本文主要是介绍客户细分方法论全解及行业应用 by彭文华,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是彭文华的第161篇原创,顺便给您拜年了!

今天是大年初一,我给您拜年了!祝我的好朋友:
显神功牛刀小试,
勤学习汗牛充栋;
进财源多如牛毛,
涨运势牛气冲天!
今天的问题来自于上海的李总,他在做行业客户细分。想要一些客户分级分群的相关策略和资料。我资料倒是有很多,但是不知道能不能给他一些好的建议啊。

说实话,虽然我之前做过很多客户分级分群,但是总感觉做的不太行。网上类似的文章也很多,看来看去无非也就这么些东西。我就给大家分享一下我的理解吧。
另外,我在挑战春节不打烊,每天都分享原创文章,欢迎加我个人微信:shirenpengwh,加入催更群,小鞭子催我快快写稿![]()
至简式客户细分
客户细分的核心目的是精细化运营。其实就是对不同的用户分别制定运营策略,期望实现利益最大化。
所以客户细分最朴素的思想,就是切分。大家应该听过一个词“高净值人群”,这是传统营销时代流传最广的客户分群产物。
一般来说,用户细分得遵守MECE原则,上面所有的方法其实都已经是MECE了。但是也不是绝对的,后面就有特例。
受限于当时的数据和技术,客户细分大多都还是在CRM中进行因为只有在CRM中才能获取用户的各种信息。细分的逻辑也就非常简单了,大多是从某一个单一维度进行切分。
比如“按客户净值分、按客户数据来源分、按消费频次分、按年龄段分、按当月累计消费金额段分”等。这种客户切分方式比较原始和粗糙,远远称不上“客户细分”。但是这种切分方式是所有人最容易想到,也是最容易理解的方式。
所以在早期的数据交易中,卖家会标注上数据来源,企图在名称上体现客户数据的价值。当然现在买卖个人隐私数据已经入刑法了,大家千万别碰哈。
业务分析式客户细分
再进一步,就有人从各个角度总结提炼客户细分的逻辑,比如从用户生命周期上细分,我们对不同处在生命周期的客户用不同的策略,期望拉长用户在成熟期的时间,创造更多的价值。
比如:
按用户生命周期分,如“潜在用户、新用户、付费用户、复购用户、流失用户”等,不同行业的生命周期不完全一样;
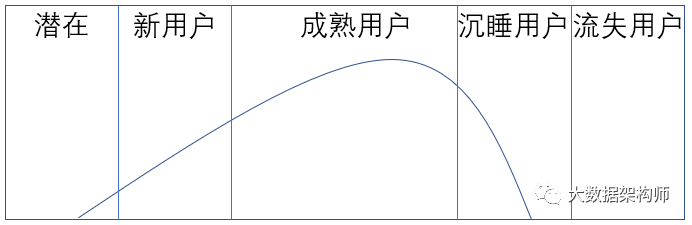
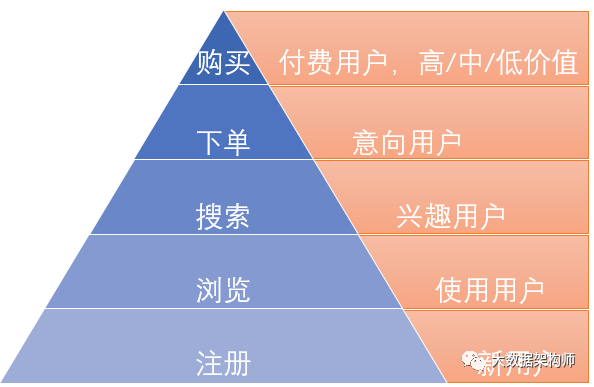
按用户运营流程分,如AARRR、RARRA、“新用户、使用用户、兴趣用户、意向用户、付费用户”等;
按用户积分等级分(忠诚度),如传统的会员卡级别、淘宝的“皇冠、钻石”等;
按用户的各种标签切分,这个自由度就非常大了,信息非常丰富。
这些方法都非常直观,业务部门最喜欢了。而且对应的策略也非常清晰,基本上顾名就能思义。
这些看上去还是从某一个固定的维度对客户进行切分,但是一般来说这些维度都是经过业务理解、加工之后的。
举个简单的例子:信用卡的不同级别就是一个附带非常复杂规则的客户细分模型。只有达到了某几个条件,才能升级卡片的等级。当然,享受到的权益也是不一样的。市场上甚至有专门研究信用卡养卡规则的人和公司。
组合式客户细分套路
前面说的都是从单一维度对客户进行群体切分的方法,这种单一维度我们可以相处很多很多。
那如果再往前进一步,我们还能怎么细分呢?答对了!那就可以对各单属性进行组合后细分,RFM就是典型的一种。
这个模型非常好用,流传很广,认同度高,可解释强,对应的策略也很清楚。
RFM模型,就是用户细分的经典模型。它就是用“最近一次消费 (Recency)”、”消费频率 (Frequency)”、”消费金额 (Monetary)”,对用户切三刀,划分成为8个群体,然后来区别对待。
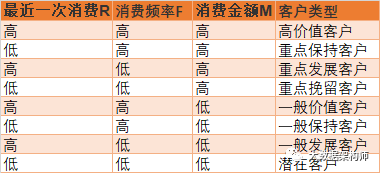
其实RFM本质上是一种象限模型,只不过不是4象限,而是3个指标,每个指标离散为0和1,总共分为8个象限。而且我们在用RFM的时候,也可以进行各种变种,比如改掉一个指标、把“高、低”区分为“高、中、低”等等。但是不管咋变,本质还是一样。
RFM的变种之一就是替换RFM中的M,比如RF+年龄段。当然,只要你能想出来,可以任意组合,比如当月消费等级+用户年龄段+地区等。之前我做过汽车行业的用户细分,就做过客户偏好+投诉频次+活动参与的组合维度,可以分辨出忠诚客户还是难缠客户。
一样啊,这种方式几乎可以无限组合,只要你能想出来,随便拿两个以上的关键业务指标一组合,立刻可以把客户切分成任意群体。
移动通信领域对客户群体的细分也是做到了机制,各种乱七八糟的套餐可不是运营人员瞎想出来的,而是使用不同组的数据,通过各种各种算法算出来的。
提到算法,我们还可以用各种聚类算法实现客户细分。但是这些算法计算的结果,业务可解释性就比前面所有的细分方法差多了。而且有些算法存在随机种子等因素,每次执行的结果不一样。比如K-means的聚类,这个K值要么人为设定,要么随机。这随机就随出事情了。同样一份数据,很可能就出现下面这种截然不同的情况。
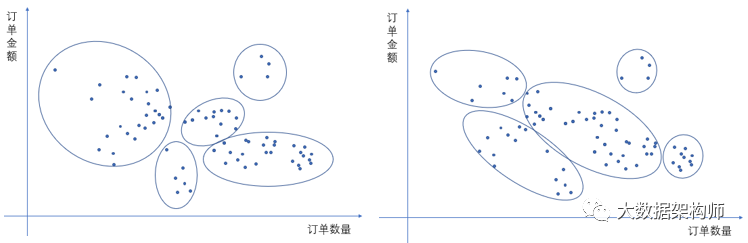
这种情况让我们给业务解释的时候非常困难,全都得靠编。有一次更搞笑,我们某甲方要“大数据”+“算法”,而且必须要保证执行幂等,就是每次执行的结果必须一样,要不没法给别人解释。遇到聚类这种含有随机数的情况,那可不行了。最后我们给把算法给改了,只要是一个结果集进去,不管怎么执行,都是一个结果。唉,我们太难了。
当然,除了K-Means之外,我们还能用KNN、层次聚类等等各种聚类算法。除了层次聚类稍微好解释一些之外,其他算法计算结果都得靠编![]() 。更不用提对应的运营策略了。
。更不用提对应的运营策略了。
那有没有更好的客户分群方法呢?当然有的。
业务洞察式客户细分
可能有哥们说了,你说的这些我都知道,用处说实话也不大。
这话得分怎么说了,如果说只是客户细分,咱就这些招。但是如果说指导运营,那得具体分析各层用户的问题,后面还得带上恰当的运营建议。得跟运营同学一起定好策略,制定执行计划,跟进,调整,优化。
不过,咱说回来,除了这些招之外,咱还有更经典的用户细分方法吗?
答案是“有”!
但是再往前一步就不能是通用的方法了,最少得细分到行业和具体场景了。比如快消行业就有非常经典的“阿里八类人群”:

所有快消行业都可以参照这八大类进行客户细分。这里你可能就会注意到,这明显就不符合MECE的原则嘛!是的,但是这八大类已经涵盖绝大部分人群了,剩下那一星半点的也不影响全局。
那这八大类是怎么来的呢?业务洞察!没别的招。
当然有些洞察也很有意思,还会从用户的“星座”角度上进行分析,也不知道是不是故弄玄虚。比如腾讯帮喜茶做的用户洞察就有这样的结论:

也有很多业务洞察会与社会现状进行结合,也就是传说中的PEST模型(政治politics,经济economy,社会society,技术technology)。比如:

你看上面细分的,从数学角度上根本没啥逻辑么。也完全不符合MECE原则,各部分之间还有交差,但是丝毫不影响其业务解释力。因为里面夹杂着对当今社会各种现象的洞察。
京东和尼尔森对用户生命周期也做了非常深入的研究,他们的洞察也很有意思。他们提出的口号是“实现品牌用户资产波浪式增长”:
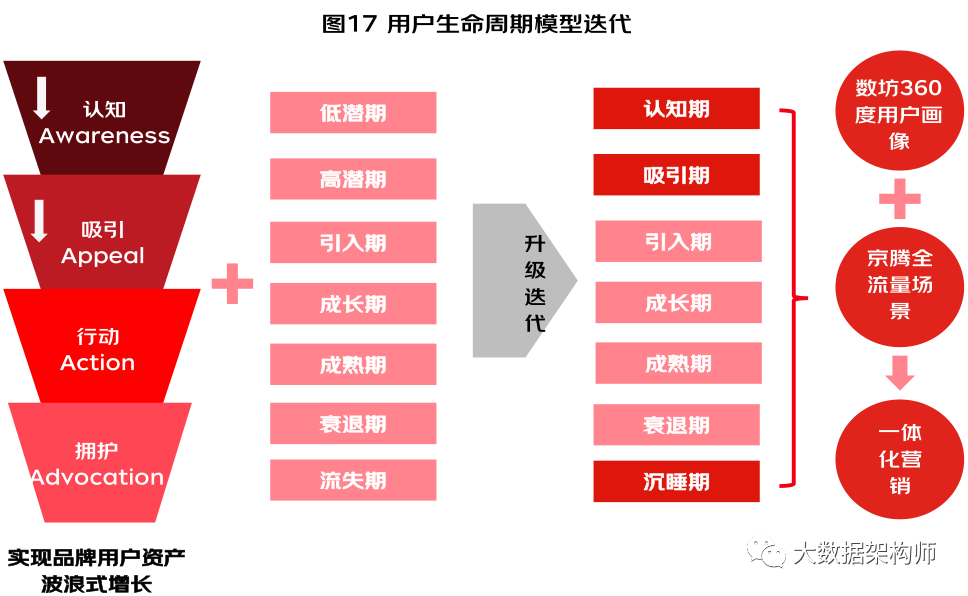
总结
用户细分是精细化运营的重要手段。
最朴素的思想,就是从某个固定的属性对用户进行切分,比如按客户净值;
再进一步,是从业务分析的角度进行切分,比如按用户生命周期;
再进一步,是将多个维度组合之后进行切分,比如流传很广的RFM模型,或者使用KNN、K-Means、层次聚类等各种聚类算法。
往前一步就是行业特殊洞察了,甚至是垂直领域的特殊洞见,这就得有很深的行业用户洞察能力,比如阿里提出的快消领域“八大类人群”。
我手上有几十份不同行业的用户细分洞察报告,各位可以下载下来参考一下。
至于技术实现,其实数据量不大的话,用excel就能搞定;数据量多一些就用关系型数据库,写SQL搞定;再多的话就用大数据平台,用分布式计算处理了。
用算法进行客户分群的技术实现,在传统营销时代,更多的人用的是SPSS、SAS等数据挖掘软件;之前有一阵子还流行过R语言;现在Python当道,如日中天。用起来非常简单,基本上就是组织数据结构,然后调个包就可以了。
今天的分享就是这样。欢迎大家加我个人微信号:shirenpengwh ,一起探讨大数据、数据分析相关知识。每天分享一篇原创内容给大家,我们一起学习,共同进步。
扩展阅读:几十份行业用户细分洞察报告,公众号“大数据架构师”后台回复“用户细分”即可下载。
配合以下文章享受更佳
热文 | 如何搭建一个数据分析体系
干货 | 利用峰值体验打造最强用户激活体系!
干货 | 什么才叫做懂业务?分析的5个层次
思考 | 为什么说你的运营团队一定要有一名女生?
干货 | 月薪3000和30000的数据分析师差在哪?
干货 | 如何撬动组织的力量打造一个超级获客系统?
我需要你的转发,小小的满足一下我的虚荣心
这篇关于客户细分方法论全解及行业应用 by彭文华的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





