本文主要是介绍爬虫项目实战五:爬取无印良品,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取无印良品门店信息
- 目标
- 项目准备
- 网站分析
- 反爬分析
- 网址分析
- 代码实现
- 效果显示
目标
爬取城市无印良品门店信息,保存为csv文件到本地。
项目准备
软件:Pycharm
第三方库:requests,fake_useragent,csv
网站地址:https://www.muji.com/storelocator/?c=cn
网站分析
打开网站看一下。

抓包看一下F12检查元素选择Network,输入框要输入一下城市名称。这里尝试输入上海市。
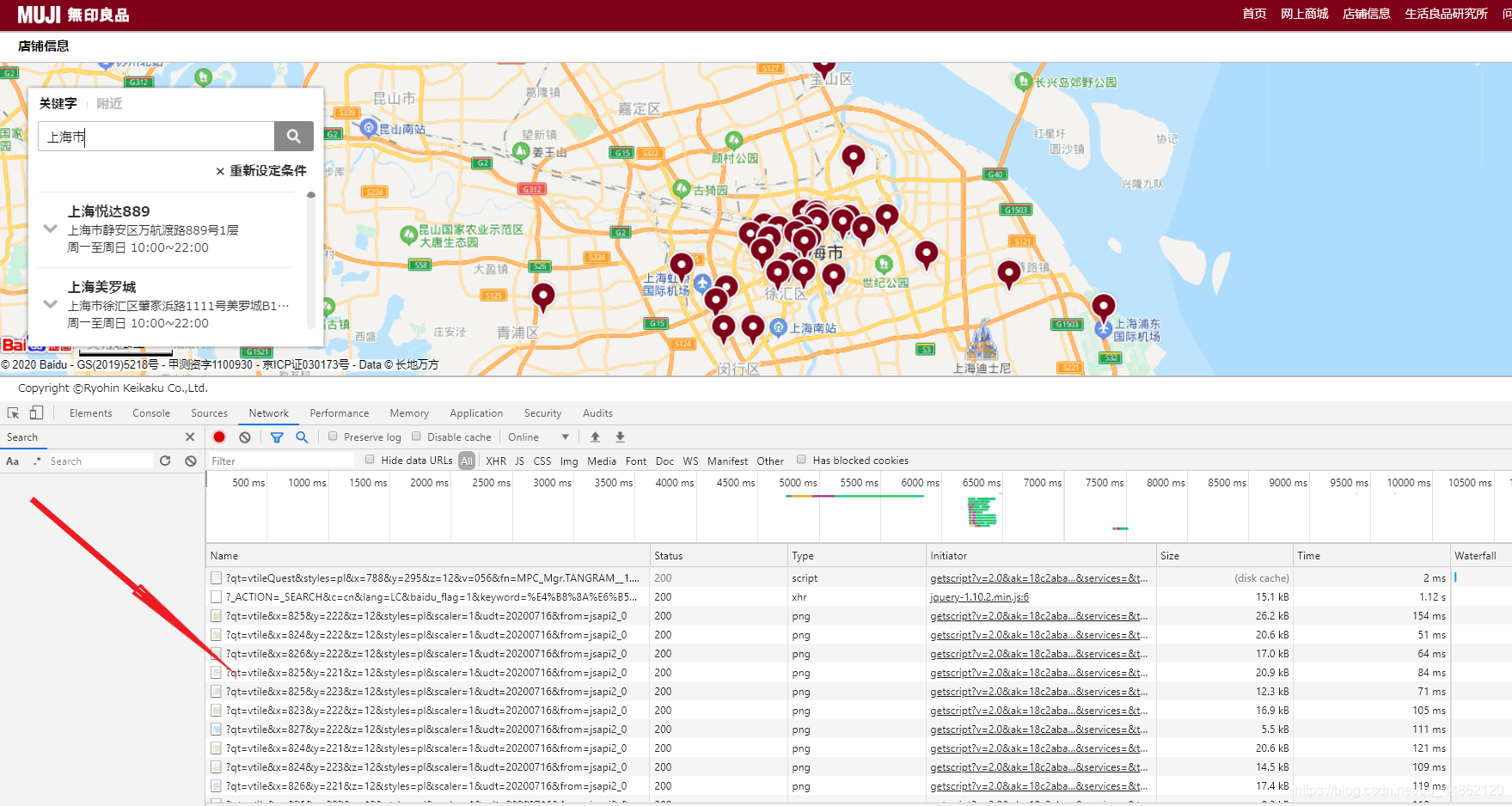
这是各种数据包。
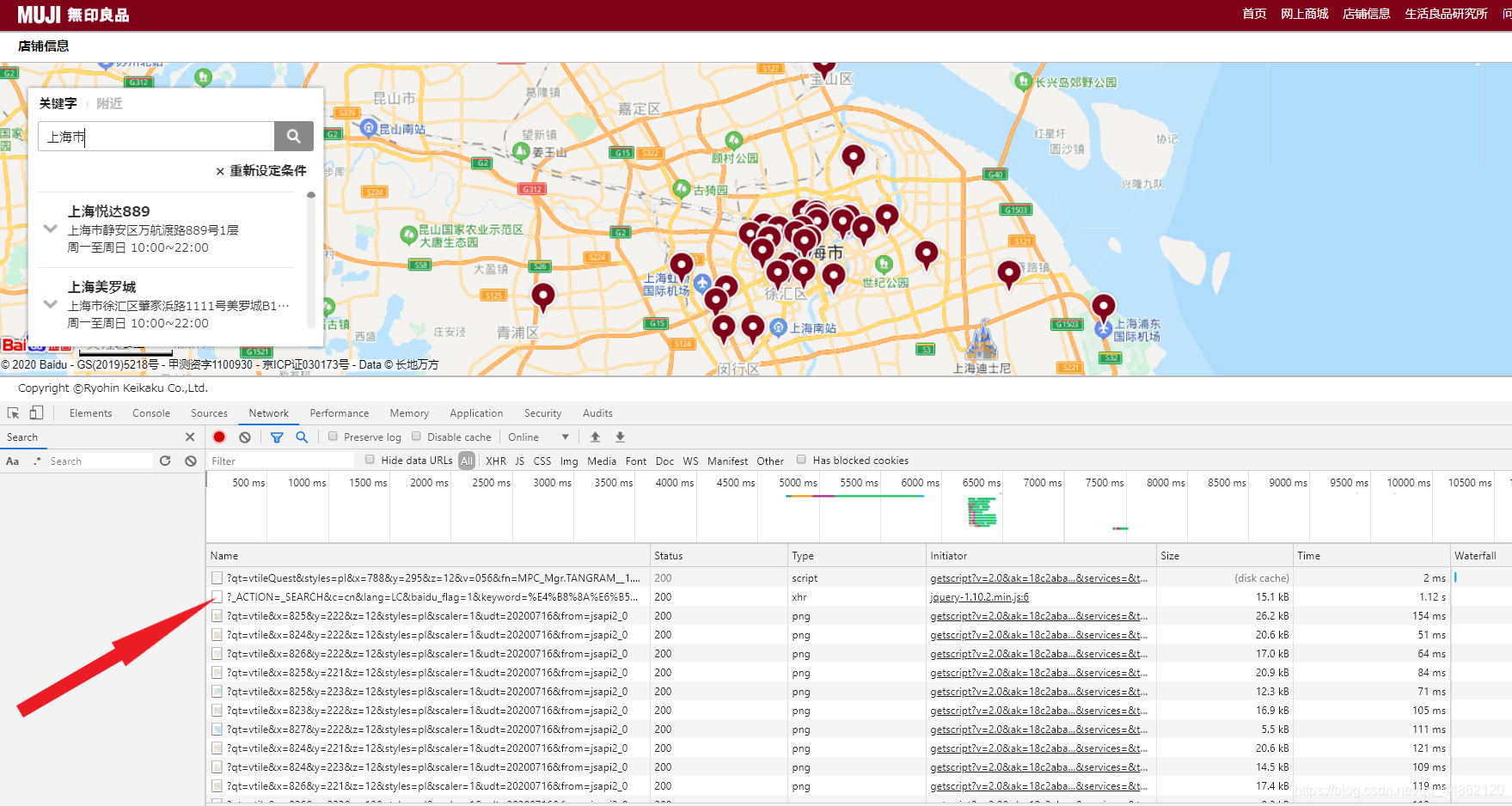
打开这个数据包,会发现这里就是很多门店的详情信息。

反爬分析
同一个ip地址去多次访问会面临被封掉的风险,这里采用fake_useragent,产生随机的User-Agent请求头进行访问。
网址分析

真实的链接地址,试一下能不能找到什么规律。
https://www.muji.com/storelocator/_ACTION=_SEARCH&c=cn&lang=LC&baidu_flag=1&keyword=%E4%B8%8A%E6%B5%B7%E5%B8%82
https://www.muji.com/storelocator/_ACTION=_SEARCH&c=cn&lang=LC&baidu_flag=1&keyword=%E8%8B%8F%E5%B7%9E%E5%B8%82
输入几个不同的城市,发现只有后面keyword=后面的发生变化。经过验证,在其后输入城市名称就可以成功访问。
代码实现
1.导入相对应的第三方库,定义一个class类继承object,定义init方法继承self,主函数main继承self。
import requests
from fake_useragent import UserAgent
import csv
class MUJI(object):def __init__(self):self.url='https://www.muji.com/storelocator/?_ACTION=_SEARCH&c=cn&lang=LC&baidu_flag=1&keyword={}'ua = UserAgent(verify_ssl=False)for i in range(1, 100):self.headers = {'User-Agent': ua.random}def main(self):pass
if __name__ == '__main__':spider = MUJI()spider.main()
2.发送请求,获取网页。
def get_html(self,url):response=requests.get(url,headers=self.headers)html=response.json()#html=response.content.decode('unicode_escape')return html
开始的时候会面临这样的问题:

这里会出现这样的编码格式。不过没什么影响,经过查阅资料使用html=response.content.decode('unicode_escape')可以转化为汉字。
3.解析网页并保存。
def parse_html(self,html):for data in html:shopname=data['shopname']shopaddress=data['shopaddress']opentime=data['opentime']tel=data['tel']#print(shopname,opentime,shopaddress,tel)with open('F:/pycharm文件/document/data.csv', 'a', newline='') as f:csvwriter = csv.writer(f, delimiter=',')csvwriter.writerow([shopname,opentime,shopaddress,tel])
4.主函数及函数调用。
def main(self):address=str(input('请输入要查询的城市:'))url=self.url.format(address)html=self.get_html(url)self.parse_html(html)
效果显示

打开文件目录,会自动生成一个data.csv文件。
打开看一下。

完整代码如下:
import requests
from fake_useragent import UserAgent
import csv
class MUJI(object):def __init__(self):self.url='https://www.muji.com/storelocator/?_ACTION=_SEARCH&c=cn&lang=LC&baidu_flag=1&keyword={}'ua = UserAgent(verify_ssl=False)for i in range(1, 100):self.headers = {'User-Agent': ua.random}def get_html(self,url):response=requests.get(url,headers=self.headers)html=response.json()#html=response.content.decode('unicode_escape')return htmldef parse_html(self,html):for data in html:shopname=data['shopname']shopaddress=data['shopaddress']opentime=data['opentime']tel=data['tel']#print(shopname,opentime,shopaddress,tel)with open('F:/pycharm文件/document/data.csv', 'a', newline='') as f:csvwriter = csv.writer(f, delimiter=',')csvwriter.writerow([shopname,opentime,shopaddress,tel])def main(self):address=str(input('请输入要查询的城市:'))url=self.url.format(address)html=self.get_html(url)self.parse_html(html)
if __name__ == '__main__':spider = MUJI()spider.main()
声明:仅做自己学习参考使用。
这篇关于爬虫项目实战五:爬取无印良品的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








