本文主要是介绍使用爬虫爬取某云排行榜音乐并下载,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
众所周知,使用爬虫爬取数据分为四部分,即:1.发送请求2.获取响应3.数据解析4.数据持久化保存
那么我们使用爬虫爬取某云排行榜音乐也遵循这四条规则,那我们按照这四条规则进行爬取,但在这之前我们先分析一下
(一) 分析
使用爬虫进行爬取,一定是对网页进行爬取,网页url为: https://music.163.com.疑问来了,真的是对这个url发送请求吗?我们来试一下
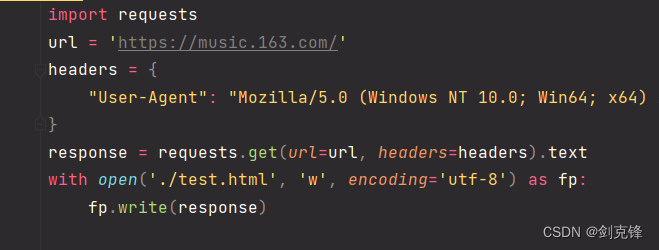
我们打开test.html看一下
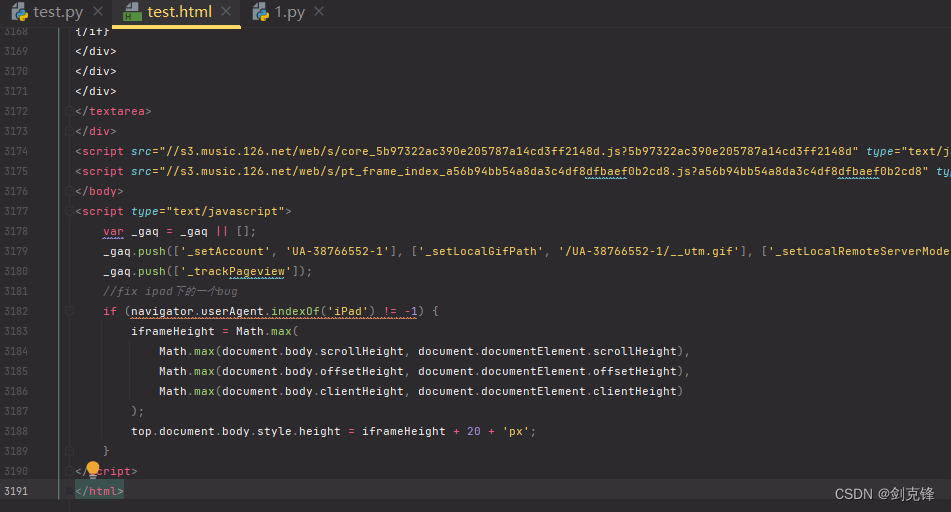
没问题,我们获取到了页面的源码数据,但我们是要爬取的是某云排行榜的音乐,所以我们要找到对应的url,我们直接在某云音乐网页进行检查分析即可
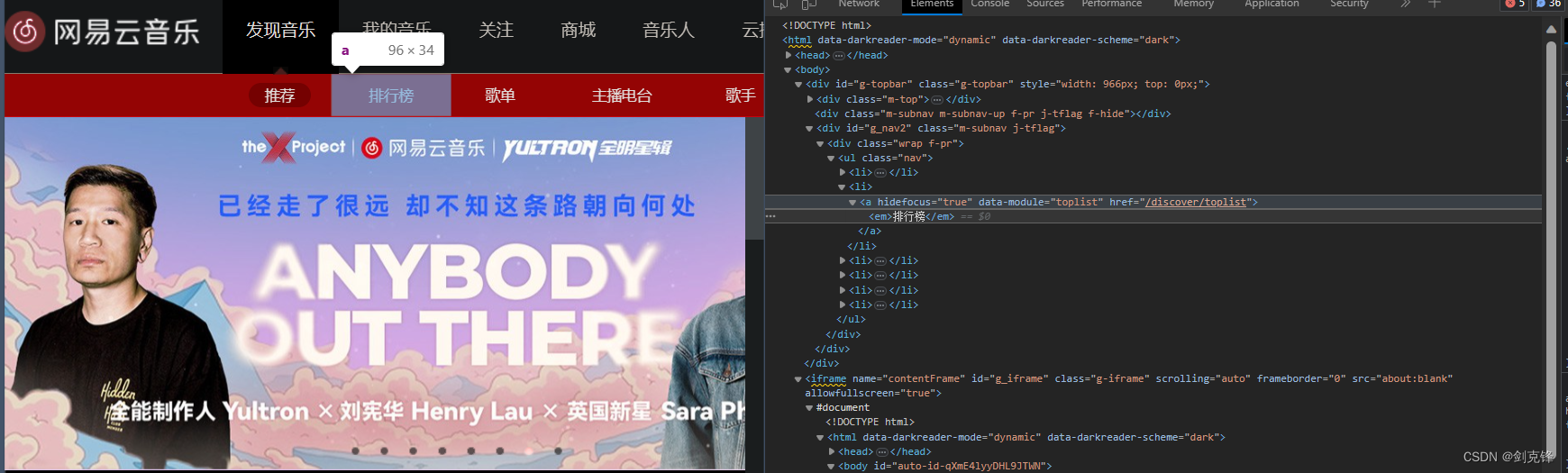
这样我们直接对这个url发送请求即可 https://music.163.com/#/discover/toplist
然后我们去分析具体的歌曲的数据都在哪里,还是使用检查进行分析即可
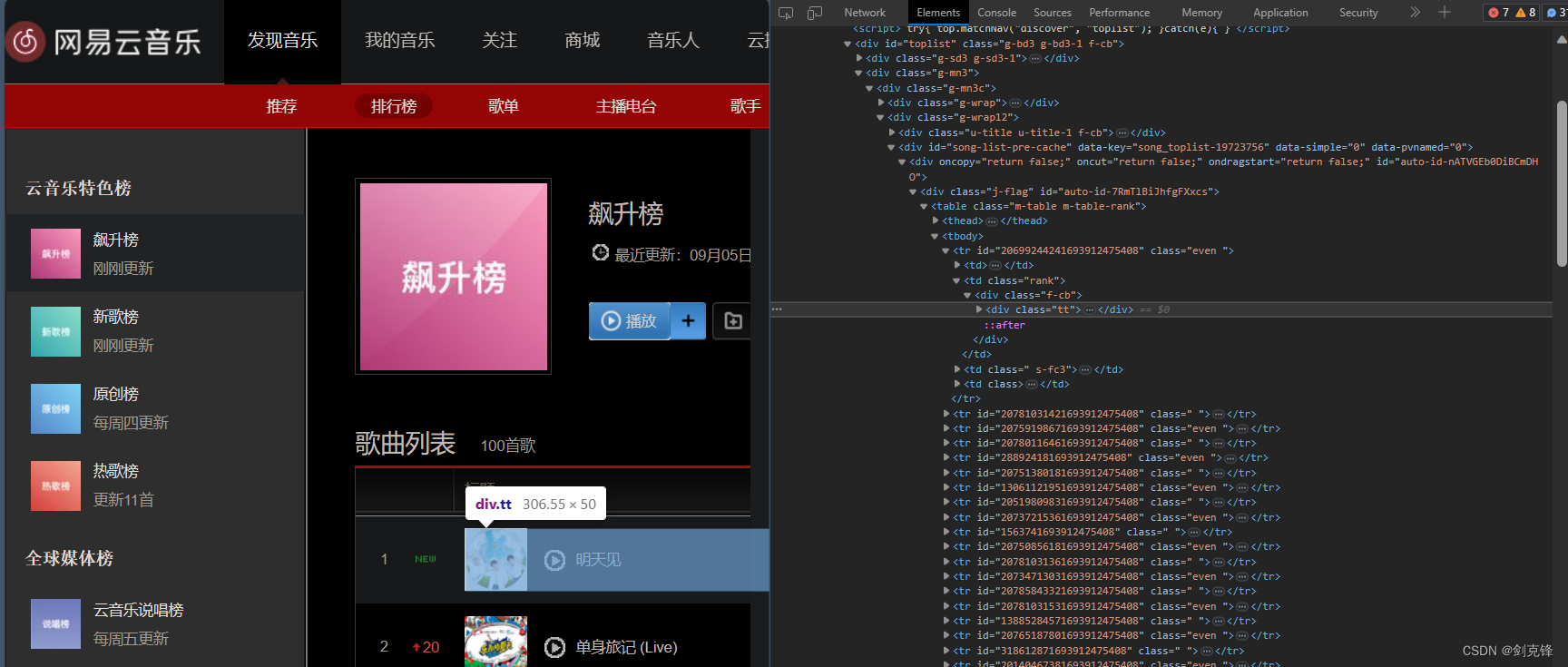
所有歌曲信息存在了tr的标签中

找到对应的href属性,跳转链接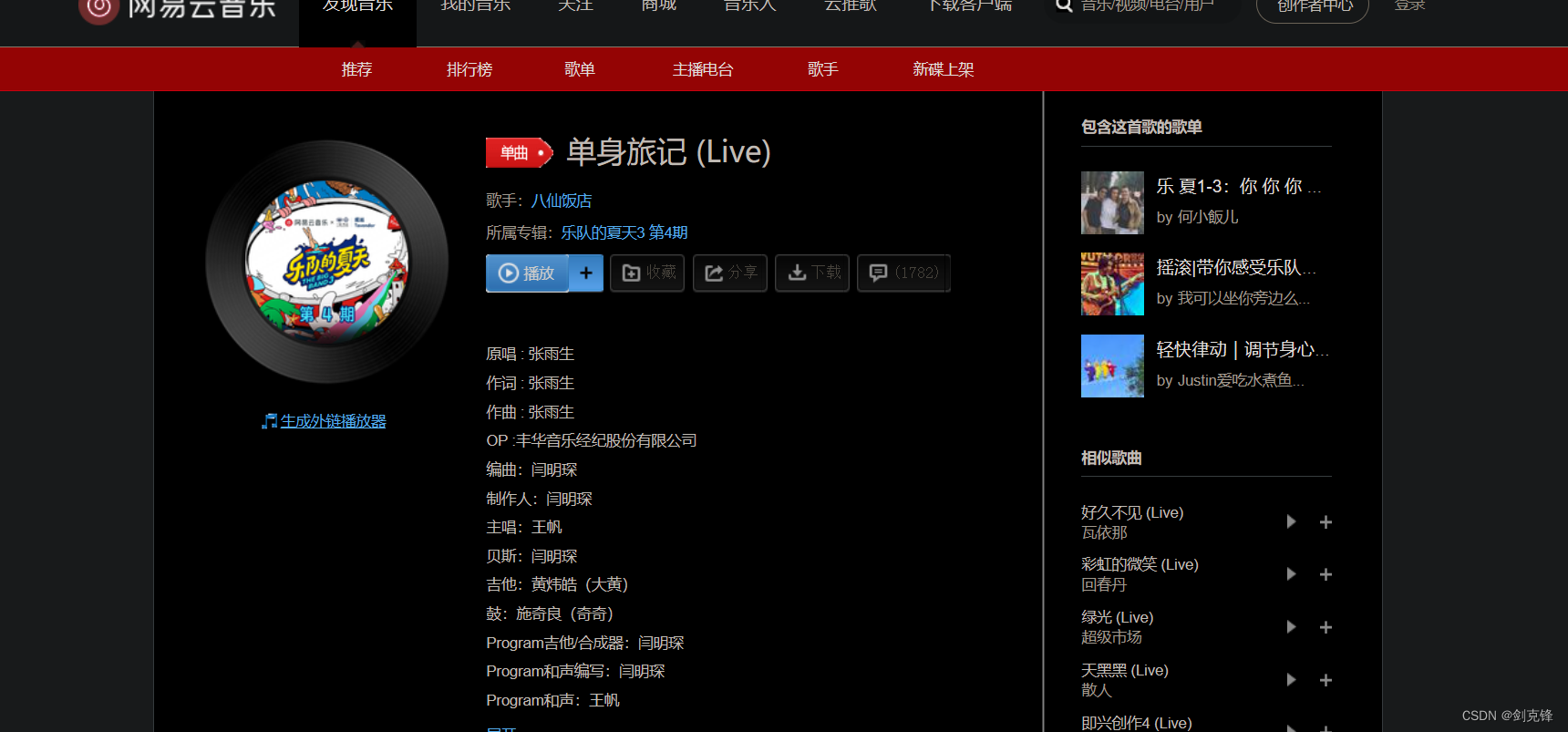
很nice,其实在上一步我就已经获取到了足够的信息了,然后我们再加上一个神奇的链接前缀,再拼接上歌曲id,
http://music.163.com/song/media/outer/url?id=
然后神奇的一幕发生了

我们就可以听到歌曲了!!!
最后基于本地持久化保存就完全OK了.理论存在,实践开始!
(二)实践
1.发送请求
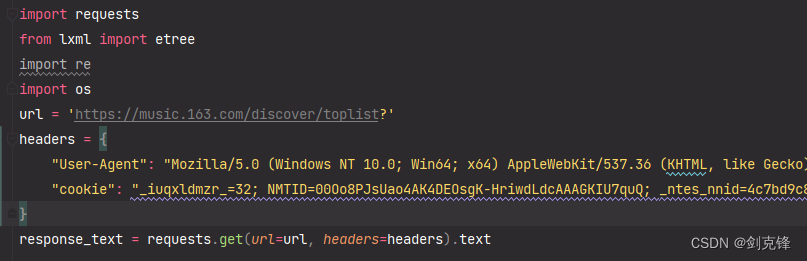
导包,进行UA伪装还有cookie验证
2.获取响应
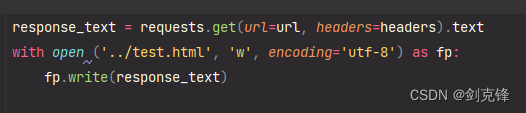
将响应数据保存到response_text,然后使用文件操作存到test.html查看情况
3/4.数据解析and数据持久化保存
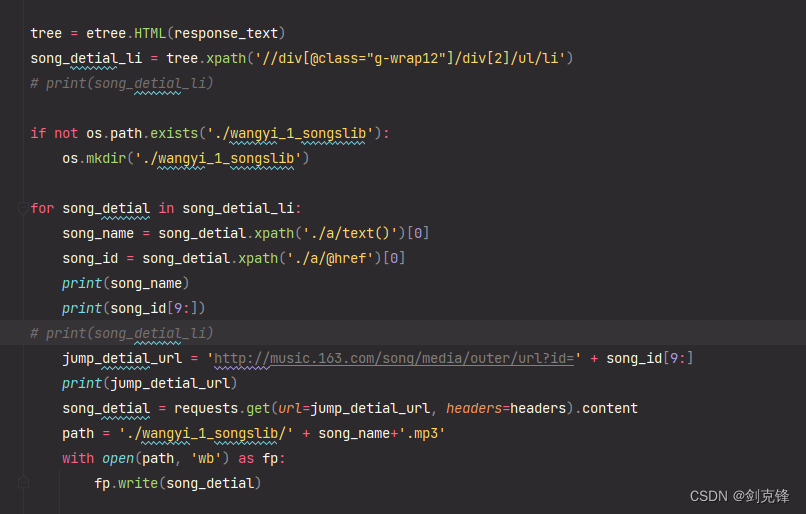
这俩是一块进行分析的,分不开,就放一块了
a.首先使用etree获取指定标签的xpath路径,并进行存储
b.然后使用os模块创建存储音乐的文件夹
c.遍历存储歌曲信息的列表,获取歌曲name和id
d.使用那个神奇的链接拼接上id就可以将歌曲信息存储到本地了
最后附上全部代码
# 马子哥最帅!
import requests
from lxml import etree
import re
import os
url = 'https://music.163.com/discover/toplist?'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.200","cookie": "_iuqxldmzr_=32; NMTID=00Oo8PJsUao4AK4DEOsgK-HriwdLdcAAAGKIU7quQ; _ntes_nnid=4c7bd9c8180d3027dbdcd463434d5600,1692775933321; _ntes_nuid=4c7bd9c8180d3027dbdcd463434d5600; WEVNSM=1.0.0; WNMCID=fudshh.1692775934568.01.0; WM_NI=vXVLtbg4JzQTqMwR%2BbRX%2BLVyO%2BjEIrMfOWxKpVEUX%2BbEjtZ72yaw2nqO7C%2BYbj6V4Ts%2F1anYLckcXLfZ75j1hCQgDZUbpxL%2FMNrVoBaOfhG1AtTLQO3WB%2FDLDmENy%2FdZaWI%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb0d266b6aca5d5f17cb78a8eb3c45e978a8fb0c53982b989aece67f6eba8b9ce2af0fea7c3b92ab6889aadf76aa5ec869bd460b393b9b3aa6a9288e5add5738df5a6a6cc7a8fba81b8fb41b48a8bb6db21a29ba695d93df2a7af98b166b391f9a4aa53a2b6fab7b760b1f1ff82ed5390bda584db48a686f9d6e93bac9d9f88c75297bec099cf258f92beb7ee4aa391aa89c63b83ac9cadd445f1898ed0c74888b38baffc25a886afb8cc37e2a3; WM_TID=foT2pc%2FQLllFFRVRUEeBnFxCJfz7s0SO; sDeviceId=YD-AjZgCi7RA9xFEhAEBFKFjQkSIfz77KwS; ntes_utid=tid._.zhCiuWwBx0hFQgAFUQOUyFhCcK2%252B6aKn._.0; playerid=15055222; JSESSIONID-WYYY=cdVrZFzEqJhu87xWFVzFBpuWajUnncWEwncFdAm5kmaNite4sAtI6u4iHwg4f%2FDMsq%5C%2B7bXdZYeFwsqO7mK4EW9vABsy4X%5CciwcthZo86Dc1D17Rk3vvGw3YiaWMMJSuU73%2Bu2aq%5CNR6kysqIIaJRvT9D5qJtD2jhz0db91zu8l7d0vo%3A1692791661013"
}response_text = requests.get(url=url, headers=headers).text
with open ('../test.html', 'w', encoding='utf-8') as fp:fp.write(response_text)tree = etree.HTML(response_text)
song_detial_li = tree.xpath('//div[@class="g-wrap12"]/div[2]/ul/li')
# print(song_detial_li)if not os.path.exists('./wangyi_1_songslib'):os.mkdir('./wangyi_1_songslib')for song_detial in song_detial_li:song_name = song_detial.xpath('./a/text()')[0]song_id = song_detial.xpath('./a/@href')[0]print(song_name)print(song_id[9:])
# print(song_detial_li)jump_detial_url = 'http://music.163.com/song/media/outer/url?id=' + song_id[9:]print(jump_detial_url)song_detial = requests.get(url=jump_detial_url, headers=headers).contentpath = './wangyi_1_songslib/' + song_name+'.mp3'with open(path, 'wb') as fp:fp.write(song_detial)效果如下图所示

如果你觉得这篇文章对你有帮助的话请给博主点个赞吧
这篇关于使用爬虫爬取某云排行榜音乐并下载的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



