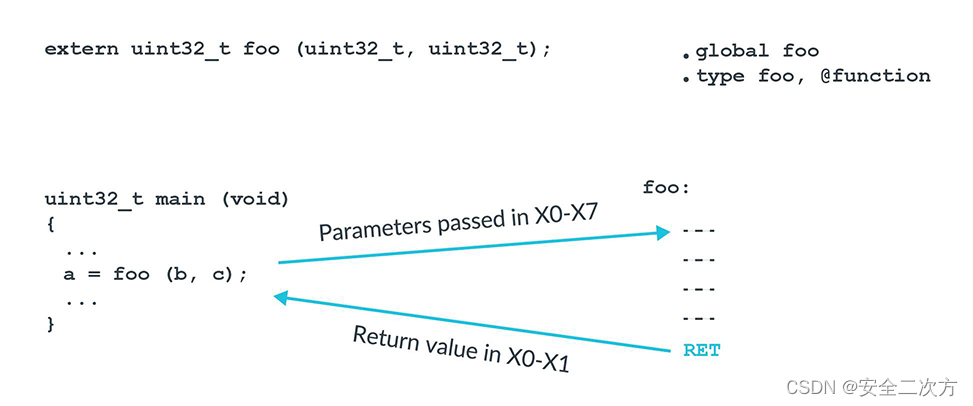
PCS规定第一个参数传递给X0,第二个参数传递给X1,以此类推,直到X7。任何额外的参数都传递到栈stack上。我们的函数foo()接受两个参数:b和c。因此,b将位于W0,c将位于W1。
为什么是W而不是X?因为这些参数是32位类型,因此我们只需要一个W寄存器。
【注意】:在C++中,X0用于传递指向被调用函数的隐式this指针。
接下来,PCS定义了哪些寄存器可以被破坏,哪些寄存器不能被破坏。如果一个寄存器可以被破坏,那么被调用的函数可以在不需要恢复的情况下覆盖它,正如PCS寄存器规则表所示:
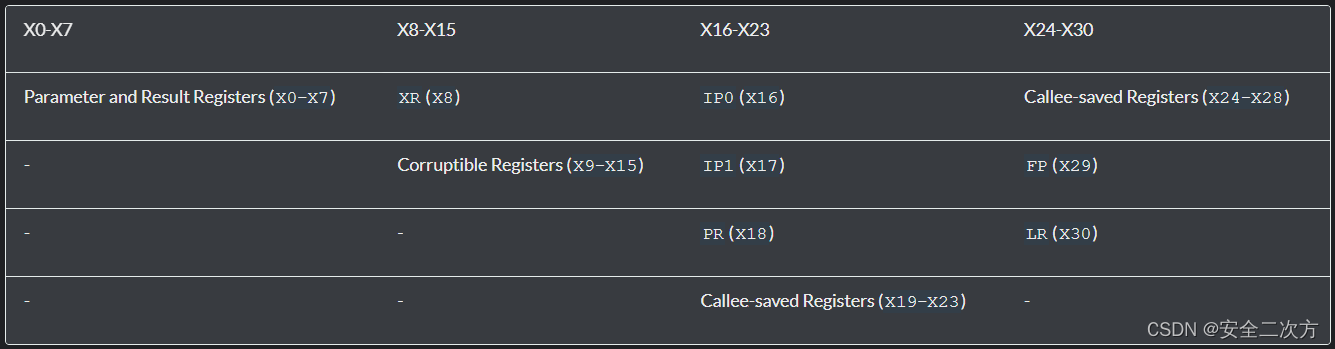
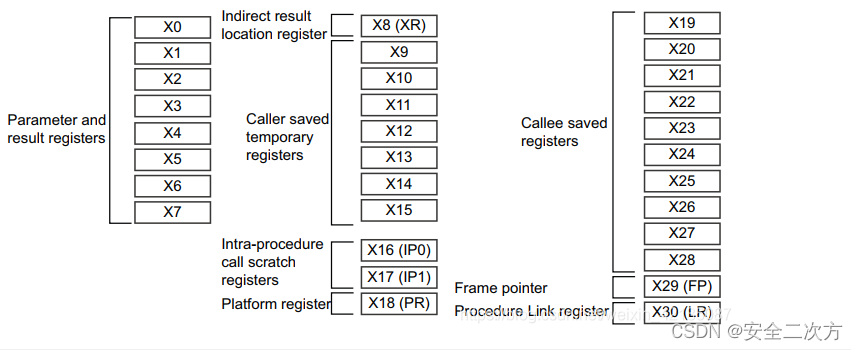
例如,函数foo()可以使用寄存器X0到X15而无需保留它们的值。然而,如果foo()想要使用X19到X28,它必须先保存它们到栈,然后在返回之前从栈中恢复它们。
在PCS中,一些寄存器具有特殊的意义:
- XR - 这是一个间接结果寄存器。如果foo()返回一个结构体,那么结构体的内存将由调用者分配,例如在前面的例子中是main()。XR是指向由调用者分配用于返回结构体的内存的指针。
- X16和X17(IP0和IP1) - 这些寄存器是过程内调用可破坏寄存器。这些寄存器可以在调用函数和到达函数的第一条指令之间被破坏。链接器使用这些寄存器在调用者和被调用者之间插入veneers。veneers是一小段代码,最常见的例子是用于分支范围扩展。A64中的分支指令是有限的范围。如果目标超出了该范围,那么链接器需要生成一个veneer来扩展分支的范围。
- FP - 帧指针。
- LR - X30是用于函数调用的链接寄存器(LR)。
对于X16和X17,在《ARM安全架构——为复杂软件提供保护》一文中的BTI分支目标识别中会被特殊使用。
BTI如何实现?
PSTATE包含一个字段,BTYPE,记录分支类型。在执行间接分支时,间接分支的类型记录在PSTATE.BTYPE中。以下列表显示了不同分支指令的BTYPE取值:
BTYPE=11:BR、BRAA、BRAB、BRAAZ、BRABZ,使用除X16或X17之外的任何寄存器
BTYPE=10:BLR、BLRAA、BLRAB、BLRAAZ、BLRABZ
BTYPE=01:BR、BRAA、BRAB、BRAAZ、BRABZ,使用X16或X17
执行任何其他类型的指令,包括直接分支,都会将BTYPE设置为b00。
为什么要存储两个位?一个简单的实现可以记录间接分支是否正在进行中。然而,记录间接分支的类型进一步限制了查找小工具的可能性。BTI指令的语法包括一个参数,指定它可以被哪些类型的间接分支定位:

当BTYPE!=00时,处理器会检查目标指令是否是一个着陆点。如果它不是一个着陆点,或者如果它是错误类型的间接分支,将生成异常。
X16和X17
架构之所以区分使用X16或X17的间接分支和不使用的间接分支,是因为X16和X17在Arm使用的过程调用标准中具有特殊的意义。它们被称为过程内调用破坏寄存器,或称为IP0或IP1。它们可以被静态链接器用于插入分支范围扩展的veneers,或者被动态链接器用于处理跳转表。
这对我们而言是相关的,因为这意味着一个函数可能直接通过BL或BLR从调用者进入,也可能通过链接器生成的代码间接进入,使用X16或X17。因此,函数入口的着陆点需要能够接受这两种情况。
【注意】: 我们之前介绍了ALU标志,用于条件分支和条件选择。PCS规定ALU标志在函数调用之间无需保存。
对于浮点寄存器,有一套类似的规则:

这篇关于A64指令集架构之PCS过程调用标准的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







