本文主要是介绍Backtrader 文档学习- Observers - Benchmarking,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Backtrader 文档学习- Observers - Benchmarking
1.概述
backtrader包括两种不同类型的对象,可以帮助跟踪:
- Observers 观察者
- Analyzers 分析器
在分析器领域中,已有TimeReturn对象,用于跟踪整个组合价值(即包括现金)的回报率的演变。
显然作为观察者,在添加一些基准测试的同时,还可做一些工作,将观察者和分析器组合在一起,跟踪相同的对象指标。
Observers 和 Analyzers 之间的主要区别:
- Observers 的lines特性,它记录每个值,更适合绘图和实时查询,当然会消耗更多的内存。
- Analyzers 通过get_analysis方法返回一组结果,实现可能不会在运行结束之前提供任何结果,所以Analyzers记录最终结果,内存消耗小。
2.Analyzers - Benchmarking
标准的TimeReturn分析器已扩展为支持跟踪数据源。涉及的两个主要参数:
- timeframe(默认值:None)
如果为None,则将报告整个回测期间的完整回报
传递TimeFrame.NoTimeFrame以考虑没有时间限制的整个数据集 - data(默认值:None)
跟踪参考资产而不是组合价值。
注意:
此数据必须已经使用addata、resampledata或replaydata将其添加到cerebro实例中
可以跟踪组合的年度回报率
import backtrader as btcerebro = bt.Cerebro()
#年度回报率
cerebro.addanalyzer(bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Years)... # add datas, strategies ...results = cerebro.run()
strat0 = results[0]# If no name has been specified, the name is the class name lowercased
# 所有加载数据组合的分析结果
tret_analyzer = strat0.analyzers.getbyname('timereturn')
print(tret_analyzer.get_analysis())
如果跟踪单一数据的回报率:
import backtrader as btcerebro = bt.Cerebro()data = bt.feeds.OneOfTheFeeds(dataname='abcde', ...)
cerebro.adddata(data)
# 分析器指定数据
cerebro.addanalyzer(bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Years,data=data)... # add strategies ...results = cerebro.run()
strat0 = results[0]# If no name has been specified, the name is the class name lowercased
# 分析指定数据的分析结果
tret_analyzer = strat0.analyzers.getbyname('timereturn')
print(tret_analyzer.get_analysis())在这里插入代码片
如果两者都要跟踪,最好是给分析器指定名称:
import backtrader as btcerebro = bt.Cerebro()data = bt.feeds.OneOfTheFeeds(dataname='abcde', ...)
cerebro.adddata(data)
#跟踪单一数据的分析器
cerebro.addanalyzer(bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Years,data=data, _name='datareturns')
#跟踪组合数据的分析器
cerebro.addanalyzer(bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Years)_name='timereturns')... # add strategies ...results = cerebro.run()
strat0 = results[0]# If no name has been specified, the name is the class name lowercased
#跟踪组合数据的分析结果
tret_analyzer = strat0.analyzers.getbyname('timereturns')
print(tret_analyzer.get_analysis())
#跟踪单一数据的分析结果
tdata_analyzer = strat0.analyzers.getbyname('datareturns')
print(tdata_analyzer.get_analysis())
3.Observers - Benchmarking
可以参考前面分析器的基准,对比看区别。
由于后台机制允许在观察器内部使用分析器,增加了两个新的观察器:
- TimeReturn
- Benchmark
observers和analyzers,两者都使用 bt.analyzers.TimeReturn分析器来收集结果。
与上面的代码不同,完整的示例运行,展示它们的功能区别。
4.Observing TimeReturn
python ./observer-benchmark.py --plot --timereturn --timeframe notimeframe
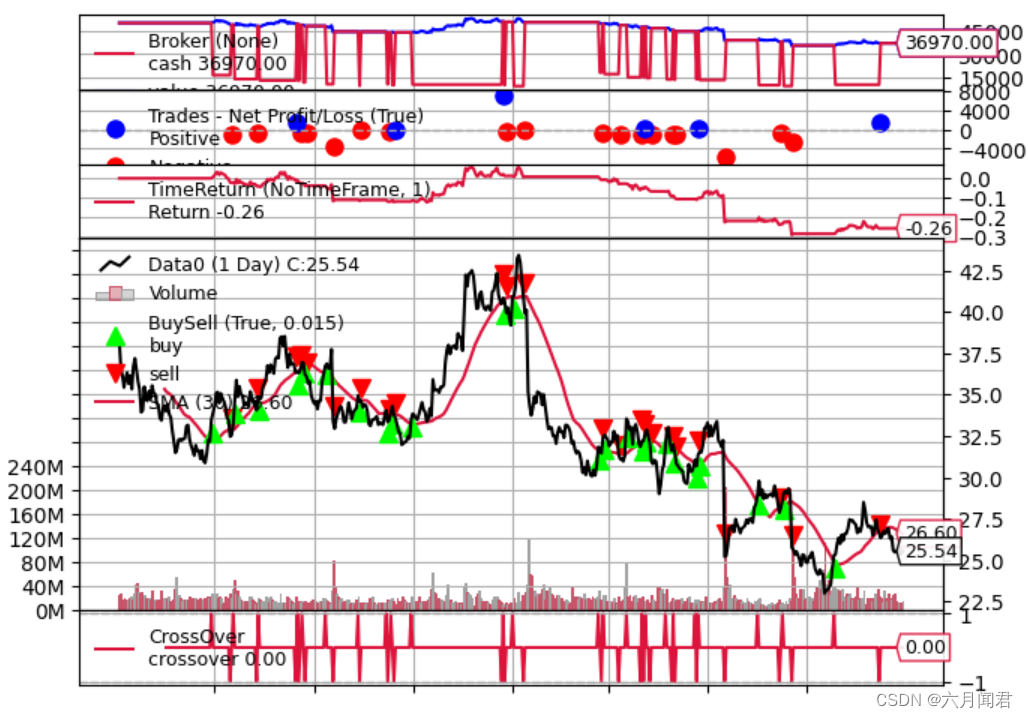
注意选项:
- timereturn 告诉样本只做这件事
- timeframe notimeframe 告诉分析器考虑整个数据集,而不考虑时间范围。
最后绘制的值为-0.26。
- 起始现金(从图表中可以明显看出)为50K货币单位,该策略最终为36970货币单位,因此价值下降了-26%。
与图示的回报率一致。
5.Observing Benchmarking
基准测试也将显示timereturn结果,所以让我们在基准测试处于活动状态时运行相同的操作:
python ./observer-benchmark.py --plot --timeframe notimeframe
没有timereturn参数
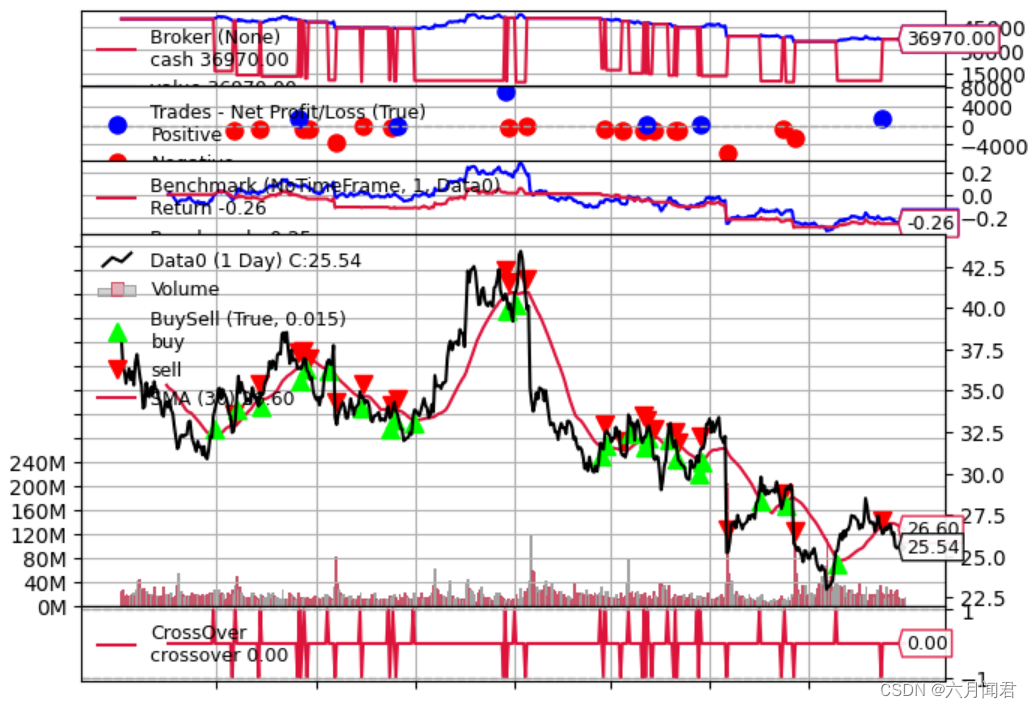
- 策略优于资产:-0.26 vs -0.33
值得庆祝,但至少清楚,这个策略没有资产那么糟糕。
可惜上图的0.26 和 0.33 的图示重合了 ,不够清晰。
以年度为基础跟踪:
python ./observer-benchmark.py --plot --timeframe years
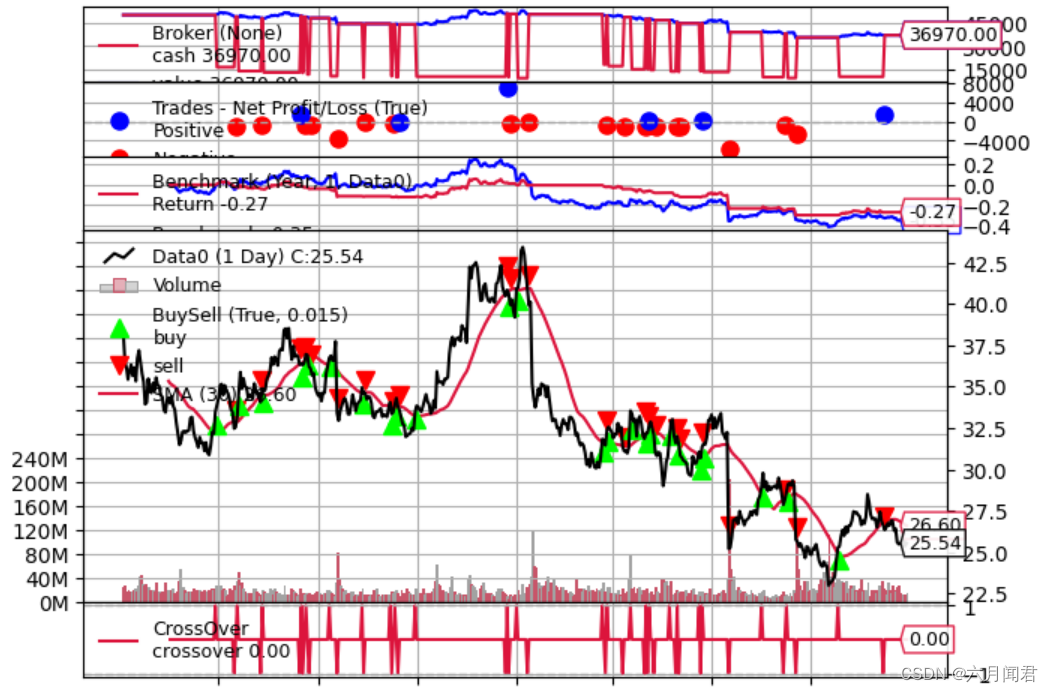
-
策略最后值从-0.26到-0.27变化很小
-
另一方面,资产显示的最终值为-0.35(与上面的-0.33相比)
价值如此接近的原因是,从2005年到2006年,策略和基准资产几乎都处于2005年初的起步水平。
切换到较低的时间框架,例如week,整个情况就会发生变化:
python ./observer-benchmark.py --plot --timeframe weeks
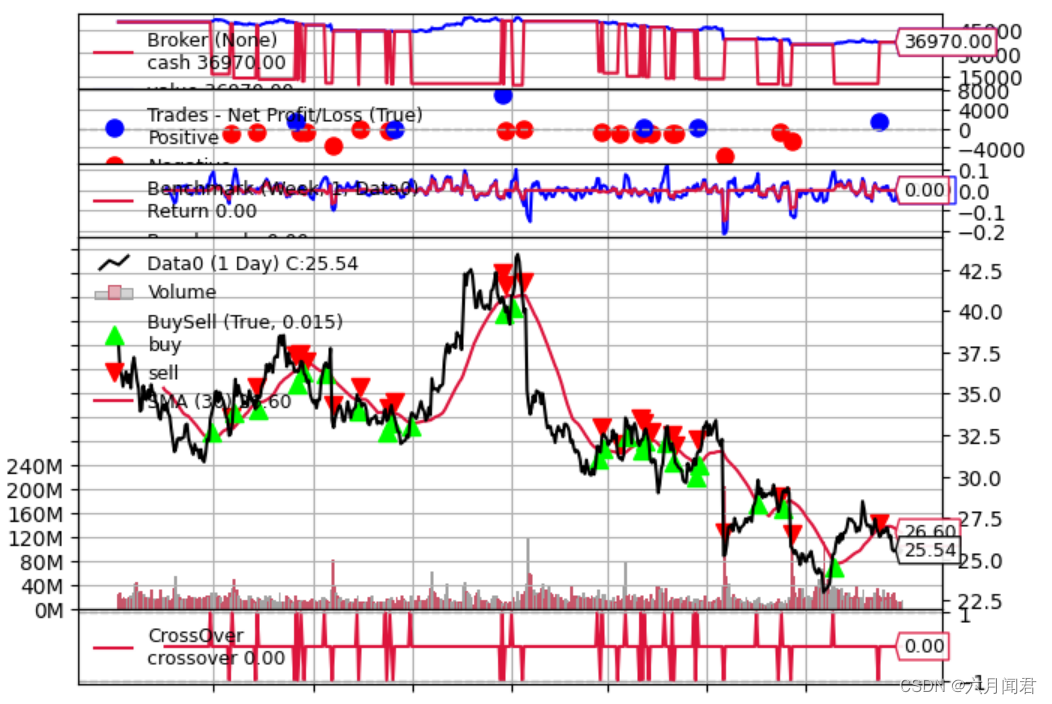
现在:
- Benchmark观察者显示出紧张(波动)状态,因为现在跟踪组合和数据的每周回报率数字上下波动
- 由于去年的最后一周没有交易活动,资产几乎没有变动,因此最后显示的值为0.00(最后一周之前的最后收盘价为25.54,样本数据收盘价为25.55,差异体现在第四个小数点上才能区分)
6.Observing Benchmarking - Another data
示例使用不同的数据进行基准测试。默认情况下,使用数据 benchdata1以Oracle公司为基准。考虑使用-time frame not time frame的整个数据集 。
python ./observer-benchmark.py --plot --timeframe notimeframe --benchdata1
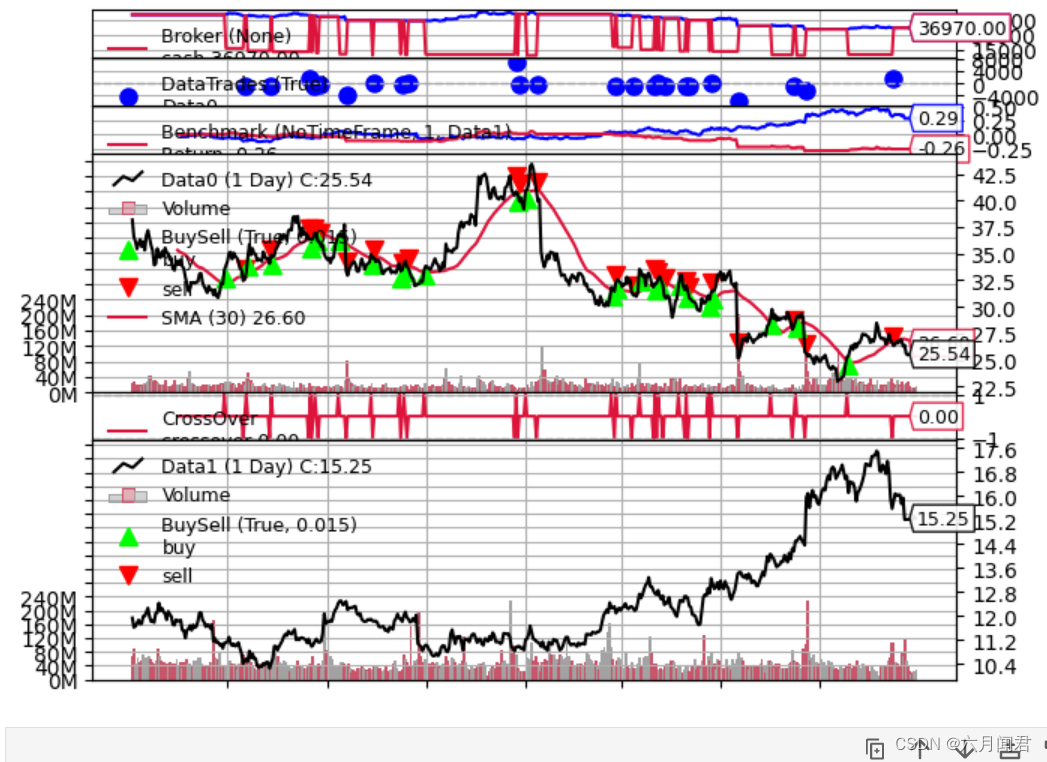
现在就很清楚没有庆祝的理由:
- 原yahoo数据,策略对于notimeframe没有改变,仍然为-26%(-0.26)
- 但对oracle数据进行基准测试时,该数据在同一时期内增长了+23%(0.23)
既可以改变策略,也可以改变资产对象,才能更好地进行交易。
可以理解为:策略可能不适用于某个股票,股票可能也不适用于某个策略
7.Concluding
现在有两种使用相同的基础代码/计算来跟踪TimeReturn和Benchmark的方法 :
- Observers 观察者(TimeReturn和Benchmark)
- Analyzer分析器(带有data参数的TimeReturn和TimeReturn)
当然,基准测试并不能保证盈利,只是比较。
代码的Help
usage: ipykernel_launcher.py [-h] [--data0 DATA0] [--data1 DATA1][--benchdata1] [--fromdate FROMDATE][--todate TODATE] [--printout] [--cash CASH][--period PERIOD] [--stake STAKE] [--timereturn][--timeframe {None,days,weeks,months,years,notimeframe}][--plot [kwargs]]Benchmark/TimeReturn Observers Sampleoptional arguments:-h, --help show this help message and exit--data0 DATA0 Data0 to be read in (default:./datas/yhoo-1996-2015.txt)--data1 DATA1 Data1 to be read in (default:./datas/orcl-1995-2014.txt)--benchdata1 Benchmark against data1 (default: False)--fromdate FROMDATE Starting date in YYYY-MM-DD format (default:2005-01-01)--todate TODATE Ending date in YYYY-MM-DD format (default: 2006-12-31)--printout Print data lines (default: False)--cash CASH Cash to start with (default: 50000)--period PERIOD Period for the crossover moving average (default: 30)--stake STAKE Stake to apply for the buy operations (default: 1000)--timereturn Use TimeReturn observer instead of Benchmark (default:None)--timeframe {None,days,weeks,months,years,notimeframe}TimeFrame to apply to the Observer (default: None)--plot [kwargs], -p [kwargs]Plot the read data applying any kwargs passed Forexample: --plot style="candle" (to plot candles)(default: None)
8.代码
from __future__ import (absolute_import, division, print_function,unicode_literals)import argparse
import datetime
import randomimport backtrader as btclass St(bt.Strategy):params = (('period', 10),('printout', False),('stake', 1000),)def __init__(self):sma = bt.indicators.SMA(self.data, period=self.p.period)self.crossover = bt.indicators.CrossOver(self.data, sma)def start(self):if self.p.printout:txtfields = list()txtfields.append('Len')txtfields.append('Datetime')txtfields.append('Open')txtfields.append('High')txtfields.append('Low')txtfields.append('Close')txtfields.append('Volume')txtfields.append('OpenInterest')print(','.join(txtfields))def next(self):if self.p.printout:# Print only 1st data ... is just a check that things are runningtxtfields = list()txtfields.append('%04d' % len(self))txtfields.append(self.data.datetime.datetime(0).isoformat())txtfields.append('%.2f' % self.data0.open[0])txtfields.append('%.2f' % self.data0.high[0])txtfields.append('%.2f' % self.data0.low[0])txtfields.append('%.2f' % self.data0.close[0])txtfields.append('%.2f' % self.data0.volume[0])txtfields.append('%.2f' % self.data0.openinterest[0])print(','.join(txtfields))if self.position:if self.crossover < 0.0:if self.p.printout:print('CLOSE {} @%{}'.format(size,self.data.close[0]))self.close()else:if self.crossover > 0.0:self.buy(size=self.p.stake)if self.p.printout:print('BUY {} @%{}'.format(self.p.stake,self.data.close[0]))TIMEFRAMES = {None: None,'days': bt.TimeFrame.Days,'weeks': bt.TimeFrame.Weeks,'months': bt.TimeFrame.Months,'years': bt.TimeFrame.Years,'notimeframe': bt.TimeFrame.NoTimeFrame,
}def runstrat(args=None):args = parse_args(args)cerebro = bt.Cerebro()cerebro.broker.set_cash(args.cash)dkwargs = dict()if args.fromdate:fromdate = datetime.datetime.strptime(args.fromdate, '%Y-%m-%d')dkwargs['fromdate'] = fromdateif args.todate:todate = datetime.datetime.strptime(args.todate, '%Y-%m-%d')dkwargs['todate'] = todatedata0 = bt.feeds.YahooFinanceCSVData(dataname=args.data0, **dkwargs)cerebro.adddata(data0, name='Data0')cerebro.addstrategy(St,period=args.period,stake=args.stake,printout=args.printout)if args.timereturn:cerebro.addobserver(bt.observers.TimeReturn,timeframe=TIMEFRAMES[args.timeframe])else:benchdata = data0if args.benchdata1:data1 = bt.feeds.YahooFinanceCSVData(dataname=args.data1, **dkwargs)cerebro.adddata(data1, name='Data1')benchdata = data1cerebro.addobserver(bt.observers.Benchmark,data=benchdata,timeframe=TIMEFRAMES[args.timeframe])cerebro.run()if args.plot:pkwargs = dict()if args.plot is not True: # evals to True but is not Truepkwargs = eval('dict(' + args.plot + ')') # args were passedcerebro.plot(**pkwargs)def parse_args(pargs=None):parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,description='Benchmark/TimeReturn Observers Sample')parser.add_argument('--data0', required=False,default='../../datas/yhoo-1996-2015.txt',help='Data0 to be read in')parser.add_argument('--data1', required=False,default='../../datas/orcl-1995-2014.txt',help='Data1 to be read in')parser.add_argument('--benchdata1', required=False, action='store_true',help=('Benchmark against data1'))parser.add_argument('--fromdate', required=False,default='2005-01-01',help='Starting date in YYYY-MM-DD format')parser.add_argument('--todate', required=False,default='2006-12-31',help='Ending date in YYYY-MM-DD format')parser.add_argument('--printout', required=False, action='store_true',help=('Print data lines'))parser.add_argument('--cash', required=False, action='store',type=float, default=50000,help=('Cash to start with'))parser.add_argument('--period', required=False, action='store',type=int, default=30,help=('Period for the crossover moving average'))parser.add_argument('--stake', required=False, action='store',type=int, default=1000,help=('Stake to apply for the buy operations'))parser.add_argument('--timereturn', required=False, action='store_true',default=None,help=('Use TimeReturn observer instead of Benchmark'))parser.add_argument('--timeframe', required=False, action='store',default=None, choices=TIMEFRAMES.keys(),help=('TimeFrame to apply to the Observer'))# Plot optionsparser.add_argument('--plot', '-p', nargs='?', required=False,metavar='kwargs', const=True,help=('Plot the read data applying any kwargs passed\n''\n''For example:\n''\n'' --plot style="candle" (to plot candles)\n'))if pargs:return parser.parse_args(pargs)return parser.parse_args()if __name__ == '__main__':runstrat()
这篇关于Backtrader 文档学习- Observers - Benchmarking的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







