本文主要是介绍Observability:使用 Elastic Stack 分析地理空间数据 (一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着人类在不断地探索空间,地理空间数据越来越多。 收集信息的速度以及提供位置信息的来源正在迅速增长。政府和商业卫星继续扩张。与GPS一起,它们提供了一系列不同的空间丰富的数据源,包括天气和温度模式,土地使用,土壤化学,减灾和响应,电信等。


移动设备和底层网络将人员,汽车,卡车和大量踏板车变成了位置信息的来源。计算机网络将位置信息嵌入IP地址元数据中,这可以帮助IT管理员在分布式基础架构中为用户提供支持,或者帮助执法部门以及我们的网络运营商找到并阻止坏人。所有这些数据都是令人兴奋的,它激发了每个人内部的创造力来利用它。提出新的问题,构思新的想法,并建立新的期望。这些新事物不容易解决。他们需要以不同格式存储的数据或跨非空间维度(如主题标签或网络域)的相关性存储的数据。尽管专家长期以来拥有执行复杂的地理空间分析的工具,但这些工具并不总是能够完成非传统来源的混合或处理当今数据集规模的任务。现在事情变得更加复杂。Elastic Stack 是一个高效的存储,分析及搜索软件栈。Elastic Stack 正在积极地推动这一进程。为我们提供更多的数据,更多的用途和更多的利益。
在今天的教程中,我将介绍如何使用 Elastic Stack 来收集这些地理空间位置信息,并对它们进行可视化化分析。
我将使用 opensky network API 来获取飞机的飞行信息,并使用 Kibana 来对数据进行展示。
这个演示分为两个部分:
- Observability:使用 Elastic Stack 分析地理空间数据 (一)
- Observability:使用 Elastic Stack 分析地理空间数据 (二)
安装
Elasticsearch
我们可参考我之前的文章 “如何在Linux,MacOS及Windows上进行安装Elasticsearch” 来安装我们的Elasticsearch。
Kibana
我们可以参考我之前的文章 “如何在Linux,MacOS及Windows上安装Elastic栈中的Kibana” 来进行我们的安装。
Logstash
我们可以参考我之前的文章 “如何安装Elastic栈中的Logstash” 来安装 Logstash。我们先不要运行 Logstash。
我们可以启动 Elasticsearch 及 Kibana。在我们的电脑的浏览器中输入地址 http://localhost:5601/:
如果能看到上面的界面,则表明我们的 Elasticsearch 及 Kibana 的安装是正确的。
Logstash 配置文件
在这个展示中,我们将使用 Logstash 定期地去 opensky network 网站上去抓取数据,并导入到 Elasticsearch 中。Logstash 的配置文件如下:
fligths_logstash.conf
input {http_poller {codec => "json"schedule => { every => "15s" }urls => {url => "https://opensky-network.org/api/states/all"}}
}filter {split {field => "states"add_field => {"icao" => "%{[states][0]}""callsign" => "%{[states][1]}""origin_country" => "%{[states][2]}""time_position" => "%{[states][3]}""last_contact" => "%{[states][4]}""location" => "%{[states][6]},%{[states][5]}""baro_altitude" => "%{[states][7]}""on_ground" => "%{[states][8]}""velocity" => "%{[states][9]}""true_track" => "%{[states][10]}""vertical_rate" => "%{[states][11]}""geo_altitude" => "%{[states][13]}""squawk" => "%{[states][14]}""spi" => "%{[states][15]}""position_source" => "%{[states][16]}"}}mutate {strip => ["callsign"]rename => { "time" => "request_time" }remove_field => ["states", "@version"]}translate {field => "[position_source]"destination => "position_source"override => "true"dictionary => {"0" => "ADS-B""1" => "ASTERIX""2" => "MLAB"}}if [time_position] =~ /^%{*/ {drop { }}if [callsign] =~ /^%{*/ {mutate { remove_field => ["callsign"] }}if [location] =~ /^%{*/ {mutate { remove_field => ["location"] }}if [baro_altitude] =~ /^%{*/ {mutate { remove_field => ["baro_altitude"] }}if [velocity] =~ /^%{*/ {mutate { remove_field => ["velocity"] }}if [true_track] =~ /^%{*/ {mutate { remove_field => ["true_track"] }}if [vertical_rate] =~ /^%{*/ {mutate { remove_field => ["vertical_rate"] }}if [sensors] =~ /^%{*/ {mutate { remove_field => ["sensors"] }}if [geo_altitude] =~ /^%{*/ {mutate { remove_field => ["geo_altitude"] }}if [squawk] =~ /^%{*/ {mutate { remove_field => ["squawk"] }}mutate {convert => { "baro_altitude" => "float" "geo_altitude" => "float""last_contact" => "integer""on_ground" => "boolean""request_time" => "integer""spi" => "boolean""squawk" => "integer""time_position" => "integer""true_track" => "float""velocity" => "float""vertical_rate" => "float"}}
}output {stdout { codec => rubydebug}elasticsearch {manage_template => "false"index => "flights"# pipeline => "flights_aircraft_enrichment"hosts => "localhost:9200"}
}从上面的 input 部分我们可以看出来:
input {http_poller {codec => "json"schedule => { every => "15s" }urls => {url => "https://opensky-network.org/api/states/all"}}
}这里,我们使用 http_poller 每隔15秒去抓一次数据。如果大家想知道这个 API https://opensky-network.org/api/states/all 的内容是什么,你可以直接在浏览器的地址栏中输入这个地址,你及可以看出来是什么样的格式的信息。你可以使用工具 http://jsonviewer.stack.hu/ 对这个 JSON 格式的返回信息进行格式化,以便更好地分析它里面的数据。这对在 filter 部分的各个过滤器的使用的理解是非常有帮助的。在 filter 的最后部分,我也对数据的类型进行了转换以便更好地在 Kibana 中进行分析。
为了能够使得我们的 flights 的数据类型和我们转换的数据类型进行很好的匹配,我们必须在 Kibana 中对这个索引定义好它的 mapping:
PUT flights
{"mappings": {"properties": {"@timestamp": {"type": "date"},"baro_altitude": {"type": "float"},"callsign": {"type": "keyword"},"geo_altitude": {"type": "float"},"icao": {"type": "keyword"},"last_contact": {"type": "long"},"location": {"type": "geo_point"},"on_ground": {"type": "boolean"},"origin_country": {"type": "keyword"},"position_source": {"type": "keyword"},"request_time": {"type": "long"},"spi": {"type": "boolean"},"squawk": {"type": "long"},"time_position": {"type": "long"},"true_track": {"type": "float"},"velocity": {"type": "float"},"vertical_rate": {"type": "float"}}}
}在 Kibana 的 Dev Tools 中运行上面的指令,这样我们就创建好了 flights 索引的 mapping。
接下来,我就可以启动 Logstash 了。在我的 Mac OS 电脑上,在 Logstash 的安装根目录中,打入如下的命令:
sudo ./bin/logstash -f fligths_logstash.conf 这时,我们可以在 console 中看到如下的输出:
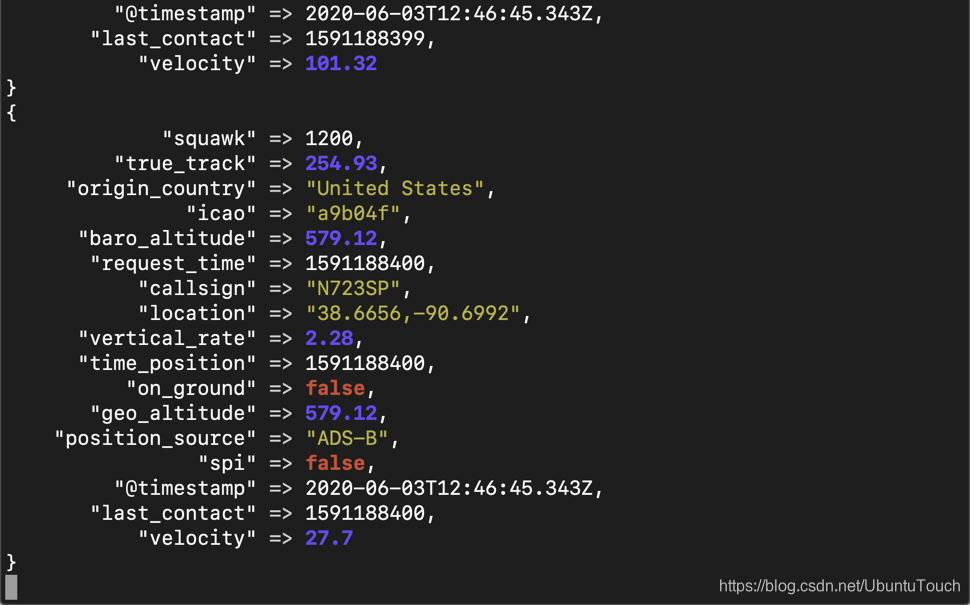
它表明我们的 Logstash 正在工作。
我们接下来在 Kibana 中打入如下命令:
GET _cat/indices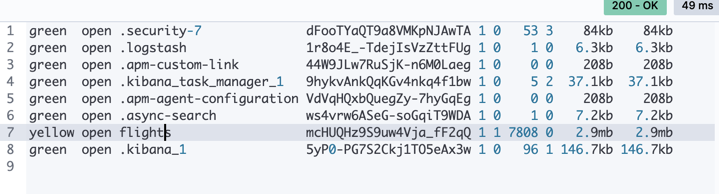
我们可以看到文件大小不断增长的 flights 索引。它表明我们的数据正被导入到 Elasticsearch 中。
为了分析数据,我们必须创建一个 index pattern:
点击 Create index pattern:
点击 Next step:
点击上面的 Create index pattern。这样就完成了创建 Index pattern。
运用 Kibana 可视化
显示目前所有的正在飞行的飞机
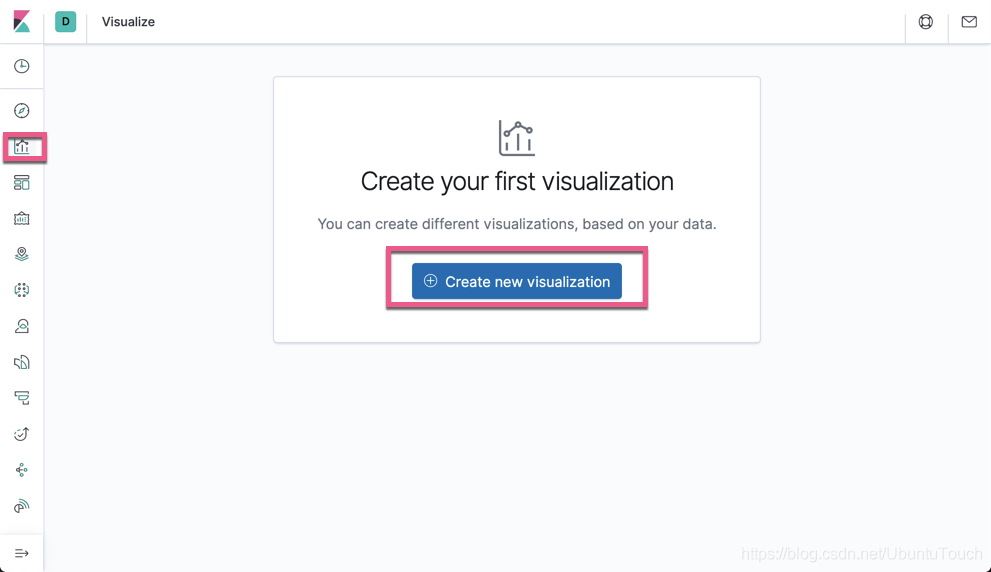
我们接下来显示所有目前正在的飞行的飞机。打开 Kibana,并创建 Visualization:
点击上面的 Create new visualization:

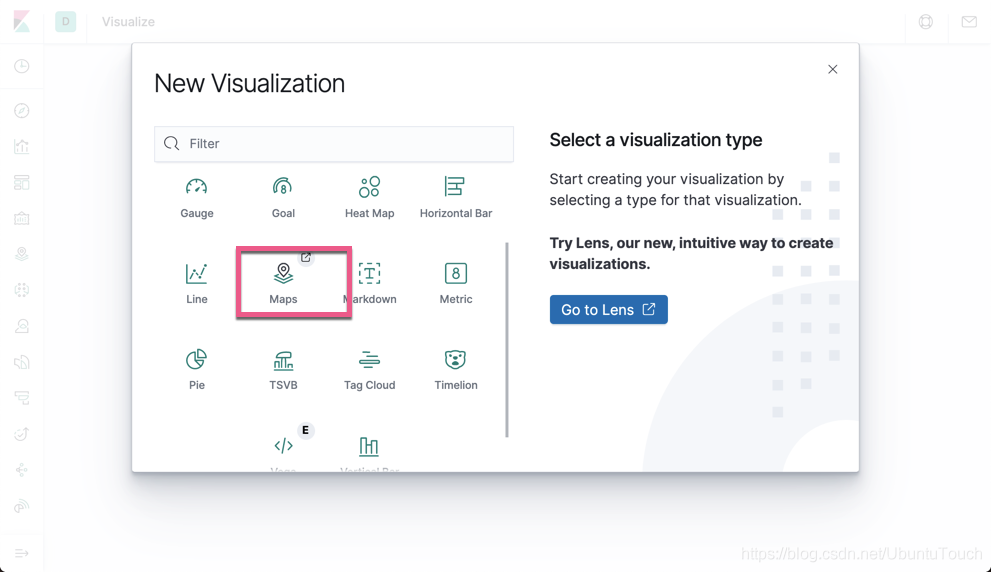
选择 Maps:
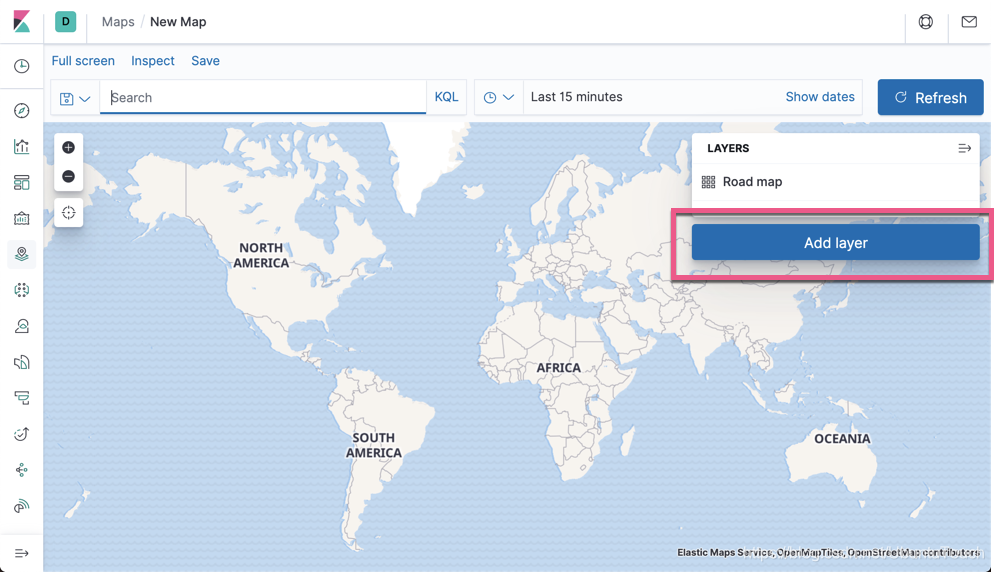
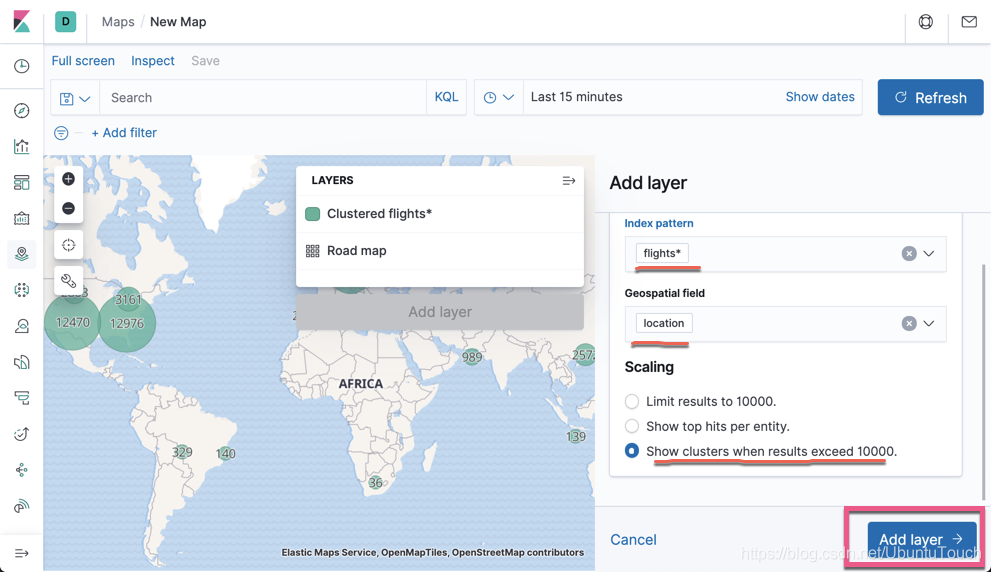
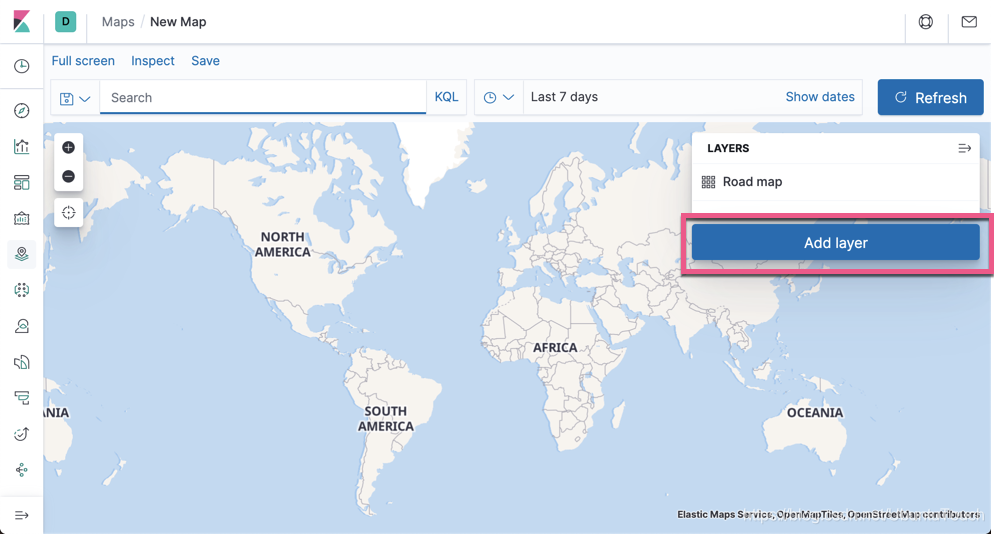
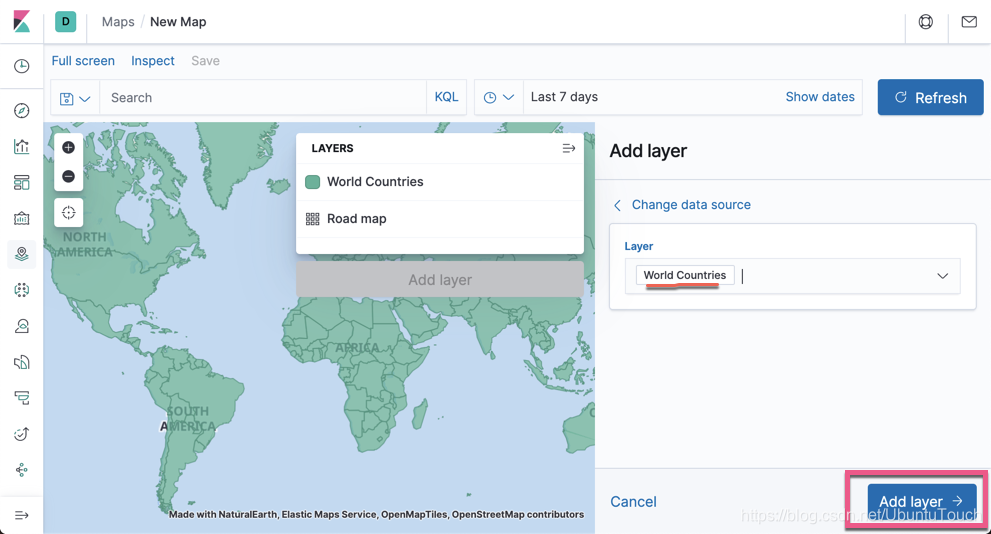
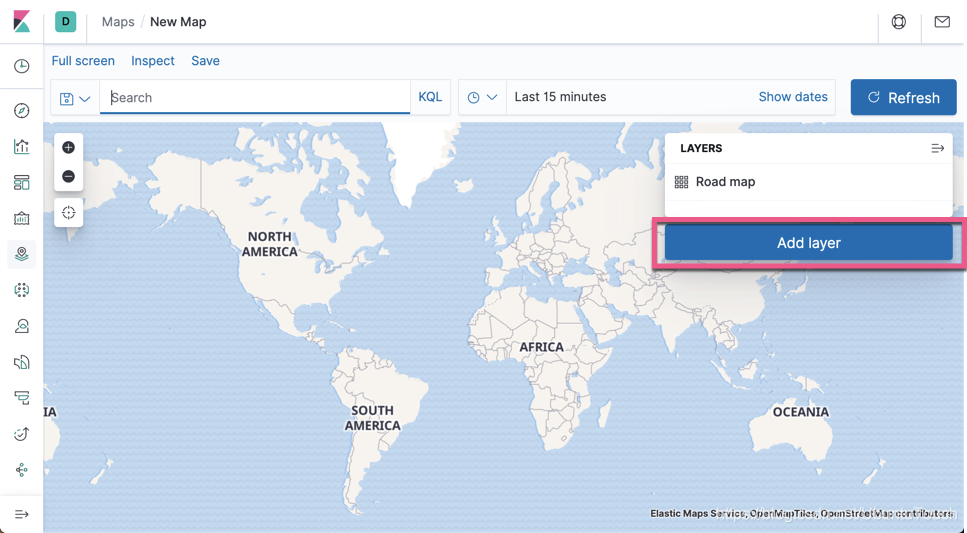
点击 Add layer:
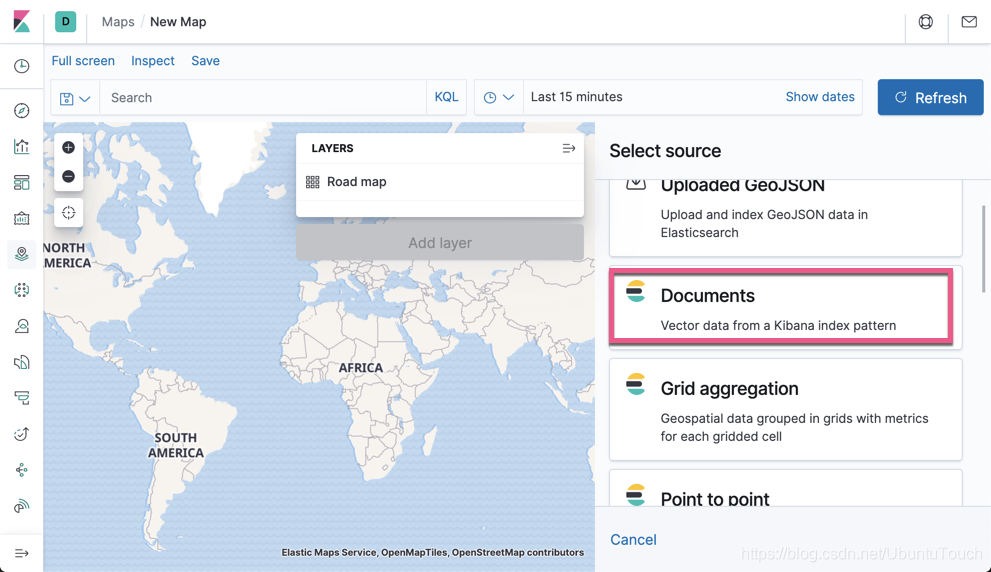
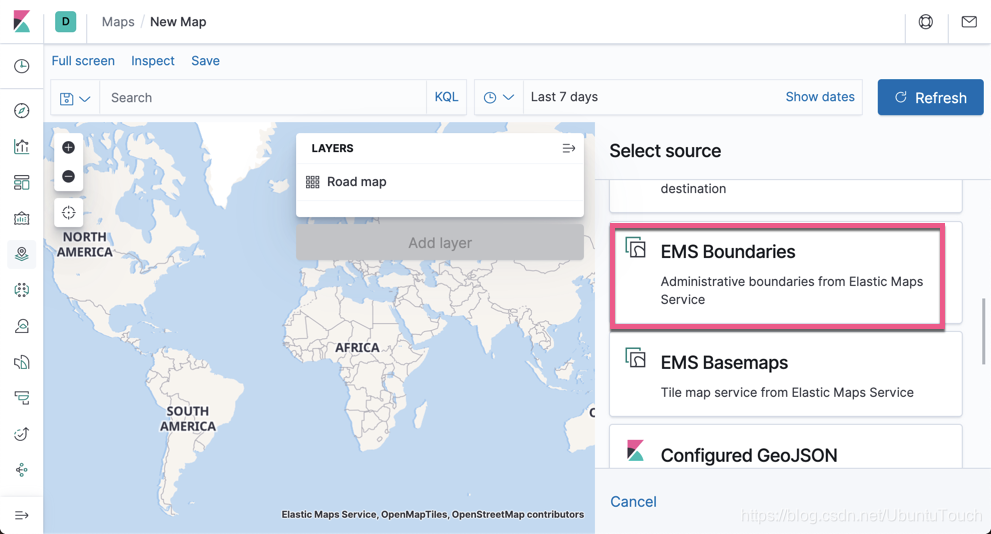
选择 Documents:

点击上面的 Add layer:
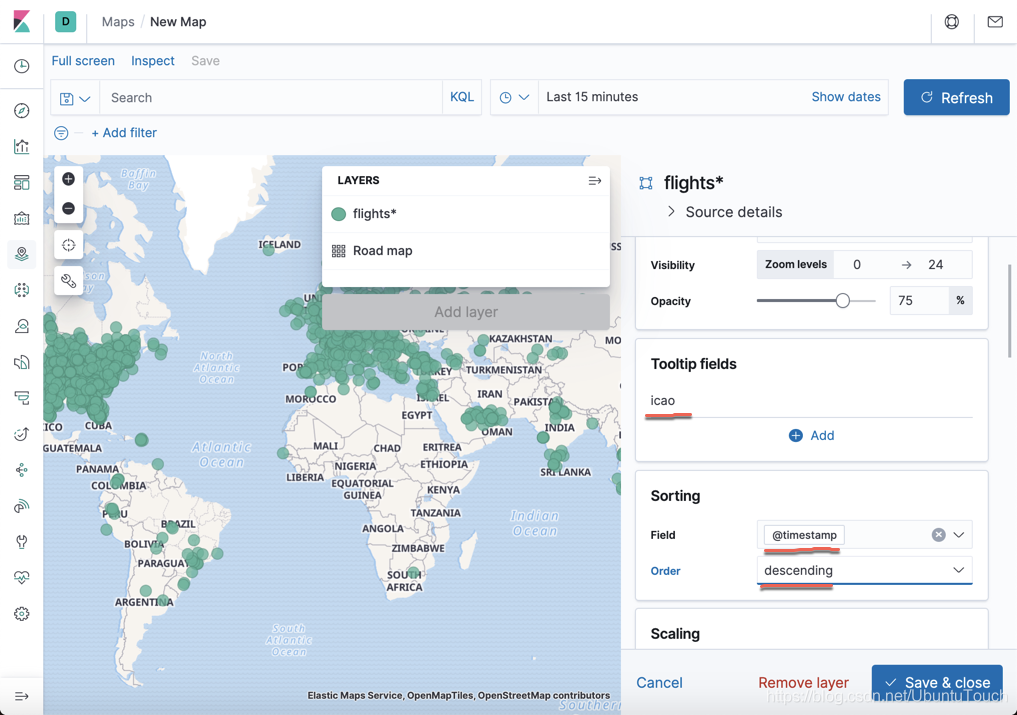
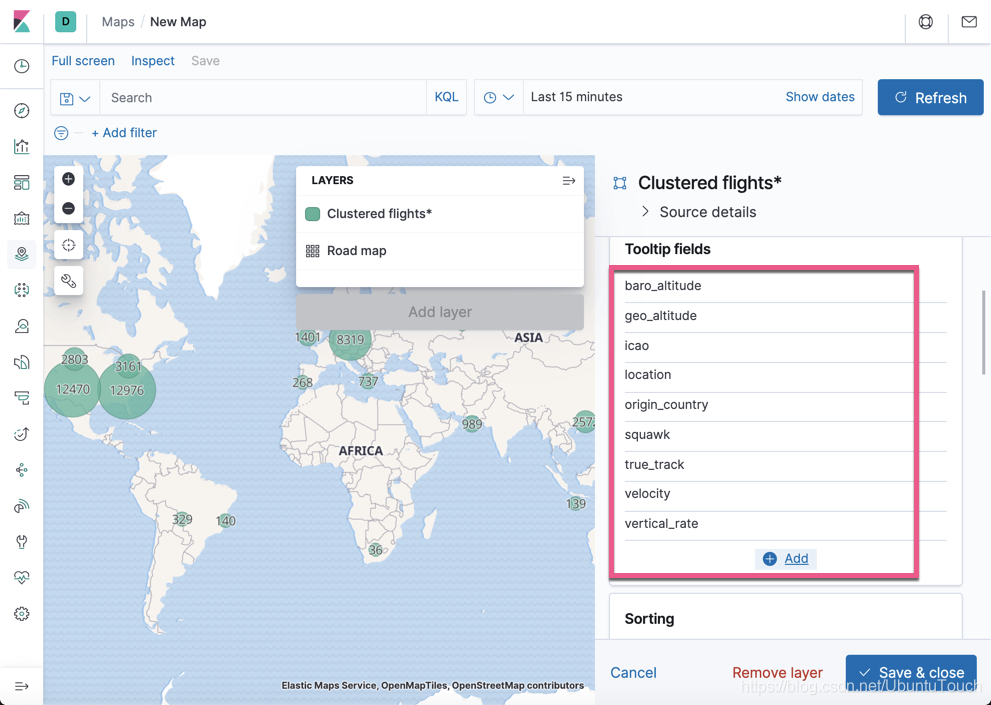
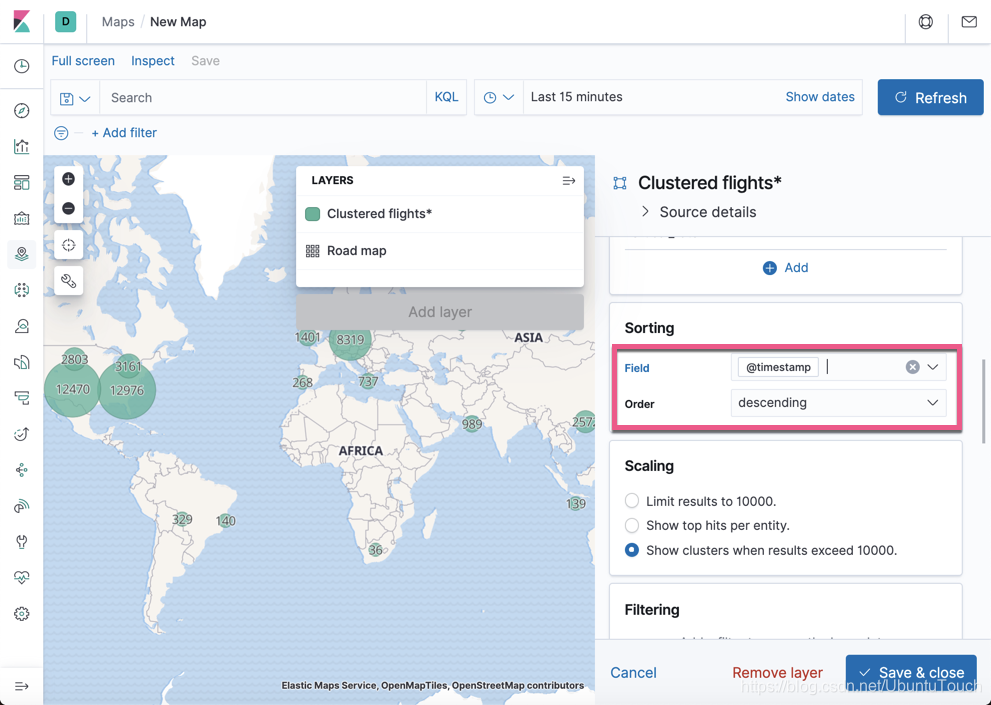
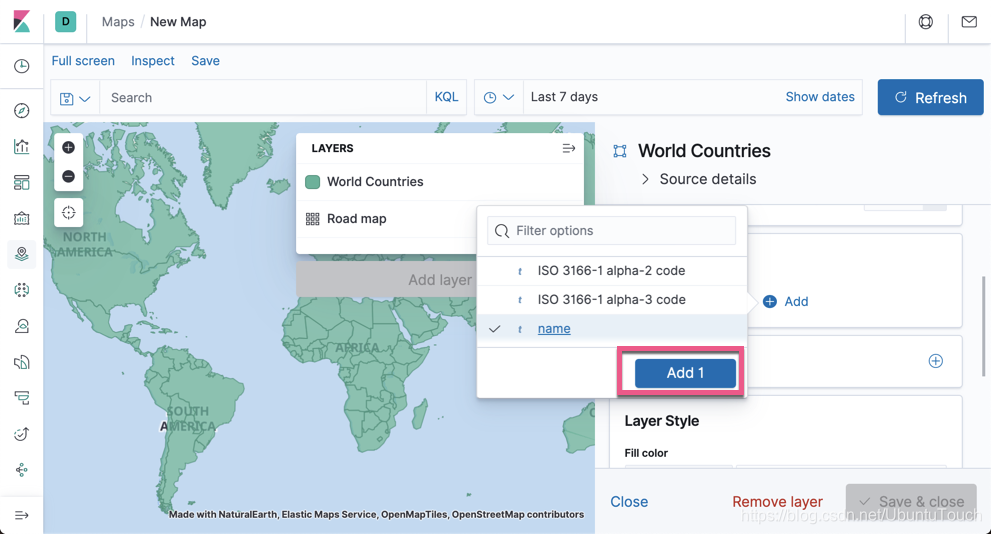
向下滚动:
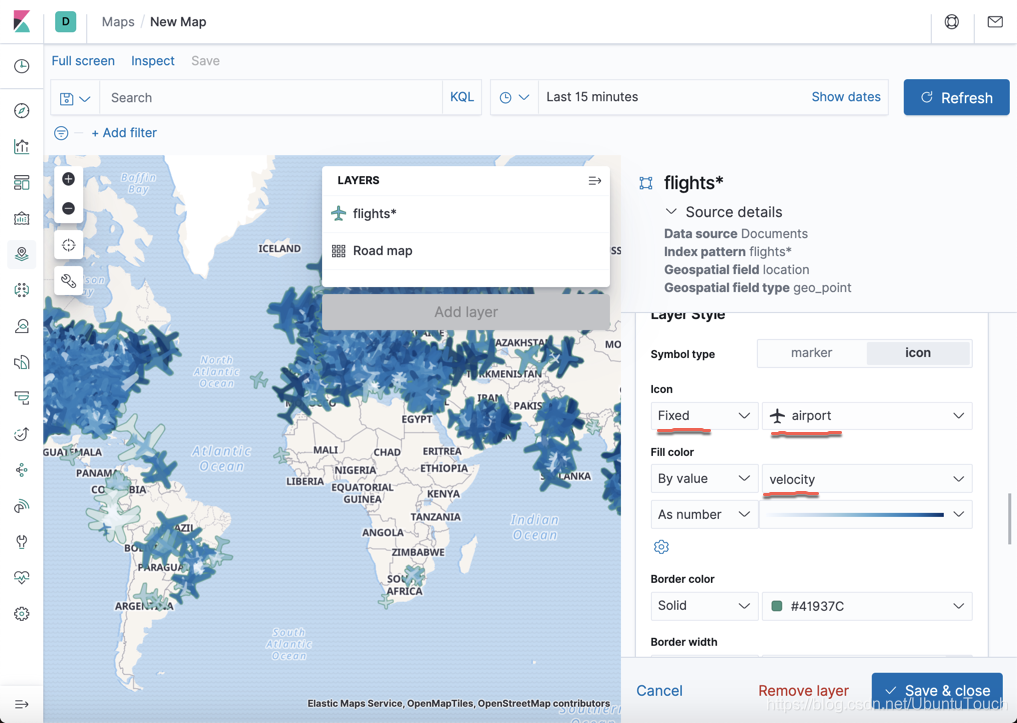
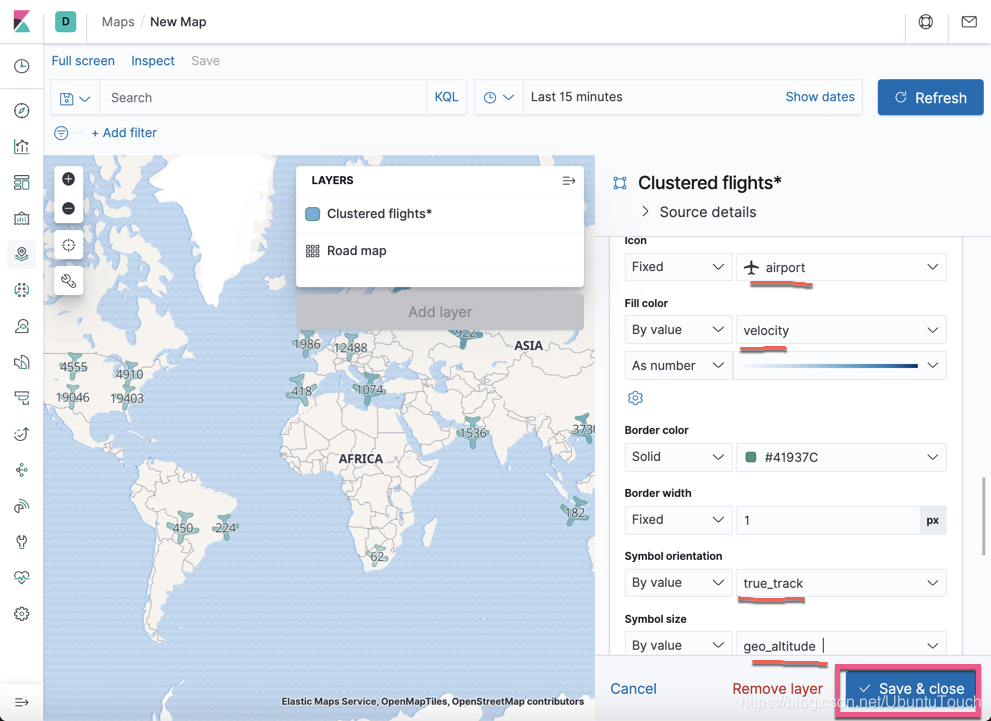
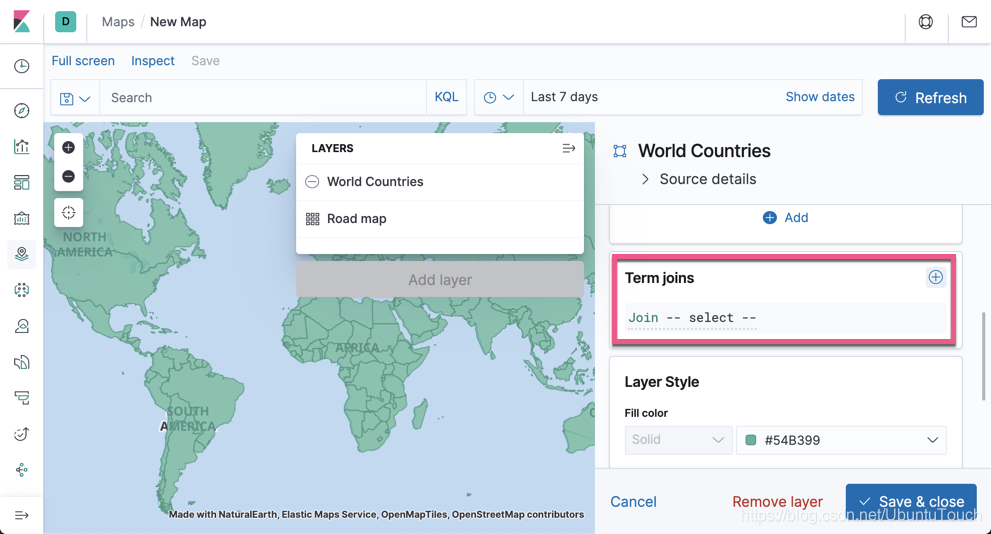
我们选择飞机机场图标为固定的图标。选择速度为它的颜色,速度越快,颜色越深。
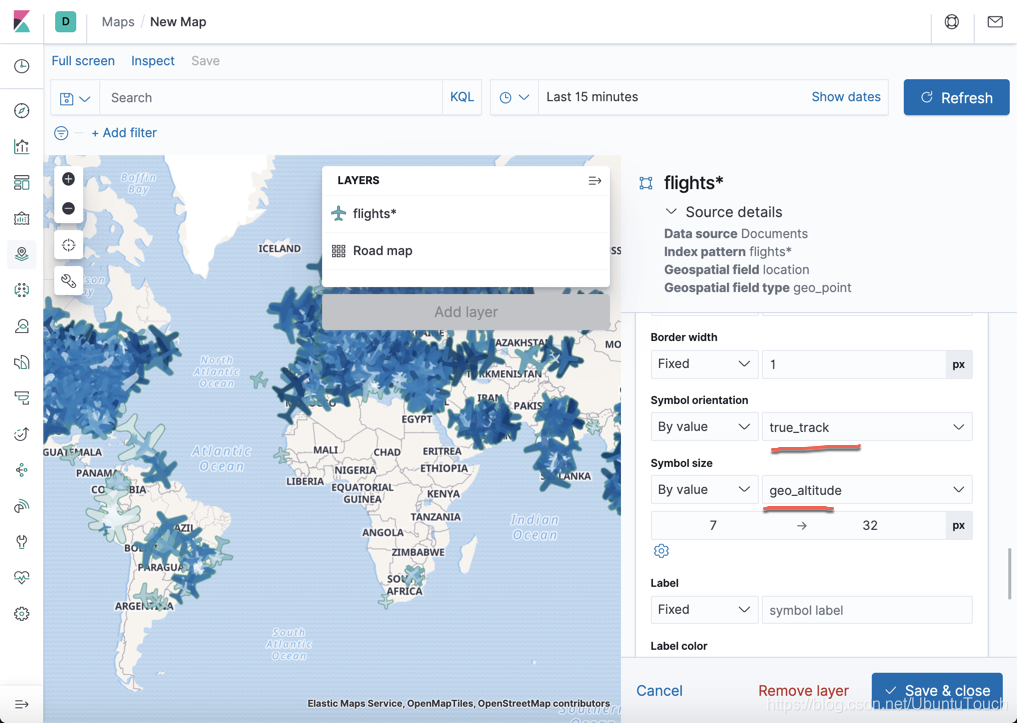
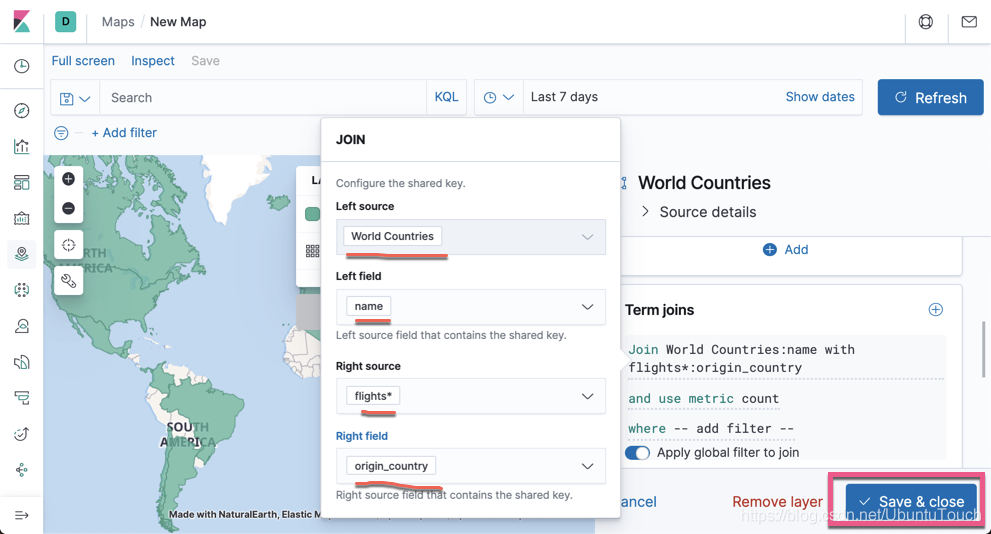
同时,我们绑定图标的方向为 true_track,这是飞机的飞行方向。同时飞机的高度越高,图标就越大。点击 Save & close 按钮:
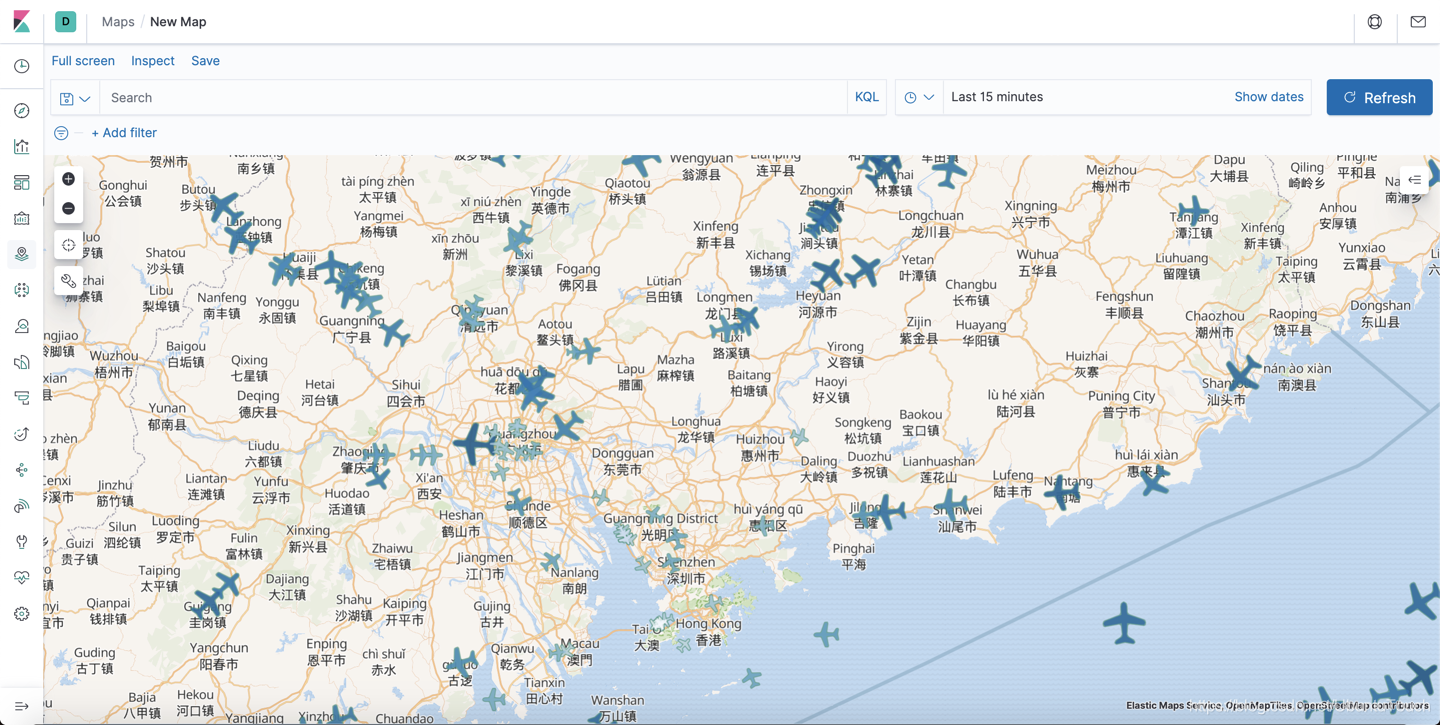
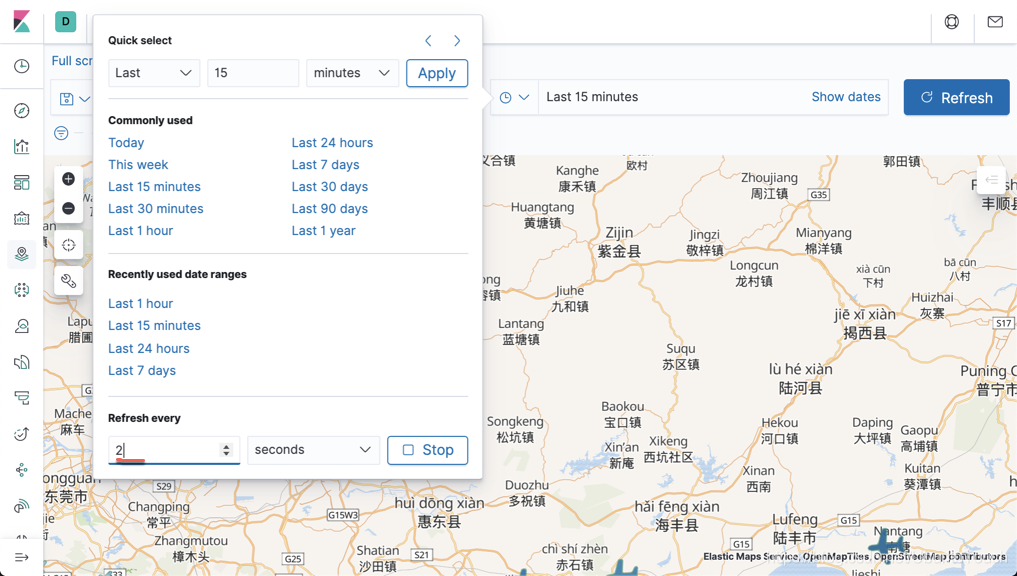
同时设定每个两秒正抓取数据一次,这样我们就可以看到每个飞机的状态了。点击上面的 Apply:
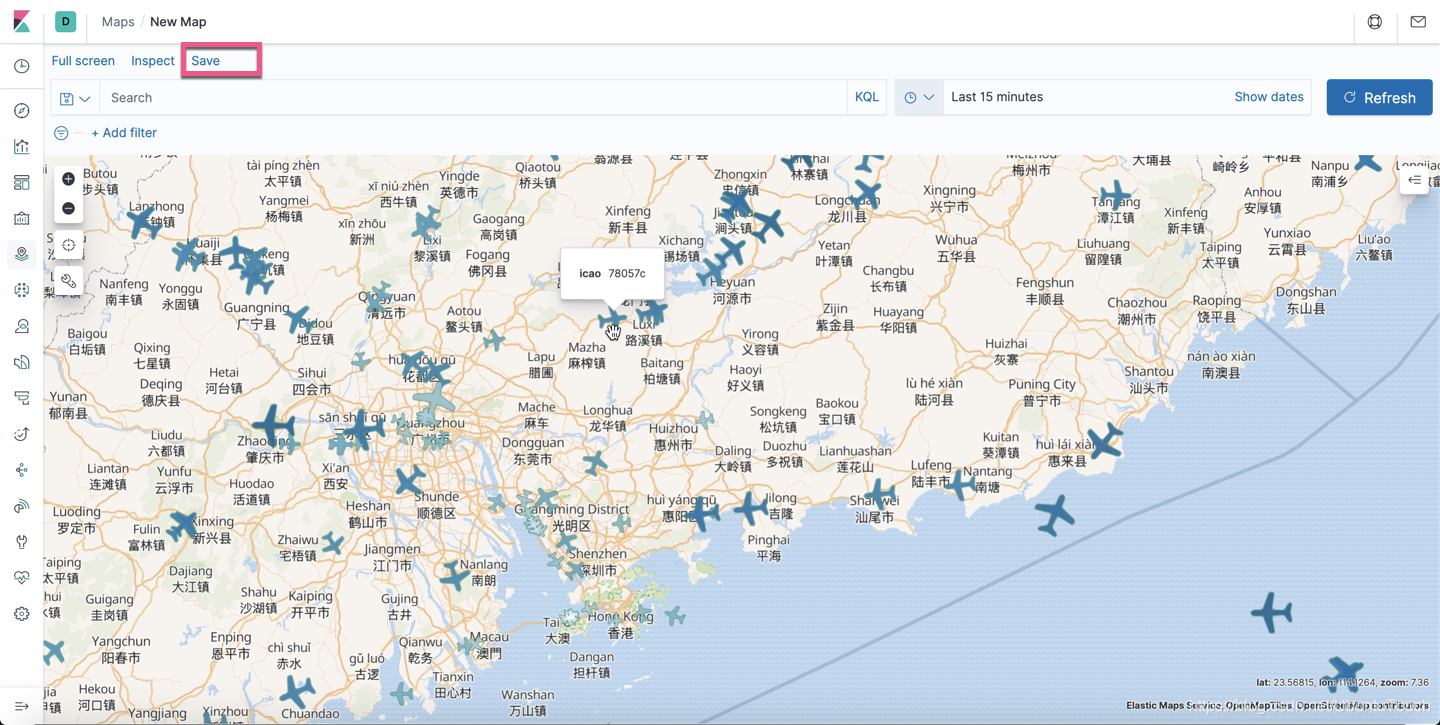
点击上面的 Save 按钮,并取名为 v1。这样我们就创建了第一个 Visualization。
显示飞机过去7天的数据
和上面的显示一样,只不过这次,我们显示过去7天的数据,而不是最新的一个数据。
点击上面的 Save & close:
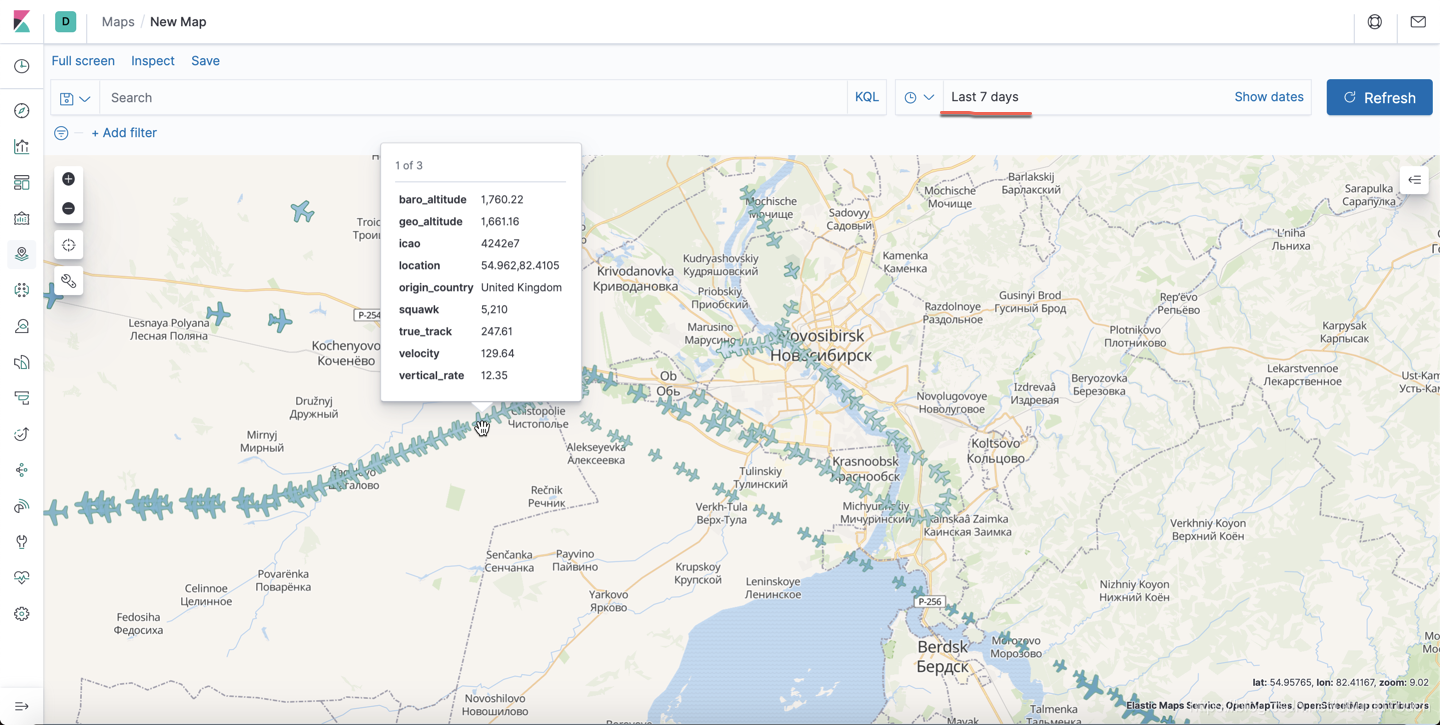
从上面,我们可以看到每架飞机的轨迹。
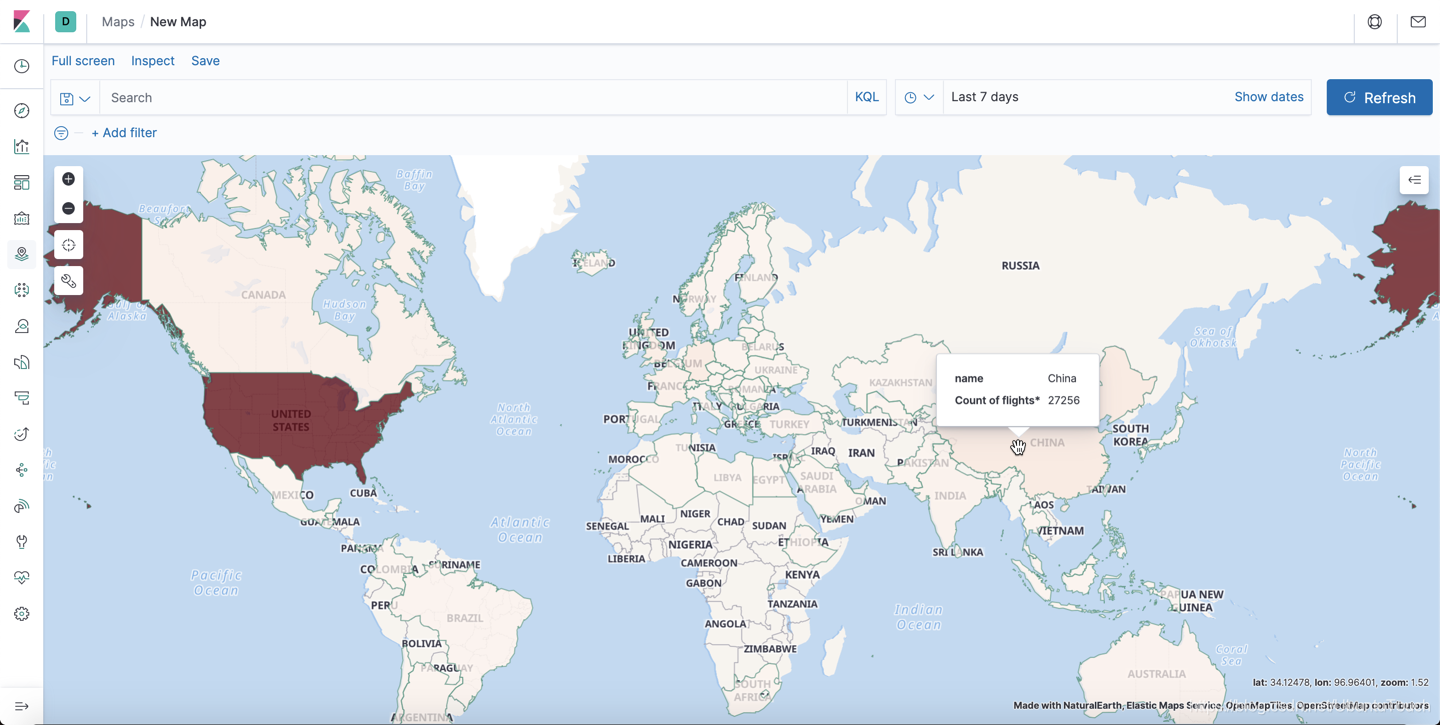
查看哪个国家的飞机航班多
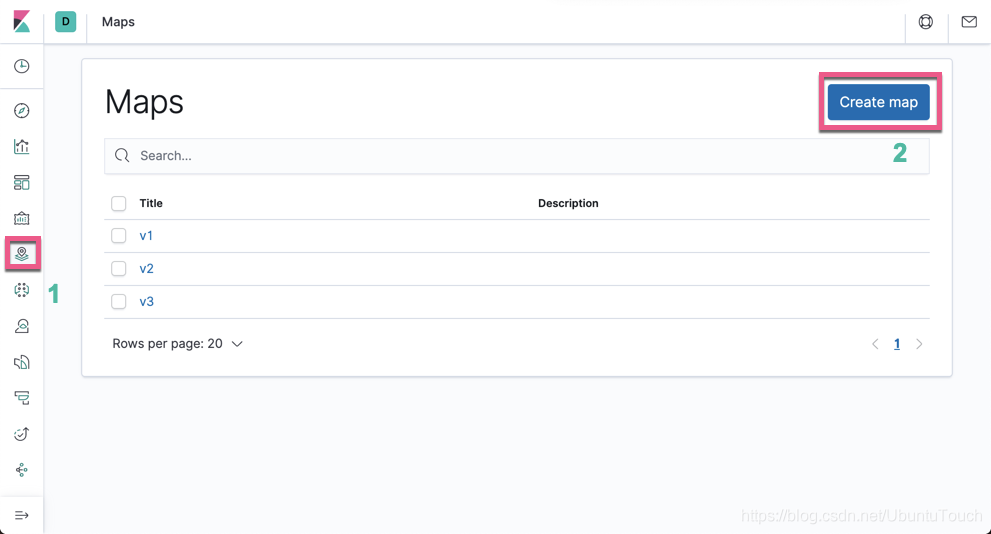
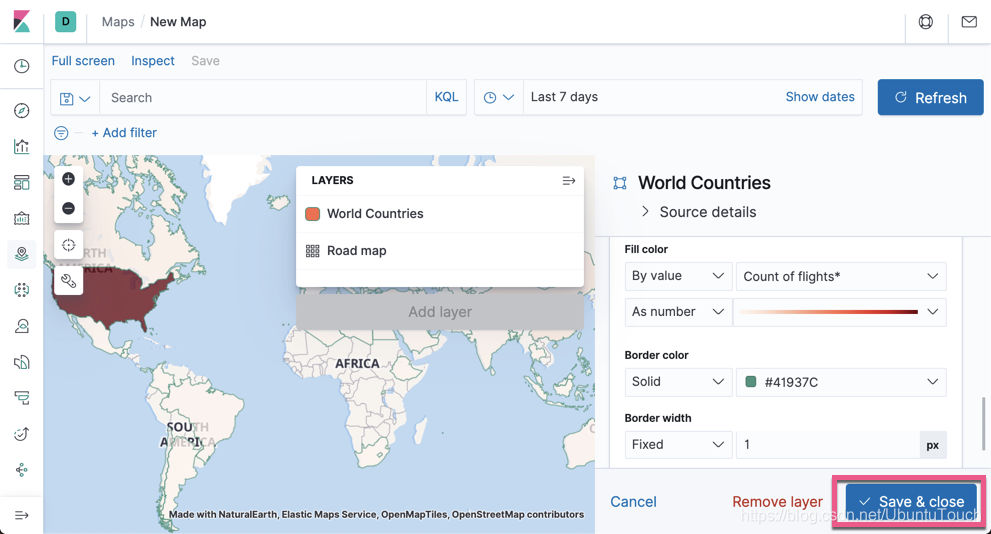
找出各个地区的机场数目
点击 Create map:

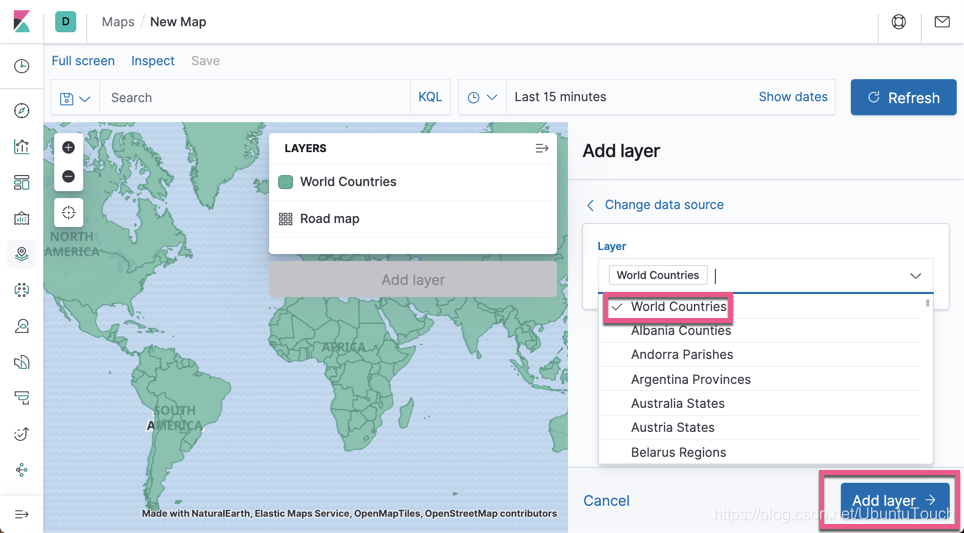
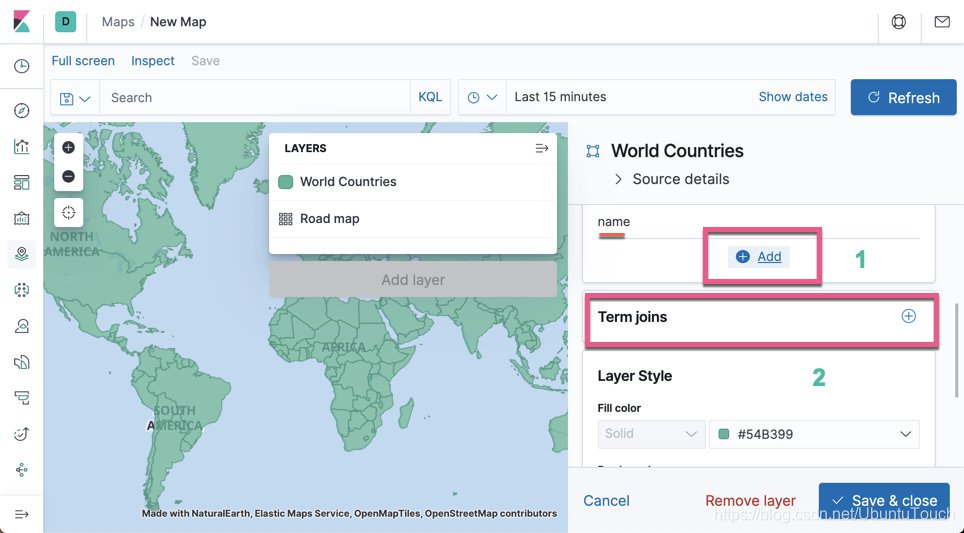
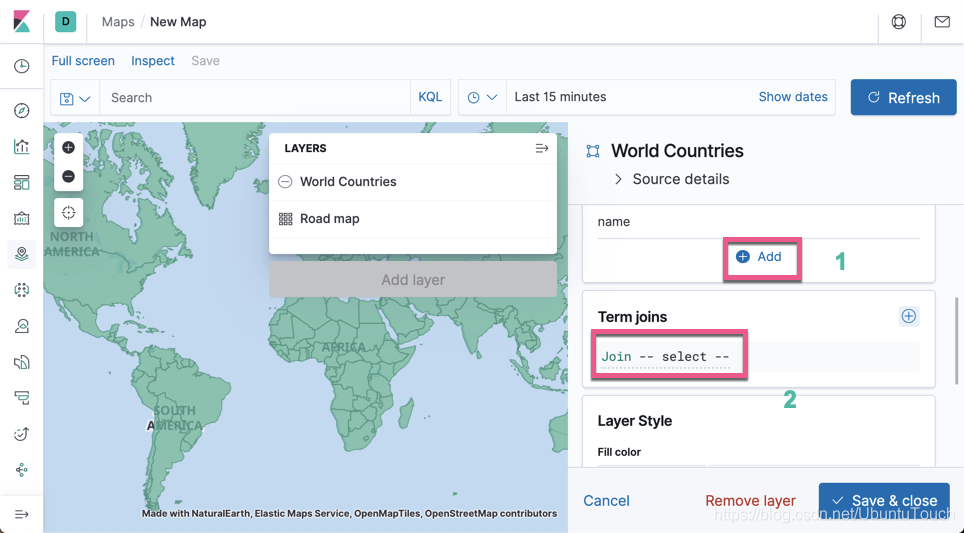
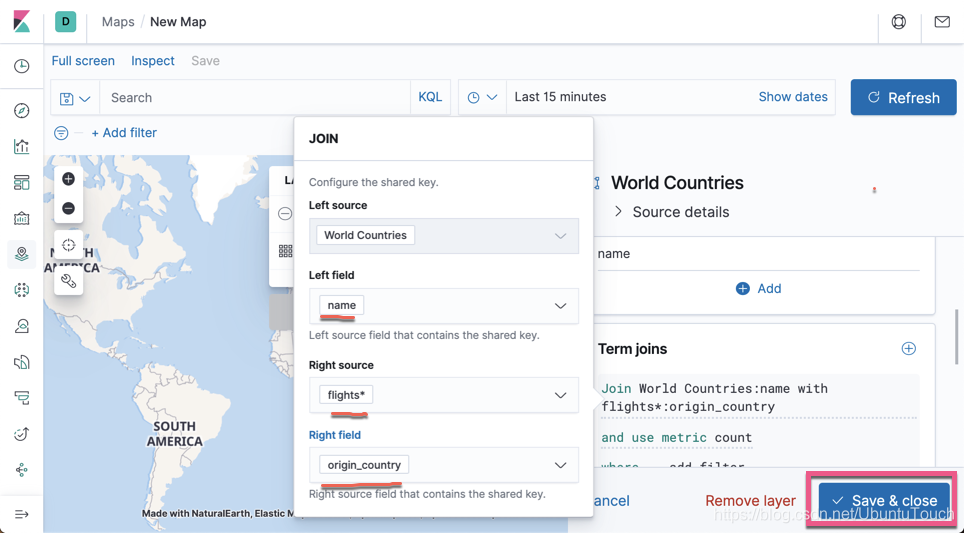
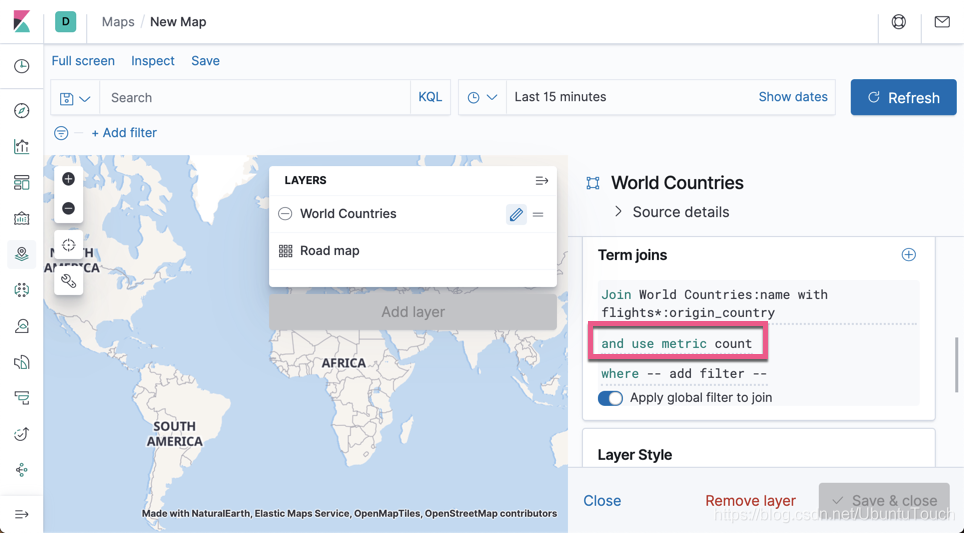
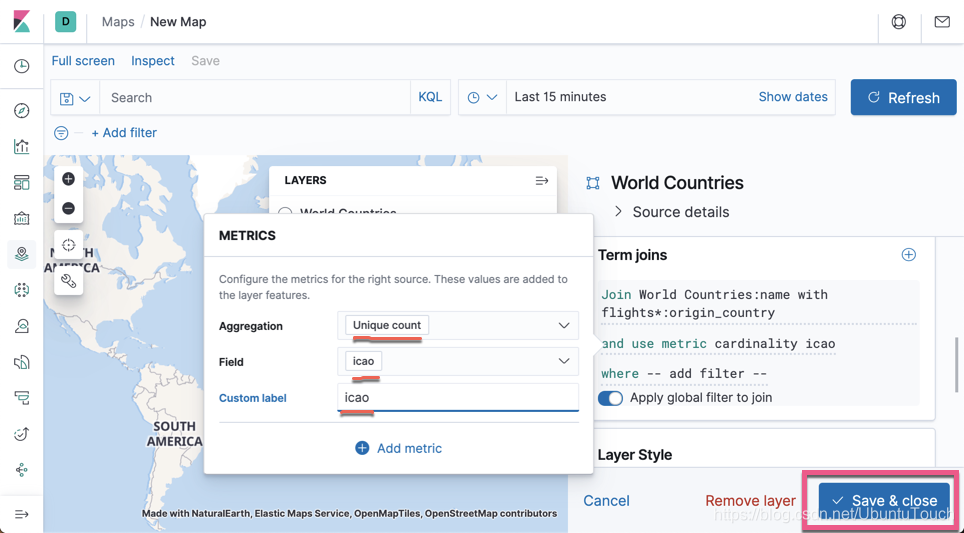
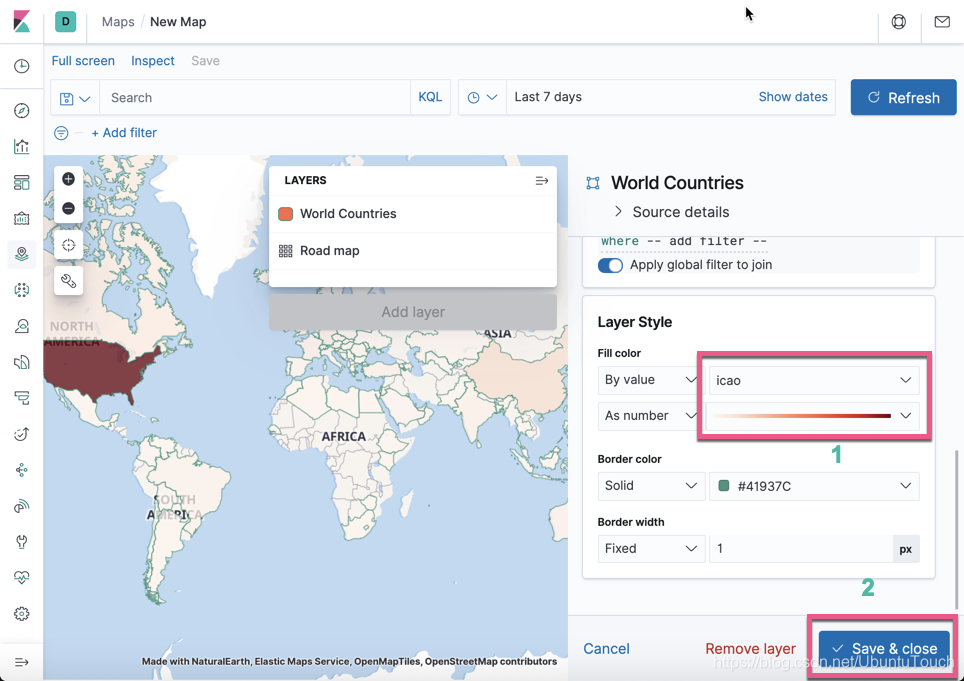
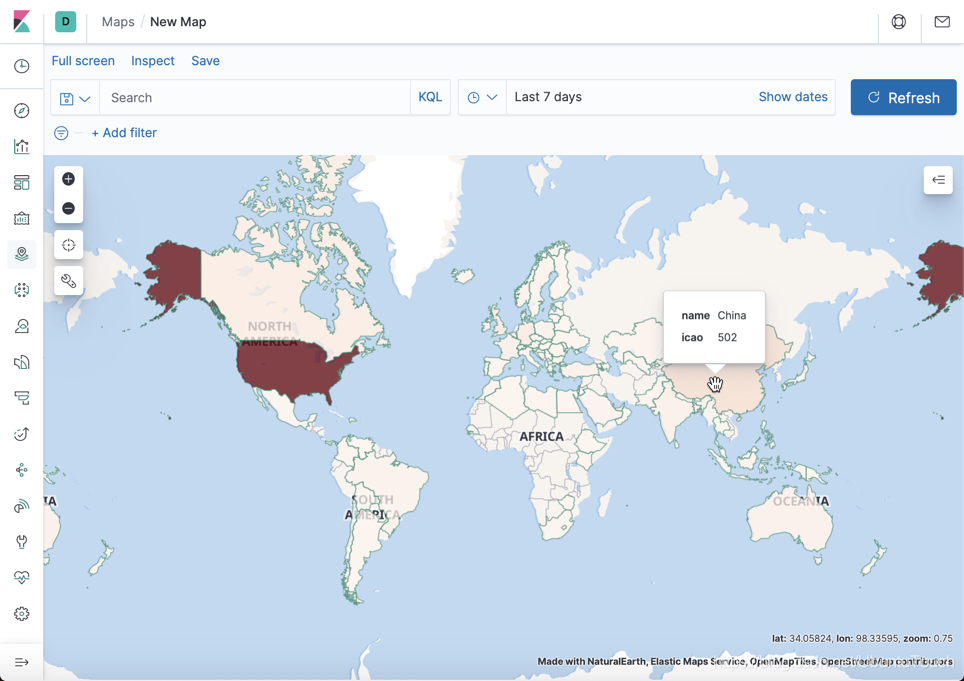
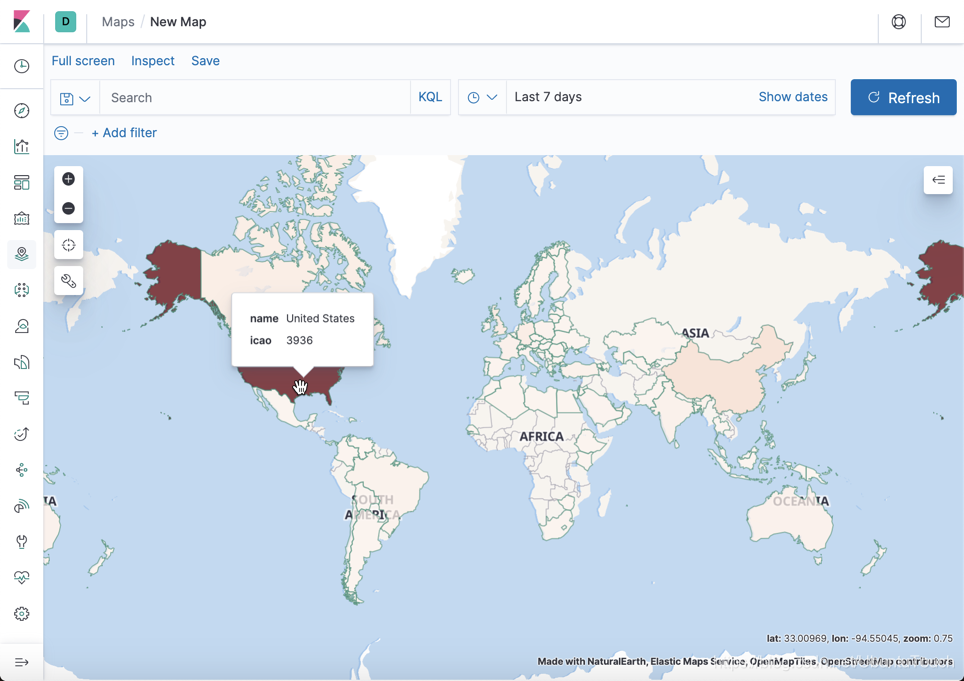
我们看一下美国有时间上最多的机场。
我们可以发现从美国起飞的飞机是最多的,颜色最深。
如果你对这个感兴趣,请阅读我的系列文章 “Observability:使用 Elastic Stack 分析地理空间数据 (二)”。
这篇关于Observability:使用 Elastic Stack 分析地理空间数据 (一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







