本文主要是介绍快手+何向南团队最新论文Counterfactual Interactive Recommender System ,反事实推理融入离线强化学习,解决filter bubble/信息茧房问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文名:CIRS: Bursting Filter Bubbles by Counterfactual Interactive Recommender System

目录
- 链接
- 1. 相关背景
- 1.1 核心思想
- 2. 实证分析
- 3. 方法
- 3.1 基本思想
- 3.2 User Model
- 3.2 State Tracker
- 3.3 RL agent
- 3.3 Real Environment
- 3.4 因果模型
- 4. 总结
链接
相关链接:
中科大+快手出品 CIRS: Bursting Filter Bubbles by Counterfactual Interactive Recommender System 代码解析
论文链接在这里!
github 代码链接
高崇铭 作者主页
相关知识:
DeepFM模型
Transformer模型
PPO算法
DeepCTR库
Tianshou库
KuaiRec数据集相关链接:
CSDN讲解:KuaiRec | 快手首个稠密为99.6%的数据集 | 相关介绍、下载、处理、使用方法
论文:https://arxiv.org/abs/2202.10842
数据:https://rec.ustc.edu.cn/share/598635c0-9585-11ec-8259-414ede1f8d4f
代码:https://chongminggao.github.io/KuaiRec/
Example:http://m6z.cn/5U6xyQ
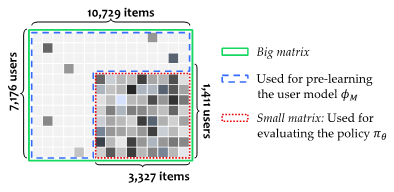
1. 相关背景
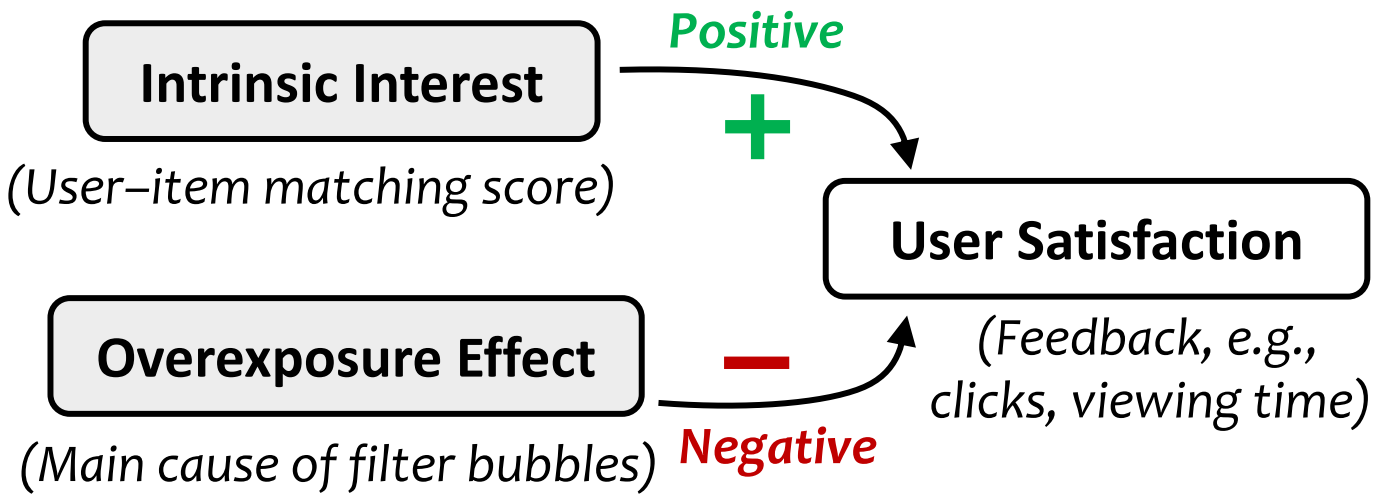
用户满意度/反馈收到用户内在兴趣(Intrinsic Interest)以及过曝光效应(Overexposure Effect)的影响,本篇论文将对二者进行解耦。
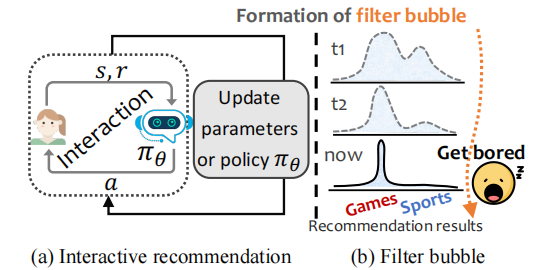
- 交互式推荐(
interactive recommendation):如图(a),agent利用用户对推荐结果的反馈信息,学习一个在线算法策略(online policy),动态地调整推荐方案,代替人工指定规则下的静态推荐算法。 - 强化学习(
Reinforcement Learning)常被用于交互式推荐场景。智能体会在与用户的多次交互中,自动学习不同场景下的决策方式,从而追求特定的最优长期收益。 filter bubble:可以理解为信息茧房;如图(b),用户刚开始的偏好有Games两类Sports,但随着推荐系统的进一步参数更新和策略迭代,推荐的结果将慢慢被用户主流兴趣主导,只推荐游戏相关项目了。这种逐渐趋于单调的推荐结果会使得用户感到疲倦,从而对推荐系统产生不信任和厌倦。- 离线强化学习(
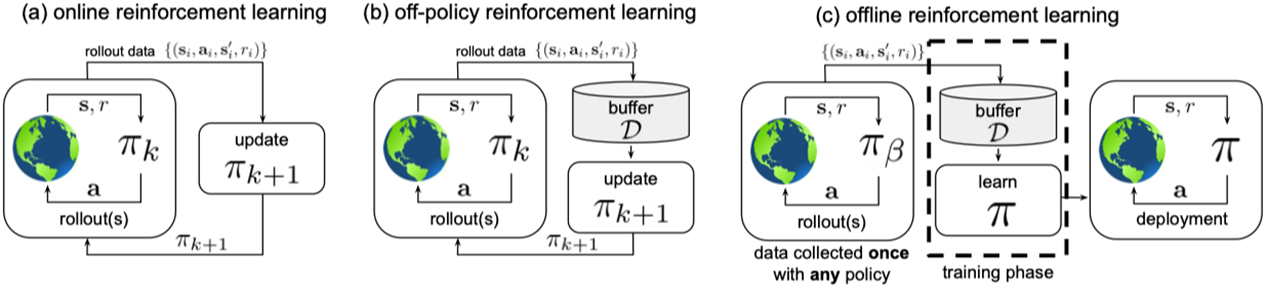
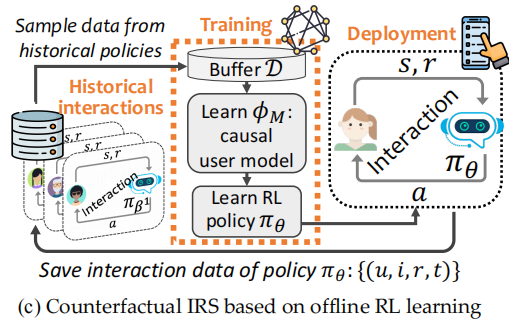
Offline RL):直接将图(a)部署到真实场景是不现实的,因为需要大量的真实用户参与模型训练过程;让用户与不成熟的系统交互,会严重影响用户体验,也会降低收益。这个时候就需要离线强化学习啦~ 如下图(c),我们先从离线数据学到一个策略,再将其放到线上场景部署。
1.1 核心思想
致力于从源头上解决目前推荐策略中存在的信息茧房问题。将强化学习这种策略模型引入生产环境的同时,利用基于反事实模型的因果推理的技术,对用户偏好中的曝光效应进行显式建模,从而在自动迭代更新决策过程的同时,有效避免“越推越窄”问题。
如下图(c)所示,我们 ① 先从离线数据中学习到一个 causal user model;② 利用学习到的user model训练RL policy;③ 将RL policy部署到线上
2. 实证分析
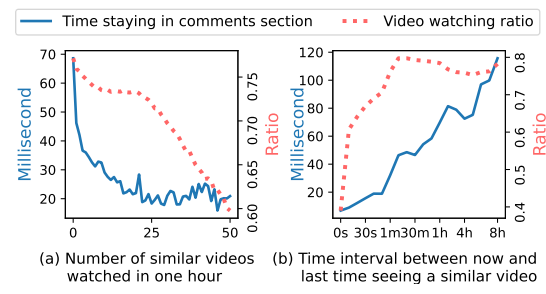
为了验证exposure effect/filter bubble是真实存在的,即 “用户看多了相似的视频,满意度会降低”,作者在快手平台上做了一系列实验。
- 衡量满意度指标: ① 在评论区停留的时间 ② 视频观看比例
- 横轴:① 一小时内观看相似视频的数量 ② 从现在起到最后一次观看类似视频的时间间隔。
- 结论:如图所示,① 推荐系统推类似产品越多,用户满意度下降越快。②推荐系统推类似产品越频繁,用户满意度下降越快
3. 方法
3.1 基本思想
基于因果推理中的反事实模型在历史交互数据学习一个能够估计用户偏好的因果用户模型(Causal user model),然后利用Causal user model产生反馈信号(reward)对基于强化学习的推荐策略(RL policy)进行规划训练,最后将学好的RL policy进行上线。
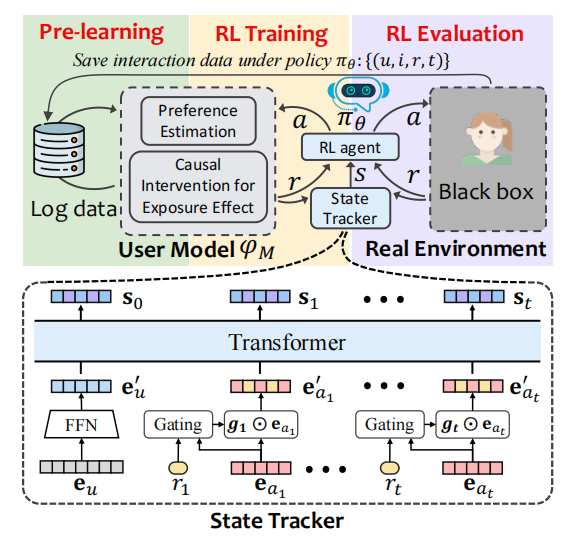
如下图所示,模型包含四个关键部分:① 因果用户模型(Causal User Model)② 基于Transformer模型的状态跟踪器(State Tracker)③ 基于强化学习的交互式推荐策略(RL Agent) ④ 真实的评估环境(Real Environment)
3.2 User Model
User Model由两部分组成:
- 偏好估计模块(
Preference Estimation):对真实用户的兴趣进行准确估计,本篇文章中就是DeepFM模型。 - 一个基于因果推理的偏好调整模块(
Causal Intervention for Exposure Effect)。在动态的交互式推荐中对于重复推荐结果进行惩罚,即计算exposure effect,然后给出负分奖励信号: y ^ u i t = r ^ u i 1 + e t ( u , i ) \hat{y}_{u i}^{t}=\frac{\hat{r}_{u i}}{1+e_{t}(u, i)} y^uit=1+et(u,i)r^ui
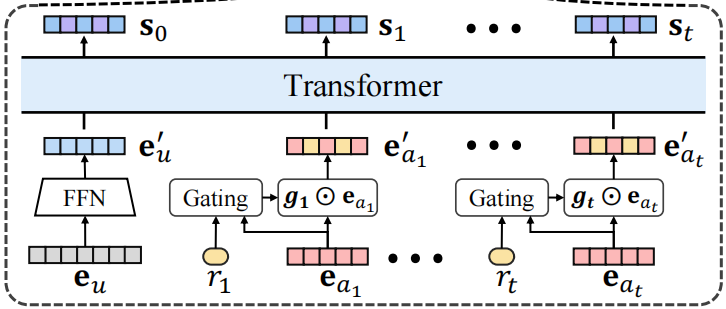
3.2 State Tracker
这部分用到了Transformer结构,挺新颖的,我之前看的论文都是用的GRU或者LSTM。
在进入transformer前,作者还构建了一个门控机制,用于将reward和action拼接起来: g t = σ ( W ⋅ \boldsymbol{g}_{t}=\sigma\left(\mathbf{W} \cdot\right. gt=σ(W⋅ Concat ( r t , e a t ) + b ) \left.\left(\mathbf{r}_{t}, \mathbf{e}_{a_{t}}\right)+\mathbf{b}\right) (rt,eat)+b)
3.3 RL agent
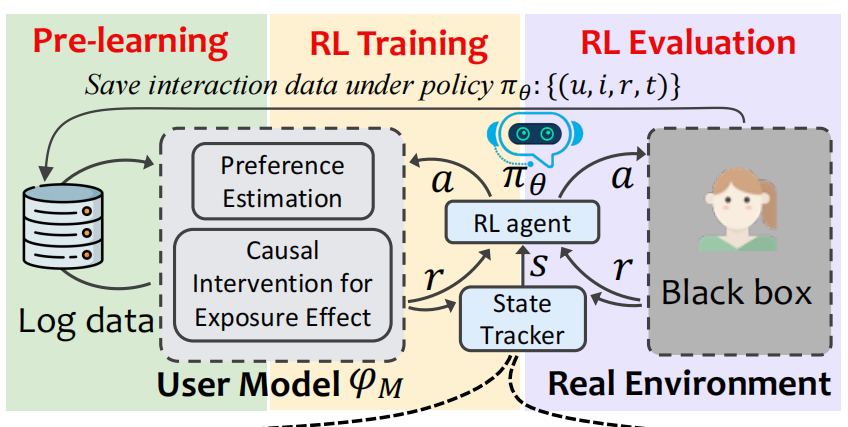
这部分是算法端的核心(上图黄色部分),主要是和上一步学习到的 User Model进行交互。
在这个交互过程中,User Model可以被视为user simulator,为交互式推荐策略提供reward。因为该奖励信号在真实情况下不存在,所以称作counterfactual reward。
这部分用到的强化学习策略为PPO,当然也可以使用别的策略 如DDPG。
3.3 Real Environment
真实的评估环境对于商业推荐公司来说,就是其产品线上的真实用户。对于算法层面来说,这个评估环境是一个黑箱模块,当算法提供推荐后,能够返回最真实的信号。这也为评价推荐策略好坏提供了标准。对应着图中的紫色部分~
这里的黑箱是由快手数据集中的全曝光小矩阵构造的~
3.4 因果模型
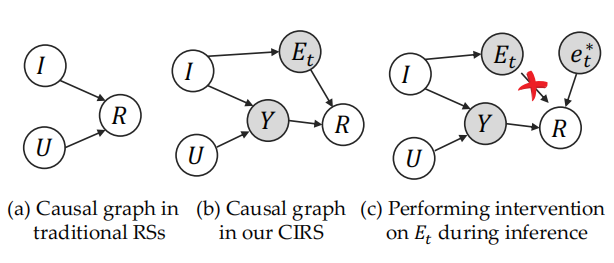
U U U代表用户喜好, I I I代表商品特性, R R R反馈, Y Y Y节点代表用户的真实喜好,而 E t E_t Et则代表当前推荐的过曝光效应(即陷入信息茧房的程度), e t ∗ e_t^* et∗是随机变量 E t E_t Et的一个具体取值。
直观来看,如果某个或某类商品被重复推荐,则过曝光效应 E t E_t Et将会偏大,用户则会感到厌倦,继而给出相对真实喜好 Y Y Y 负向的反馈信号 R R R。加了阴影的节点代表隐变量,不能通过历史数据直接观测得到。
我们假设用户最终的反馈信号是由两条路径决定:
(1)(U,I) →Y → R:这条路径刻画了用户真实兴趣对最终反馈的影响,在本文中实现为传统的DeepFM推荐模型。也可以由其他推荐模型进行实现。
(2)I → E_t→R:这条路径刻画了过曝光效应对用户最终反馈的影响。
本文对过曝光效应 E t E_t Et的定义如下:
e t = e t ( u , i ) = α u β i ∑ ( u , i l , t l ) ∈ S u k , t l < t [ e x p ( − ( t − t l ) τ × d i s t ( i , i l ) ) ] e_t= e_t (u,i)=α_u β_i ∑_{(u,i_l,t_l )∈ S_u^k,t_l<t}[exp(\frac{- (t-t_l)}{τ} × dist(i,i_l )) ] et=et(u,i)=αuβi∑(u,il,tl)∈Suk,tl<t[exp(τ−(t−tl)×dist(i,il))]
得到过曝光效应 e t e_t et后,我们可以进一步定义其对用户反馈的影响如下:
y ^ u i t = r ^ u i 1 + e t ( u , i ) \hat{y}_{u i}^{t}=\frac{\hat{r}_{u i}}{1+e_{t}(u, i)} y^uit=1+et(u,i)r^ui
即agent与user model交互时的reward
4. 总结
(1) 基于反事实因果推断的用户模型能够正确刻画推荐结果中的过曝光效应,从而在信息茧房的萌芽阶段进行探测和纠正。
(2) 基于强化学习的交互式推荐策略能够很好地掌握因果用户模型给出的反事实奖励信号,从而在与真实用户的实时交互中进行自适应的方案调整。且实验结果证明,无论环境如何变化,本发明提出的方法都能很好的工作,效果远超出对比算法。
这篇关于快手+何向南团队最新论文Counterfactual Interactive Recommender System ,反事实推理融入离线强化学习,解决filter bubble/信息茧房问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







