本文主要是介绍GoogleLeNet(Inception-V1)论文及代码解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
-
GoogleLeNet论文
-
tensorflow代码分析
-
小结
GoogleLeNet论文
GoogleLeNet是2014年ImageNet中ILSVRC14竞赛的冠军,和VGG网络是同一届,VGG网络是当年竞赛的亚军。但是实际上两个网络的TOP-5错误率相差并不多,GoogleLeNet的网络结构相对VGG复杂一些,是一个22层的网络,并且提出了一种Inception的结构,是一个很大的进步。
论文地址 论文的标题是“Going deeper with convolutions”,跟VGG一样也是遵循需要将网络设计的更深的思想。网络名字取名为GoogleLeNet是为了向CNN网络的开山鼻祖LeNet致敬。
1.前言
论文中作者花了大量的篇幅来描述当前分类和检测网络取得的成绩,以及遇到的问题,然后引出作者对现状改进的思路。
众所周知,改进深度神经网络最直接的方式是增加网络的大小,包括增加深度和宽度。增加深度就是增加神经网络的层数,增加宽度就是增加每一层的units个数。但是增加了深度和宽度会带来两个问题:1.因为参数变多而使得网络更加容易overfitting,反而降低了精度。2.会大大增加计算量,而且可能训练出来部分参数最终为0,这样在计算资源有限的情况下浪费了计算资源。所以我们最终的目标是:减少参数,减少计算量,增加深度,增加宽度。
解决方法就是将全连接替换为稀疏连接结构,但是现有的计算方式对非均匀的稀疏计算效率非常低,所以作者提出了自己的改进方式。
2.Inception模型
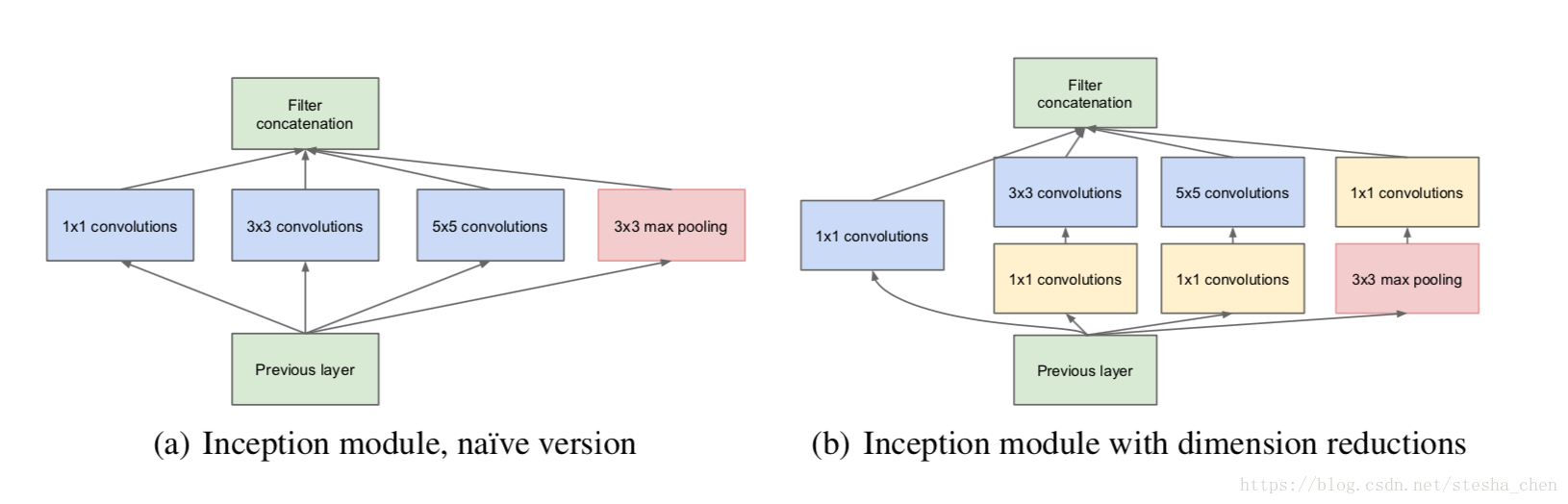
上图是作者提出的两种Inception的模型,b模型是a模型的改进版本。
先说a模型,论文中说是以一种稠密组件去逼近和替代一个最优的局部稀疏结构。我的理解是这种连接模型既会有四种连接方式带来的信息汇总,而且相对直接3x3的Conv进行连接的方式参数反而有所减少。为何参数会有减少呢?举个下图的例子(只是举个例子,并不是真实使用情况):

接着作者又发现,虽然参数量是有减少,但是减少的并不是太多,而且如果输入的数据channel值比较大,参数量仍然会比较大,所以作者提出了b模型。b模型相对a模型而言,在使用3x3或者5x5的Conv连接之前用了1x1的Conv进行降维,这样会使参数量再一次减少,并且在1x1Conv后也使用非线性激活就增加了网络的非线性。参数量变化如下图(只是举个例子,并不是真实使用情况):
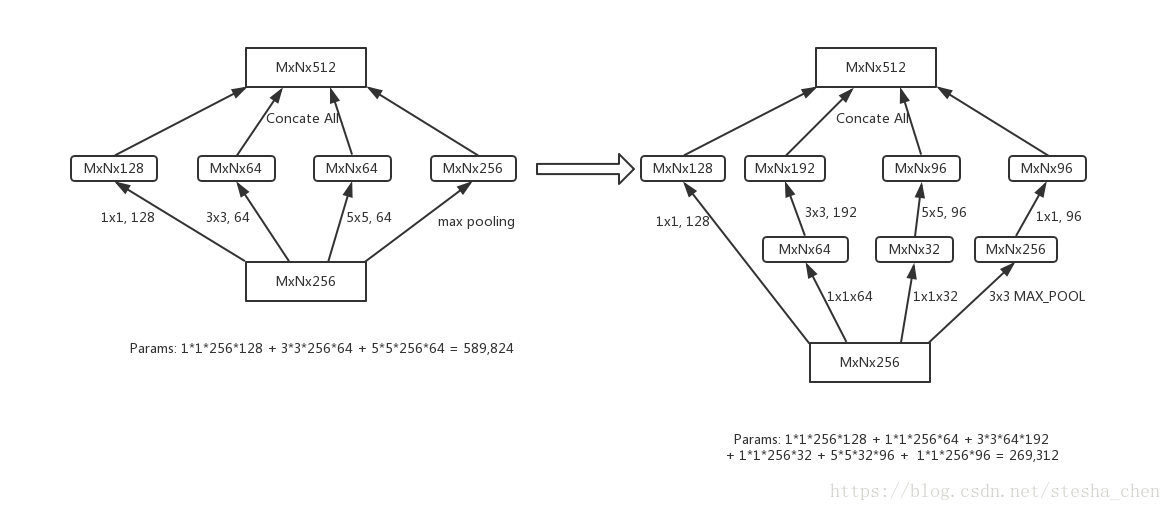
总之,Inception模型的好处是既能增加网络的深度和宽度,又不会增加计算量,而且稀疏连接的方式还能有助于减少过拟合。
3.网络结构
论文中的网络结构如下图:
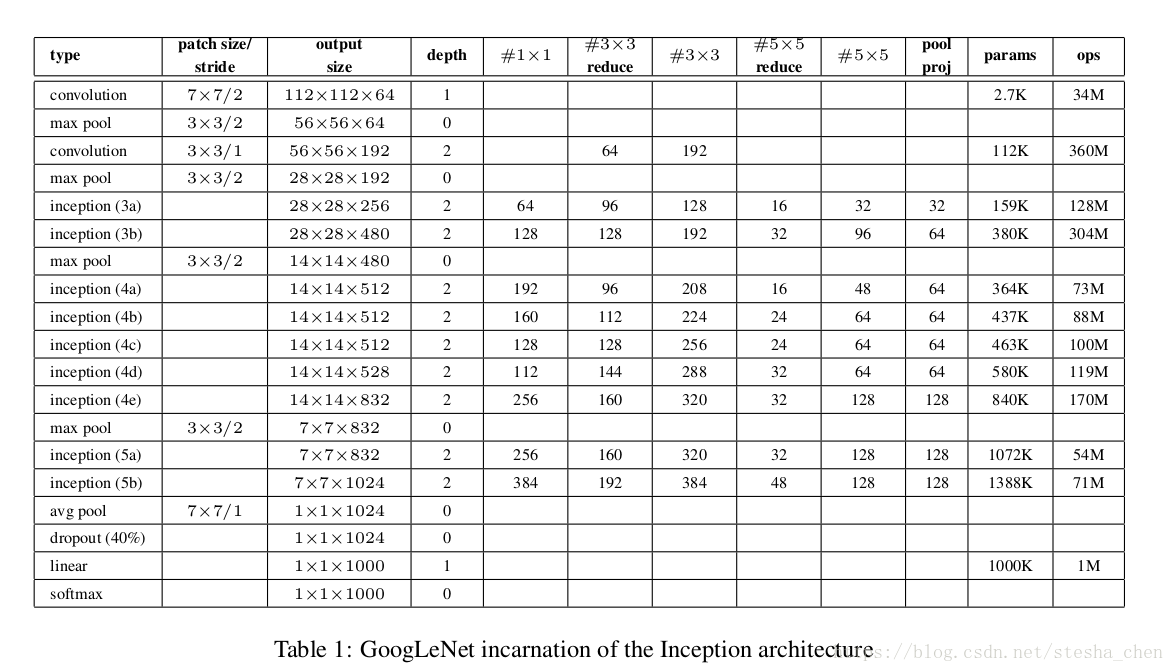
- Input为224x224x3的RGB图片,同样减去每个颜色通道的均值(同vgg网络一样)
- #3x3 reduce表示在3x3Conv之前1x1Conv连接的channel数量,同样#5x5 reduce表示在5x5Conv之前1x1Conv链接的channel数量.
- pool proj表示inception中max pooling后的1x1Conv连接的channel数量
- 只计算有参数的层数是22层,所有的卷基层都用Relu激活,包括inception内部的卷积
- 作者发现去掉最后的FC,改为avg pool,精确度有提升,但是还要保留后面的dropout
另外作者担心这么深的网络越往后信息的传播能力会受损,但是作者发现中间层的网络还带有比较多的信息,因此在inception(4a)和inception(4d)后面增加了一个比较小的网络,做了softmax输出,和最后的softmax输出相加,但是权重设置为0.3.也就是最后的output是softmax2+0.3*softmax1+0.3*softmax0

inception(4a)处的softmax
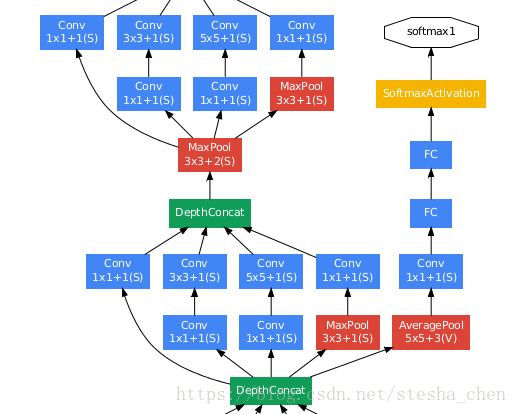
inception(4d)处的softmax
这篇关于GoogleLeNet(Inception-V1)论文及代码解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





