本文主要是介绍LFU缓存(Leetcode460),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
例题:

分析:
这道题可以用两个哈希表来实现,一个hash表(kvMap)用来存储节点,另一个hash表(freqMap)用来存储双向链表,链表的头节点代表最近使用的元素,离头节点越远的节点代表最近最少使用的节点。
注意:freqMap 的 key 为节点的使用频次。
下图是freqMap的结构:
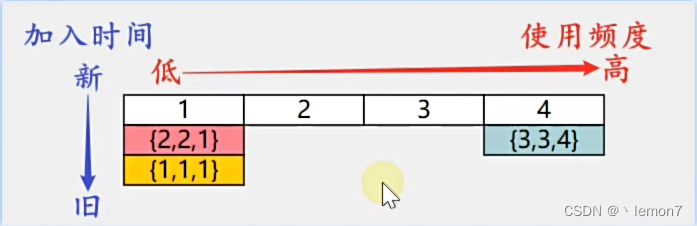
这是kvMap: 它的key没有什么特殊含义,value是储存的节点
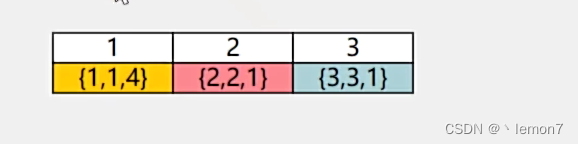
题目中调用get方法会增加元素的使用次数(freq),这时在freqMap中需要将该节点转移到对应的位置上(比如该节点使用了两次,那就把该节点转移到key为2的位置上去)
put方法分为两种情况:如果要添加的key不存在,说明是新元素,放到key为1的位置上,如果key存在,此时是修改操作,改变元素的value值,对应的频次+1,同样放到对应的位置上。
淘汰策略:要保证两个hash表中的节点数一致。
代码实现:
package leetcode;import java.util.HashMap;//设计LFU缓存
public class LFUCacheLeetcode460 {static class LFUCache {static class Node{Node prev;Node next;int key;int value;int freq = 1;public Node(){}public Node(int key, int value) {this.key = key;this.value = value;}}static class DoublyLinkedList{Node head;Node tail;int size;public DoublyLinkedList(){head = tail = new Node();head.next = tail;tail.prev = head;}//头部添加 head<->1<->2<->tail 添加3public void addFirst(Node node){Node oldFirst = head.next;oldFirst.prev = node;head.next = node;node.prev = head;node.next = oldFirst;size++;}//指定节点删除 head<->1<->2<->3<->tail 删除2public void remove(Node node){Node prev = node.prev;Node next = node.next;prev.next = next;next.prev = prev;size--;}//删除最后一个节点public Node removeLast(){Node last = tail.prev;remove(last);return last;}//判断双向链表是否为空public boolean isEmpty(){return size == 0;}}private HashMap<Integer,Node> kvMap = new HashMap<>();private HashMap<Integer,DoublyLinkedList> freqMap = new HashMap<>();private int capacity;private int minFreq = 1;public LFUCache(int capacity) {this.capacity = capacity;}/** 获取节点 不存在:返回 -1* 存在: 增加节点的使用频次,将其转移到频次+1的链表中* 判断旧节点所在的链表是否为空,更新最小频次minFreq* */public int get(int key) {if(!kvMap.containsKey(key)){return -1;}Node node = kvMap.get(key);//先删除旧节点DoublyLinkedList list = freqMap.get(node.freq);list.remove(node);//判断当前链表是否为空,为空可能需要更新最小频次if(list.isEmpty() && node.freq == minFreq){minFreq++;}node.freq++;//将新节点放入新位置,可能该频次对应的链表不存在,不存在需要创建freqMap.computeIfAbsent(node.freq, k -> new DoublyLinkedList()).addFirst(node);return node.value;}/** 更新* 将节点的value更新,增加节点的使用频次,将其转移到频次+1的链表中* 新增* 检查是否超过容量,若超过,淘汰minFreq链表的最后节点* 创建新节点,放入kvMap,并加入频次为 1 的双向链表* */public void put(int key, int value) {if(kvMap.containsKey(key)){ //更新Node node = kvMap.get(key);DoublyLinkedList list = freqMap.get(node.freq);list.remove(node);if(list.isEmpty() && node.freq == minFreq){minFreq++;}node.freq++;freqMap.computeIfAbsent(node.freq, k -> new DoublyLinkedList()).addFirst(node);node.value = value;}else{ //新增//先判断容量是否已满if(kvMap.size() == capacity){//执行淘汰策略Node node = freqMap.get(minFreq).removeLast();kvMap.remove(node.key);}Node node = new Node(key, value);kvMap.put(key, node);//加入频次为1的双向链表freqMap.computeIfAbsent(1, k -> new DoublyLinkedList()).addFirst(node);minFreq = 1;}}}public static void main(String[] args) {LFUCache cache = new LFUCache(2);cache.put(1, 1);cache.put(2, 2);System.out.println(cache.get(1)); // 1 freq=2cache.put(3, 3);System.out.println(cache.get(2)); // -1System.out.println(cache.get(3)); // 3 freq=2cache.put(4, 4);System.out.println(cache.get(1)); // -1System.out.println(cache.get(3)); // 3 freq=3System.out.println(cache.get(4)); // 4 freq=2}
}
这篇关于LFU缓存(Leetcode460)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



