
不想弹好吉他的撸铁狗,都不是好的程序猿
虽然说单机的Redis性能很好,也有完备的持久化机制,那如果你的业务体量真的很大,超过了单机能够承载的上限了怎么办?不做任何处理的话Redis挂了怎么办?带着这个问题开始我们今天的主题-Redis高可用,由于篇幅原因,本章就只聊聊主从复制。
为啥要先从主从复制开始聊,是因为主从复制可以说是整个Redis高可用实现的基石,你可以先有这么一个概念,至于具体为什么是基石,这个后面聊到Sentinel和Redis集群的时候会说到。
首先我们需要知道,对于我们开发人员来说,为什么需要主从架构?一个Redis实例难道不行吗?
其实除了开篇提到的负载超过了Redis单机能够处理的上限,还有一种情况Redis也无法保证自身的高可用性。那就是即便Redis能够扛住所有流量,但是如果这个Redis进程所在的机器挂了呢?请求会直接调转枪口,大量的流量会瞬间把你的DB打挂,然后你就可以背个P0,打包回家了。
而且,假设你对Redis的需求真的超过了单机的容量,你怎么办?搞多台独立的Redis实例吗?那如果用户缓存的数据这一次存在了实例一,下一次如果用户又访问到了实例二,难道又要去走一遍DB吗?除非你能够维护好用户和Redis实例的对应关系(但是通常这样的逻辑比较复杂),否则部署多个Redis实例也就失去了它的意义,没有办法做到横向扩展了。
那换成主从架构就能解决这个问题吗?
我们可以从一个图来直观的了解一下。
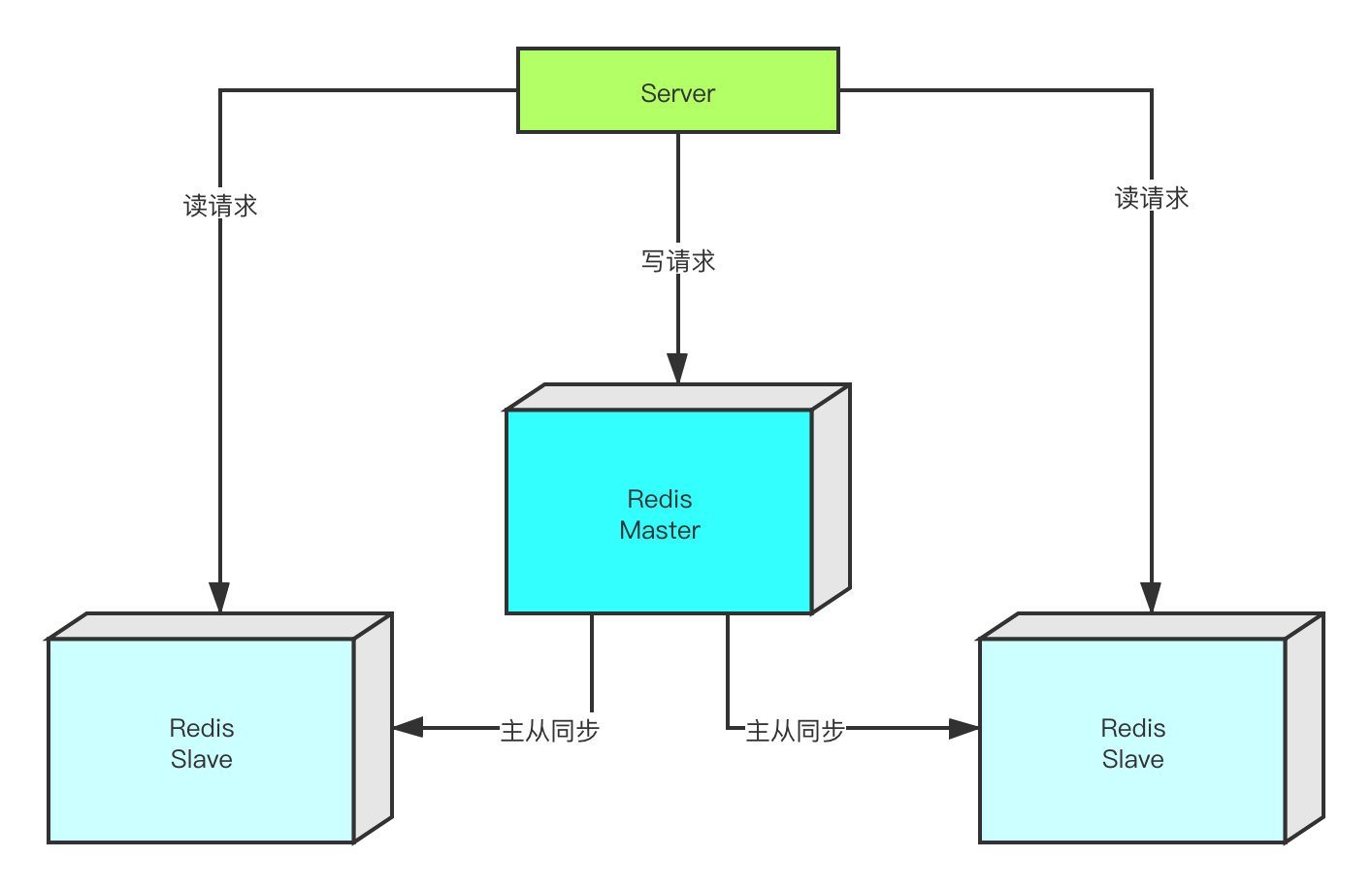
在主从同步中,我们将节点的角色划分为master和slave,形成一主多从。slave对外提供读操作,而master负责写操作,形成一个读写分离的架构,这样一来就能够承载更多的业务请求。
在多数的业务场景下,对于Redis的读操作都要多于写操作,所以当读请求量特别大的时候,我们可以通过增加slave节点来使Redis扛住更多的流量。
你这不行啊老弟,你往master写数据,那我要是连接到slave上去了,不就拿不到之前的数据了?
我这个小标题的不是写了吗?主从复制,slave会按照某种策略从master同步数据。Redis中我们可以通过slaveof命令让一个Redis实例去复制(replicate)另外一台Redis的状态。被复制的Redis实例就是master节点,而执行slaveof命令的机器就是slave节点。
Redis的主从复制分为两个步骤,分别是同步和命令传播。
同步操作用于将Master节点内存状态复制给Slave节点,而命令传播则是在同步时,客户端又执行了一些写操作改变了服务器的状态,此时master节点的状态与同步操作执行的时候不一致了,所以需要命令传播来使master和slave状态重新一致。
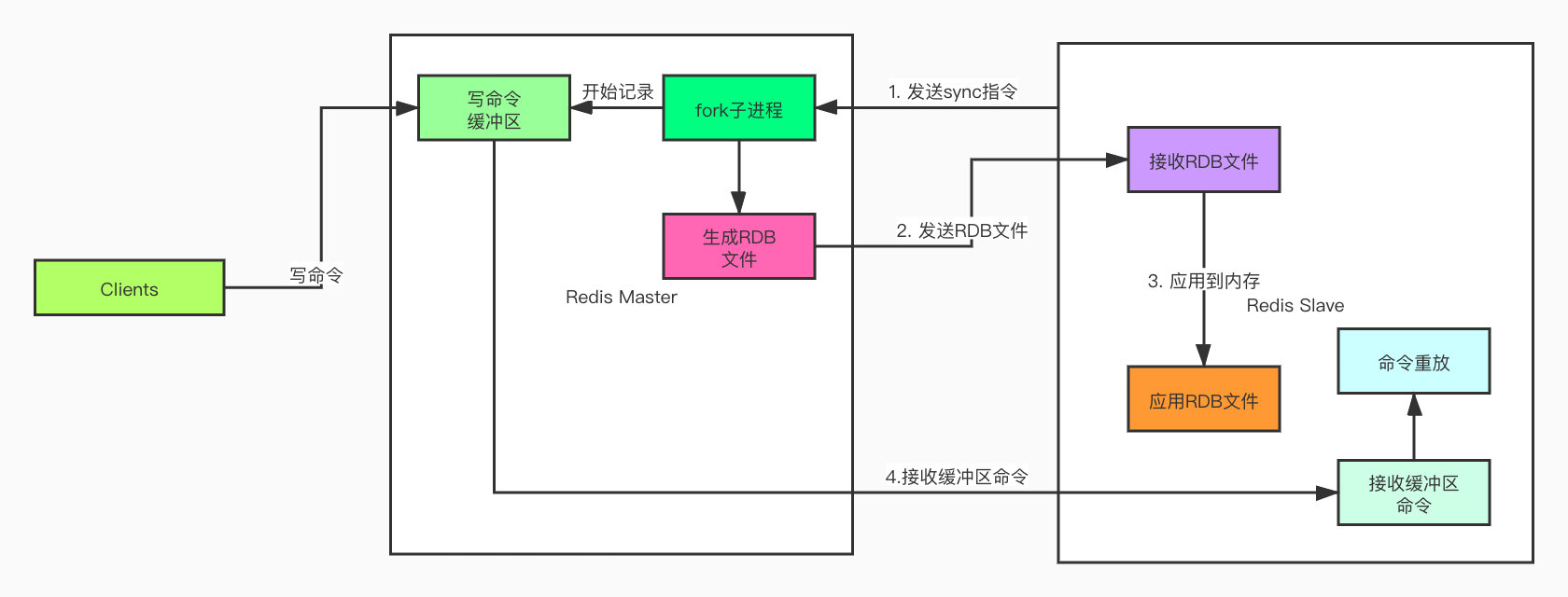
同步的大致的流程如下:
- slave节点向master节点发送
sync命令 - master收到
sync命令之后会执行bgsave命令,Redis会fork出一个子进程在后台生成RDB文件,同时将同步过程中的写命令记录到缓冲区中 - 文件生成后,master会把RDB文件发送给slave,从服务器接收到RDB文件会将其载入内存
- 然后master将记录在缓冲区的所有写命令发送给slave,slave对这些命令进行重放,将其数据库的状态更新至和master一致
为了让大家更加清晰的认识到这个过程,我们通过图再来了解一下。
🐂🍺,那如果同步完了之后slave又挂了咋办?slave重启之后很可能就又跟maste不一致了?
的确是这样,这就涉及到一个名词叫断点续传了。上面讨论的是slave第一次连接到master,会执行全量复制,而针对上面这种情况,Redis新老版本处理方式不一样。
Redis2.8之前,当主从完成了同步之后,slave如果断线重连,向master发送sync命令,master会将全量的数据再次同给slave。
但是我们会发现一个问题,就是大部分数据都是有序的,再次全量同步显得没有必要。而在 Redis2.8之后,为了解决这个问题,便使用了psync命令来代替sync。
简单来说psync命令就是将slave断线期间master接收到的写命令全部发送给slave,slave重放之后状态便与master一致了。
呵呵,就这?那你知道psync具体怎么实现的吗?还是说就只会用用?
psync的实现依赖于主从双方共同维护的offset偏移量。
每次master向slave进行命令传播,传播了多少个字节的数据,就将自己的offset加上传播的字节数。而slave每次收到多少字节的数据,也会同样的更新自己的offset。
基于offset,只需要简单的比对就知道当前主从的状态是否是一致的了,然后基于offset,将对应偏移量所对应的指令传播给slave重放即可。所以即使同步的时候slave挂掉了,基于offset,也能达到断点续传的效果。
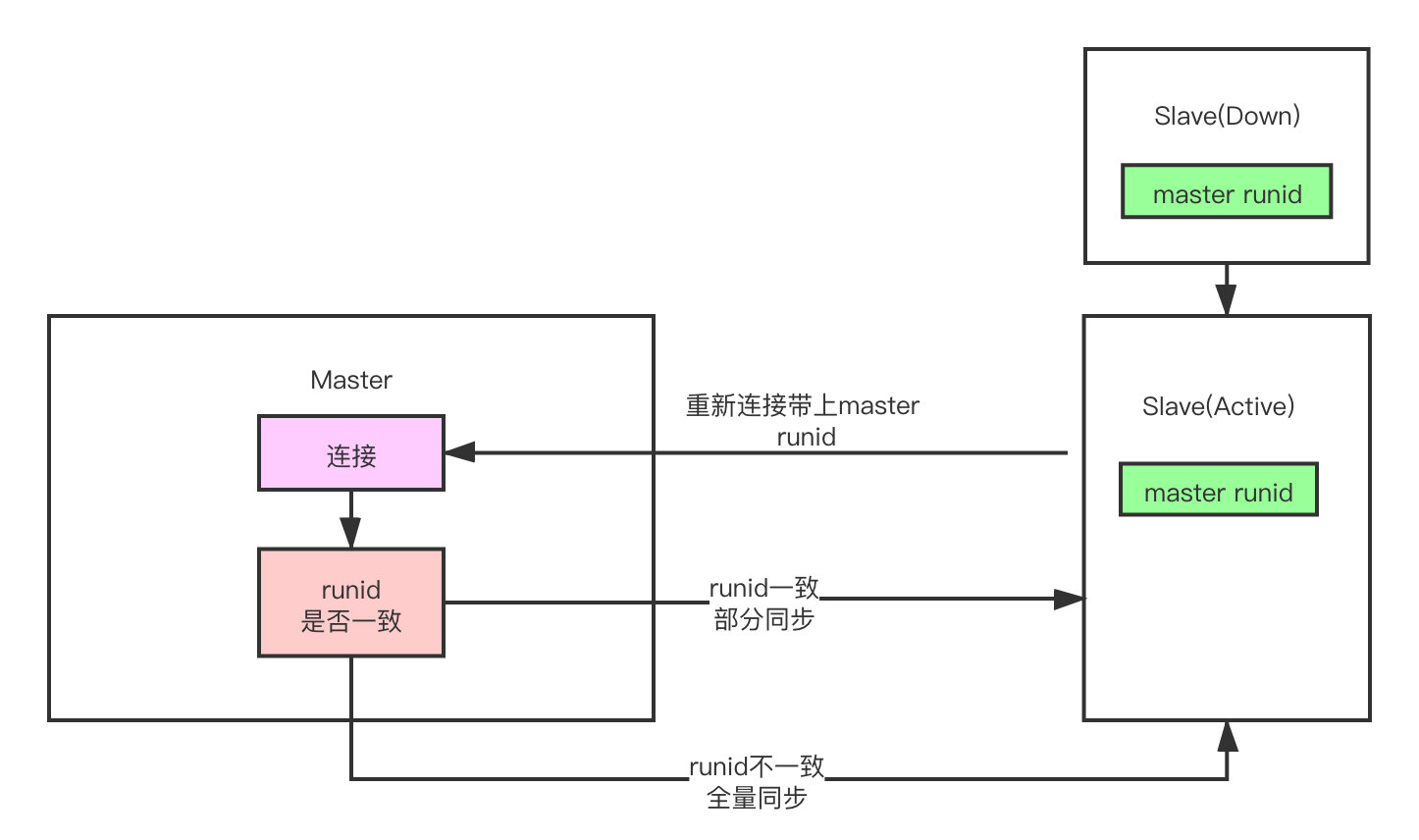
不是吧不是吧,那master也挂了呢?你slave重新启动之后master的数据也更新了,按照你的说法,这两永远不可能达到数据一致了
这个问题Redis的确也有想到,实际上除了offset之外,slave断线重连之后还会带上上一个master的实例的runid,每个服务实例都有自己的唯一的runid,只要Redis服务重启,其runid就会发生改变。
master收到这个runid之后会判断是否与自己当前的runid一致,如果一致说明断线之前还是与自己建立的连接,而如果不一致就说明slave断线期间,master也发生了宕机,此时就需要将数据全量同步给slave了。
就算你能解决这个问题,但是你就维护了一个偏移量,偏移量对应的命令从哪儿来?天上掉下来吗?我哪儿知道这些命令是啥?
的确,我们需要通过这个offset去拿到真正需要的数据—也就是指令,而Redis是通过复制积压缓冲区来实现的。
名字高大上,实际上就是一队列。就跟什么递归、轮询、透传一样,听着高大上,实际上简单的一匹。言归正传,复制积压缓冲区的默认大小为1M,Redis在进行命令传播时,除了将写命令发送给slave,还会将命令写到复制积压缓冲区内,并和当前的offset关联起来。这样一来就能够通过offset获取到对应的指令了。
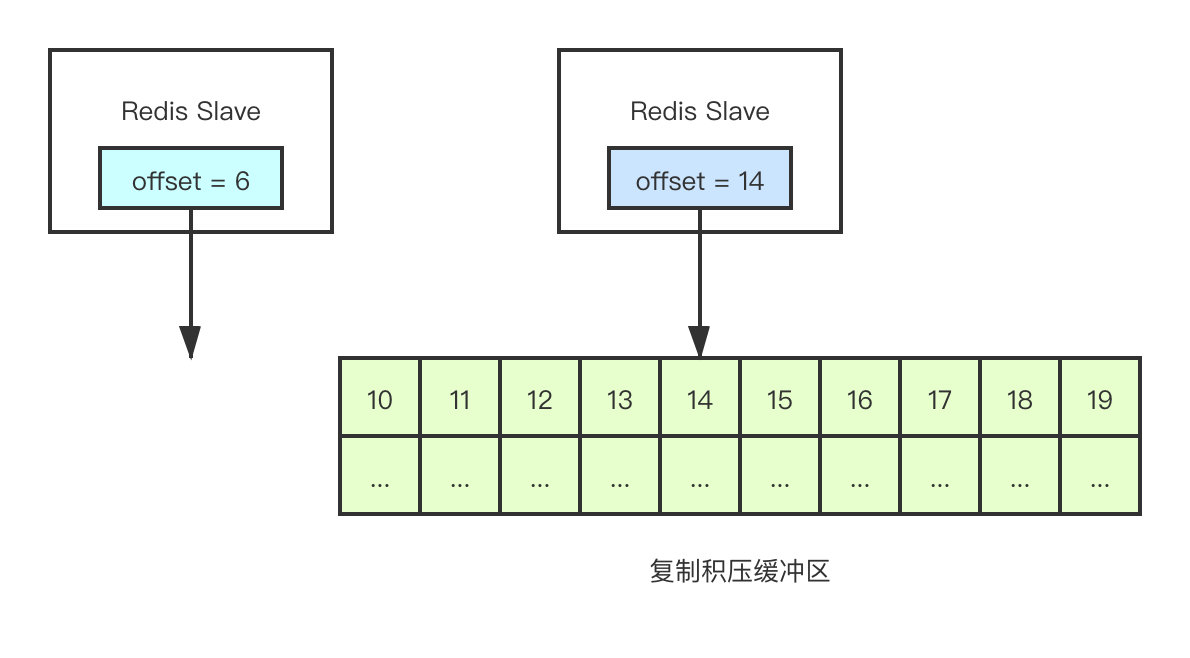
但是由于缓冲区的大小有限,如果slave的断线时间太久,复制积压缓冲区内早些时候的指令就已经被新的指令覆盖掉了,此处可以理解为一个队列,早些时候入队的元素已经被出队了。
由于没有相对应的offset了,也就无法获取指令数据,此时Redis就会进行全量同步。当然,如果offset还存在于复制积压缓冲区中,则按照对应的offset进行部分同步。
基于以上的全量、增量的主从复制,能够在master出现故障的情况下,进行主从的切换,保证服务的正常运行。除此之外还能解决异常情况下数据丢失的问题。基于读写分离的策略还能够提高整个Redis服务的并发量。
可别吹了,你说的这个什么主从复制就没啥缺点吗?
其实是有的,例如刚刚提到的主从的切换,如果不用现成的HA框架,这个过程需要程序员自己手动的完成,同时通知服务调用方Redis的IP发生了变化,这个过程可以说是十分的复杂,甚至还可能涉及到代码配置的改动。而且之前的slave复制的可都是挂掉的master,还得去slave上更改其复制的主库,就更加复杂了。
除此之外,虽然实现了读写分离,但是由于是一主多从的架构,集群的读请求可以扩展,但是写请求的并发是有上限的,那就是master能够扛住的上限,这个没有办法扩展。
好了,本期的分享就到此结束了,我们下期再见。
如果你觉得这篇文章对你有帮助,还麻烦点个赞,关个注,分个享,留个言
也可以微信搜索公众号【SH的全栈笔记】,关注公众号提前阅读其他的文章
往期文章
- Redis基础—剖析基础数据结构及其用法
- Redis基础—了解Redis是如何做数据持久化的
- 简单了解一下K8S,并搭建自己的集群
- WebAssembly完全入门——了解wasm的前世今生
- 浅谈JVM与垃圾回收







