本文主要是介绍pytorch_car_caring 排坑记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pytorch_car_caring 排坑记录
- 任务
- 踩坑回顾
- 简单环境问题
- 代码版本问题
- 症状描述
- 解决方法
- cuda问题(异步问题)
- 症状描述
- 解决方法
任务
因为之前那个MPC代码跑出来的效果不理想,看了一天代码,大概看明白了,但要做改进还要有不少工作(对我来说),特别是如何对效果进行评估。正好我还要用到RL做这个任务的代码,就在github上看了下,发现有几个,打算都跑跑,看谁效果好,代码又干净,就用谁的。本菜鸡目前只会这么硬缝。。。
参考代码这个项目是用PPO算法做的。
踩坑回顾
简单环境问题
照旧起手安装个3.10的conda环境,然后按照readme安装所需包(我直接pip3安装最新版),中间提示少了什么包我再安什么包。
这次我装gym,直接就pip3 install gym[all]了,省事儿。
代码版本问题
症状描述
根据readme指示,运行:
python test.py --render
报错:
gym.error.DeprecatedEnv: Environment version v0 for `CarRacing` is deprecated. Please use `CarRacing-v2` instead.
代码改成v2就行:
self.env = gym.make('CarRacing-v2')
再运行,报错:
AttributeError: 'CarRacing' object has no attribute 'seed'
把随机种子注释掉:
# self.env.seed(args.seed)
报错:
File "/home/lcy-magic/RaceCar_Demo/pytorch_car_caring/test.py", line 70, in rgb2graygray = np.dot(rgb[..., :], [0.299, 0.587, 0.114])
TypeError: tuple indices must be integers or slices, not tuple
他说我的rgb是turple类型的,打印出来看看:
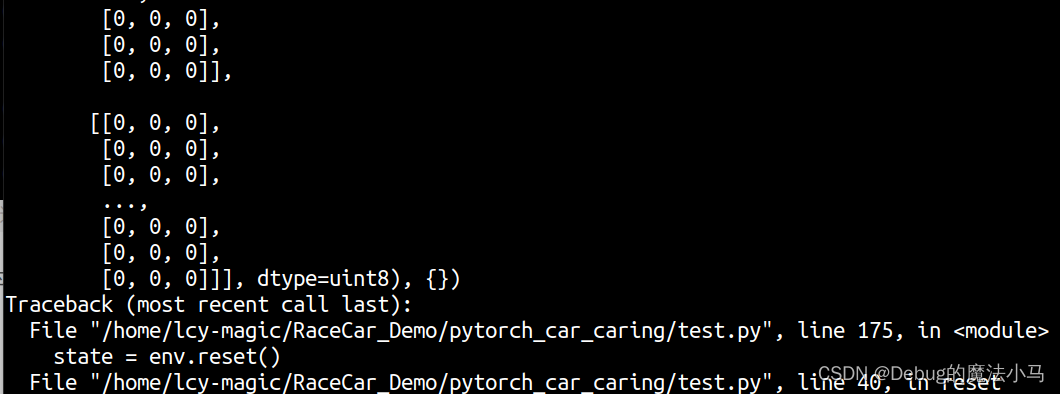
确实不对劲儿,因为还有个{}。刚开始想到怎么回事,就把rgb换成rgb[0],再转成np.array,后面越发不对劲儿,再回过头来看这个问题,才发现症结:
解决方法
rgb来自img_rgb,img_rgb来自step和reset两个函数。关键在于reset函数,这个由于gym改版,返回值不再只是observation还有info。所以,要给代码中所有的step和reset都加上info,问题就解决了。
cuda问题(异步问题)
症状描述
解决上一个问题过程中,其实还出现了cuda问题,报错:
File "/home/lcy-magic/RaceCar_Demo/pytorch_car_caring/test.py", line 127, in forwardv = self.v(x)
File "/home/lcy-magic/anaconda3/envs/CARPPO/lib/python3.10/site-packages/torch/nn/modules/linear.py", line 114, in forwardreturn F.linear(input, self.weight, self.bias)
RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)`
解决方法
当时为了先解决上一个问题,直接把设备改成cpu了,先凑活用:
# device = torch.device("cuda" if use_cuda else "cpu")
device = "cpu"
现在再回过头看看到底什么问题:
- 首先排除代码问题,不可能是维度不对,因为cpu就能跑通,cuda却不行
- 排除显存问题,网络挺小的,数据也不多,应该不是
- 可能是版本问题,但我不愿相信
尝试了网上很多方法,都没有作用。就要放弃了,但博客写一半了,不想烂尾,就继续耗着。然后突然想到,这是强化学习的测试,这个报错出现在网络对价值的估计上,我现在又不需要价值,我只需要动作。我手动给价值赋值个常量看看效果:
# v = self.v(x)v = 1
果然,报错变了,这就带来了新的信息:
File "/home/lcy-magic/RaceCar_Demo/pytorch_car_caring/test.py", line 151, in select_actionaction = action.squeeze().cpu().numpy()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
也就是把数据放到cpu的时候出现了非法内存访问的问题。
我先尝试把cpu去掉,发现不行,后面程序需要这时把数据扔到cpu处理。然后参考网络回答也没用,GPT也没有具体建议。
这时候我想要不试一试报错的建议:For debugging consider passing CUDA_LAUNCH_BLOCKING=1.看看有没有更多报错。
GPT告诉我要这么用:
CUDA_LAUNCH_BLOCKING=1 python your_script.py
于是我就:
CUDA_LAUNCH_BLOCKING=1 python test.py --render
然后宁猜怎么着?我本来只指望着他给我提供点更多的提示信息,结果这次直接就成功了!
然后就很好奇,这个环境变量CUDA_LAUNCH_BLOCKING到底什么意思,这篇博客参考博客讲的比较清楚了。CPU和GPU可能存在异步执行的情况,这时候如果GPU报错,CPU可能不知道当时给GPU下发的什么任务,只能把自己手头上正在做的事儿当做报错信息发出去,所以可能报错是不准确的,这时候用CUDA_LAUNCH_BLOCKING=1,就可以保证CPU和GPU同步执行。
说明,我这里的问题是异步导致的,暂时先不深究到底发生什么了,反正成功了:
恢复价值的前向计算:
v = self.v(x)
执行测试脚本:
CUDA_LAUNCH_BLOCKING=1 python test.py --render
效果:
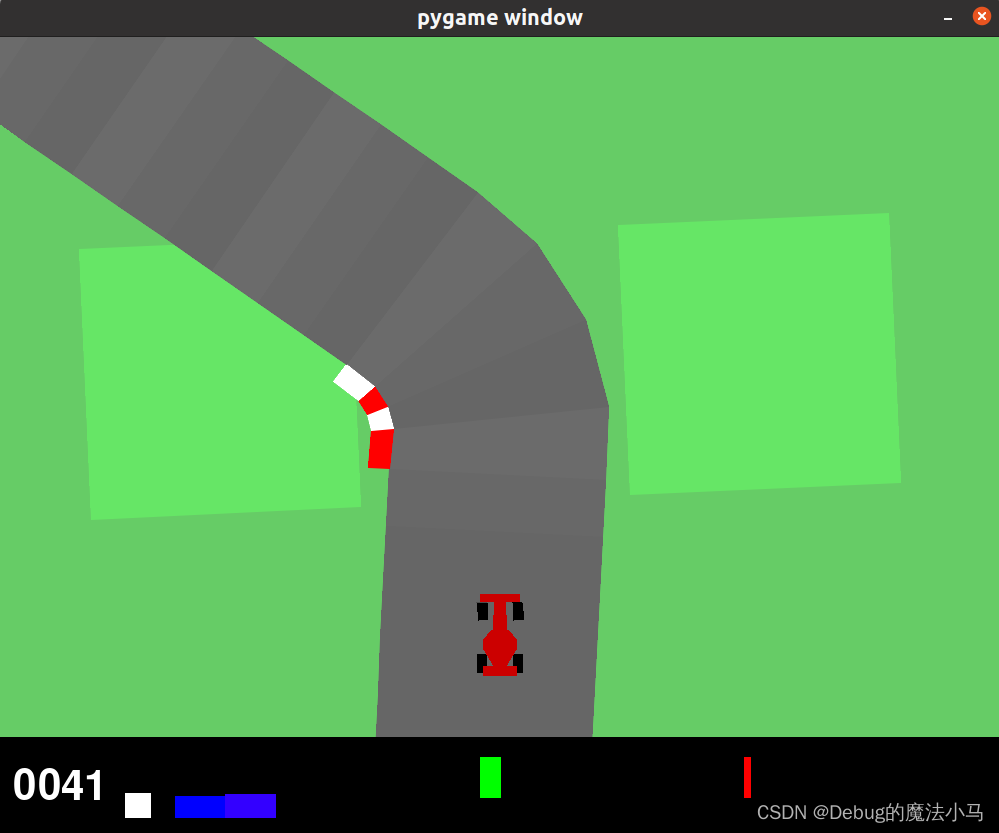
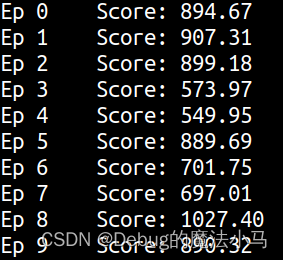
效果也就那样,基本没有正常跑完一圈的。有的分高,是他最后一段冲刺训练出了一种不是最优,但最逆天的走法,不想描述了,散会。
这篇关于pytorch_car_caring 排坑记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




