本文主要是介绍一次mysql联表 join 后 order by desc 慢的排查,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
因为项目需要进行数据量测试,查看项目相关指标在预期数量中是否正常,所以,其中一项就是数据库的数据量测试,发现项目在查询的时候非常的慢。
二、问题概述
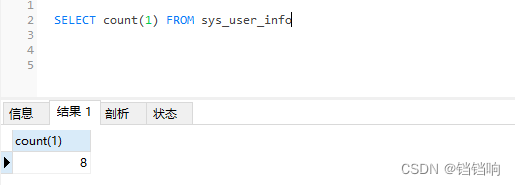
1、一张用户表 sys_user_info,和问题相关的字段,主要有以下数据,因为用户表很少,目前为8条,所以,暂时未加索引。
| 字段 | 说明 |
|---|---|
| id | 主键 |
| dept_id | 所属部门 |
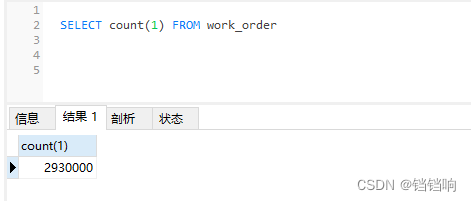
2、一张工单表 work_order,和问题相关的字段和索引,主要有以下数据 ,其中数据为 290万条数据
| 字段 | 说明 |
|---|---|
| id | 主键 |
| create_user_id | 工单创建人id,就是用户id |
| create_time | 创建时间 |
| 索引 | 说明 |
|---|---|
| idx_create_user_id | 主键 |
| idx_create_time | 工单创建人id,就是用户id |
3、现在的需求是不同用户只能看指定部门下人员的工单,而且前端在查询的时候,是有用户名称之类的查询条件的,所以,初步sql 如下
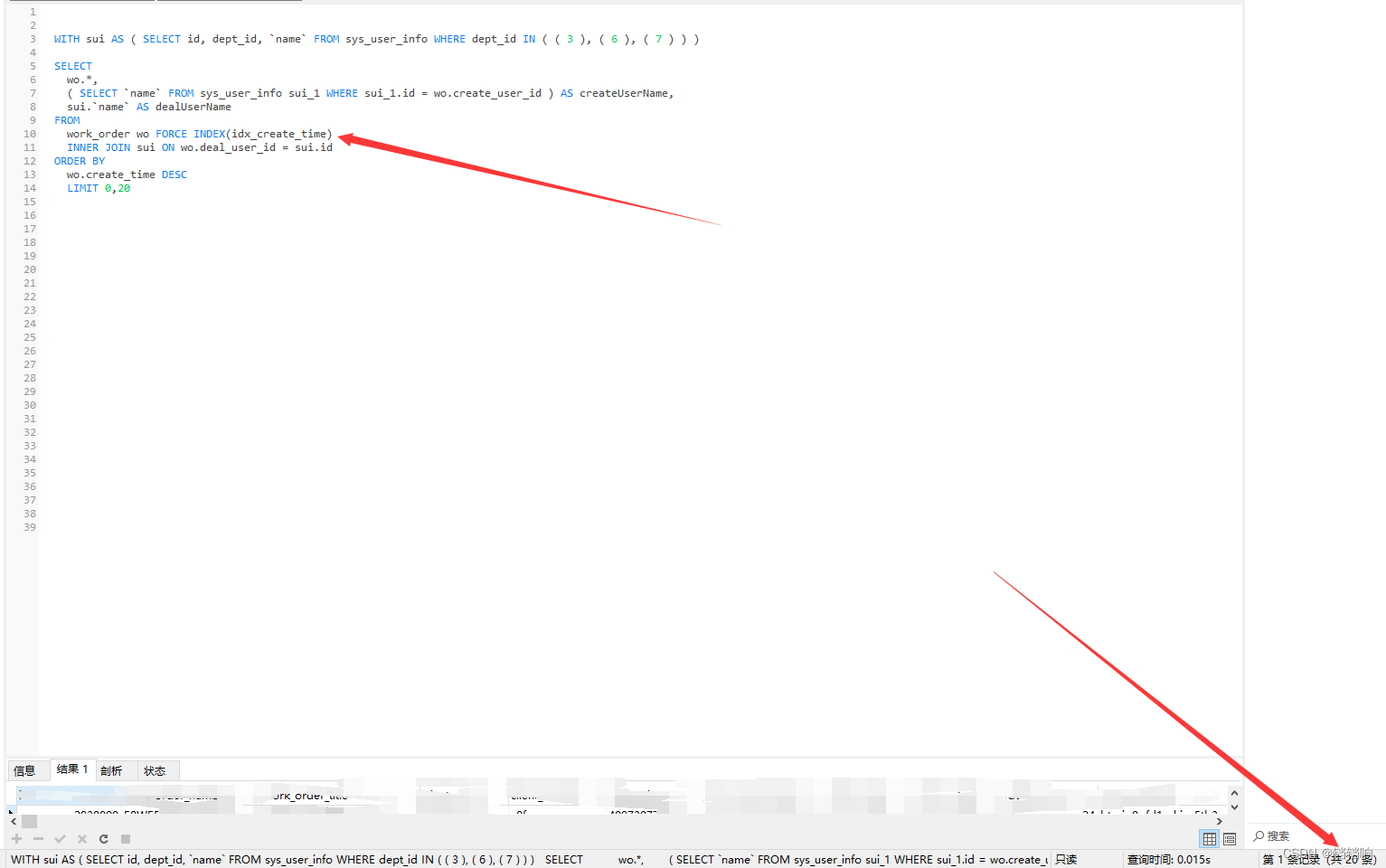
WITH sui AS ( SELECT id, dept_id, `name` FROM sys_user_info WHERE dept_id IN ( 用户可以看那些部门的id ) ) SELECTwo.*,( SELECT `name` FROM sys_user_info sui_1 WHERE sui_1.id = wo.create_user_id ) AS createUserName,sui.`name` AS dealUserName
FROMwork_order woINNER JOIN sui ON wo.deal_user_id = sui.id
ORDER BYwo.create_time DESC WHERE ......条件LIMIT 0,20
三、问题
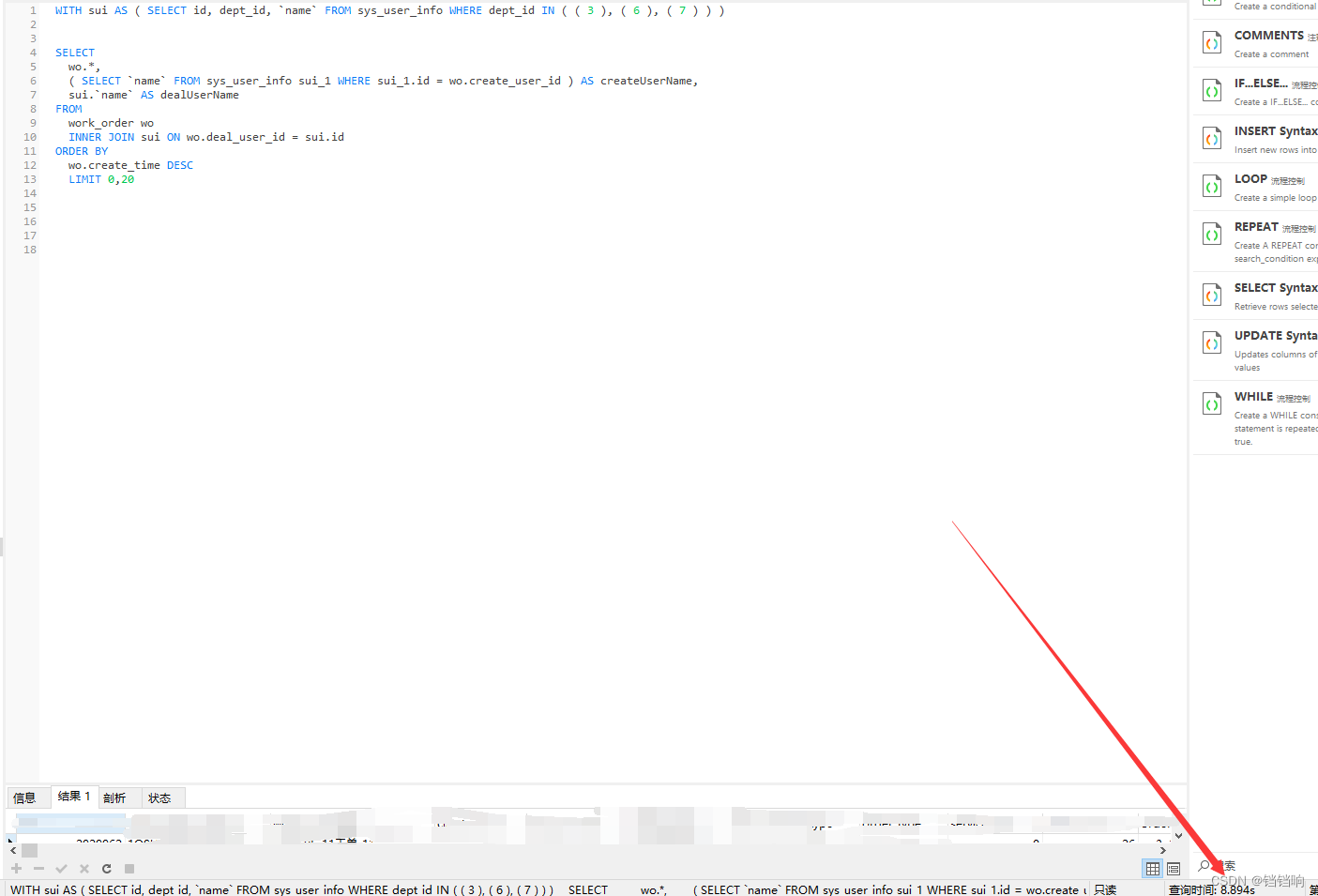
1、我们执行以下一个简单的查询,在数据量少的时候,发现没有什么问题,但是在工单表290万数据之后就出现问题了,查询耗时近9秒,实在是离谱。
WITH sui AS ( SELECT id, dept_id, `name` FROM sys_user_info WHERE dept_id IN ( ( 3 ), ( 6 ), ( 7 ) ) ) SELECTwo.*,( SELECT `name` FROM sys_user_info sui_1 WHERE sui_1.id = wo.create_user_id ) AS createUserName,sui.`name` AS dealUserName
FROMwork_order woINNER JOIN sui ON wo.deal_user_id = sui.id
ORDER BYwo.create_time DESC LIMIT 0,20
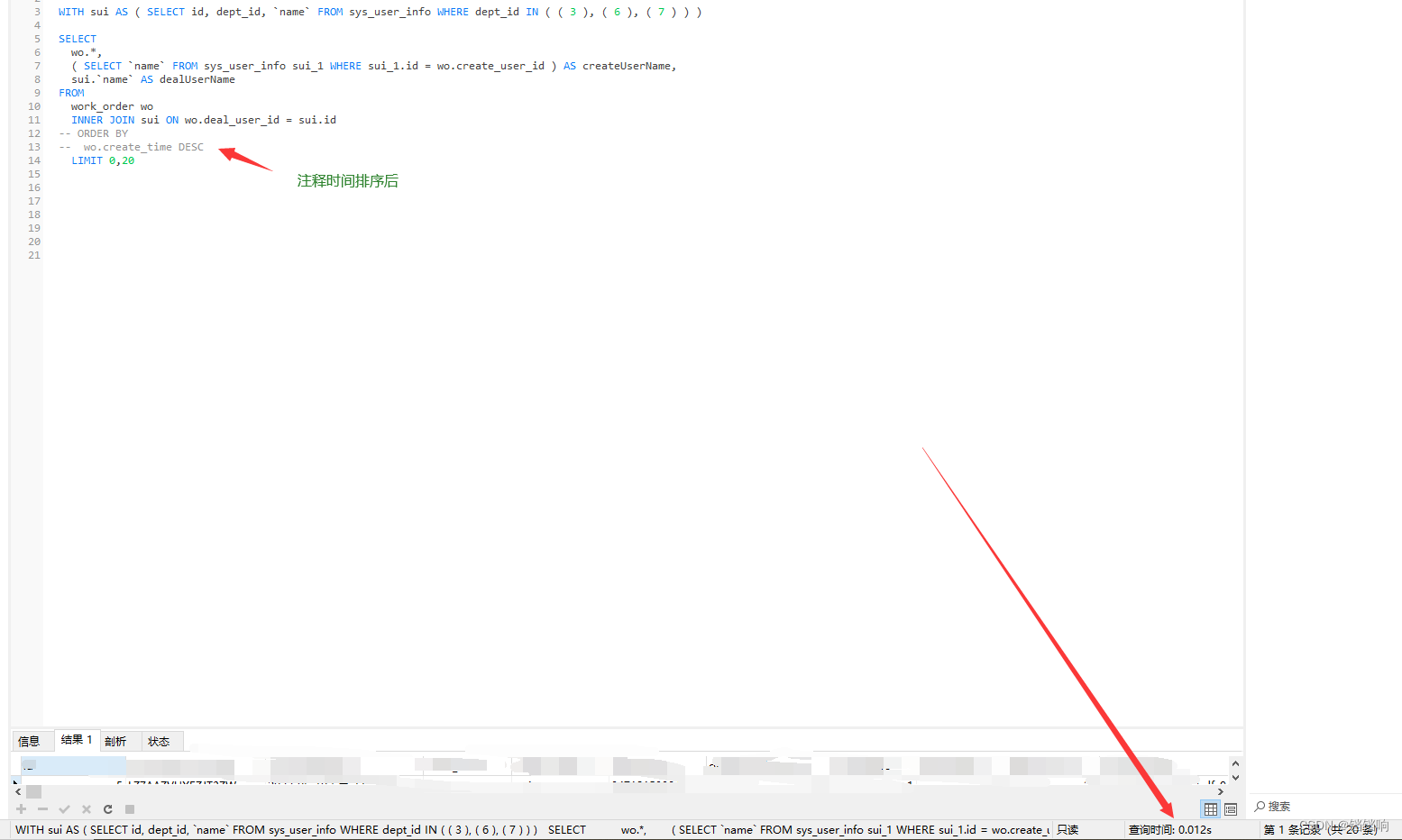
2、经过我慢慢排查发现,就是一旦我们不使用时间排序,就会发现快的起飞(当然这也是我在关键字段上加上索引的缘故,后面我会统一说)
四、方案
4.1、处理
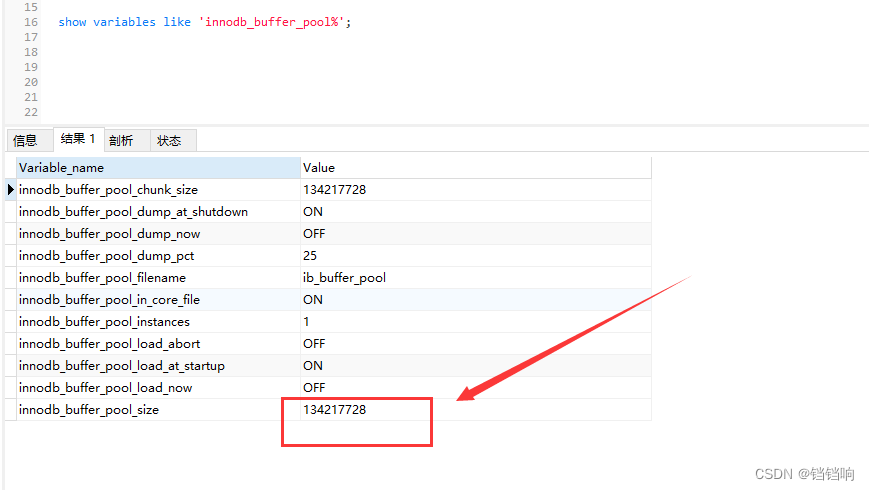
1、第一步使用 explain 和 show profiles 来查看自己的sql有没有问题,看看是不是自己预期的情况,是不是 innodb_buffer_pool_size大小的问题。可以看下这个 一次mysql order by desc 慢的排查,个人觉得是比较好的。但是,我这边这个值已经是 1G了,但是效果还是很不理想,所以我暂时排除了这个方案。
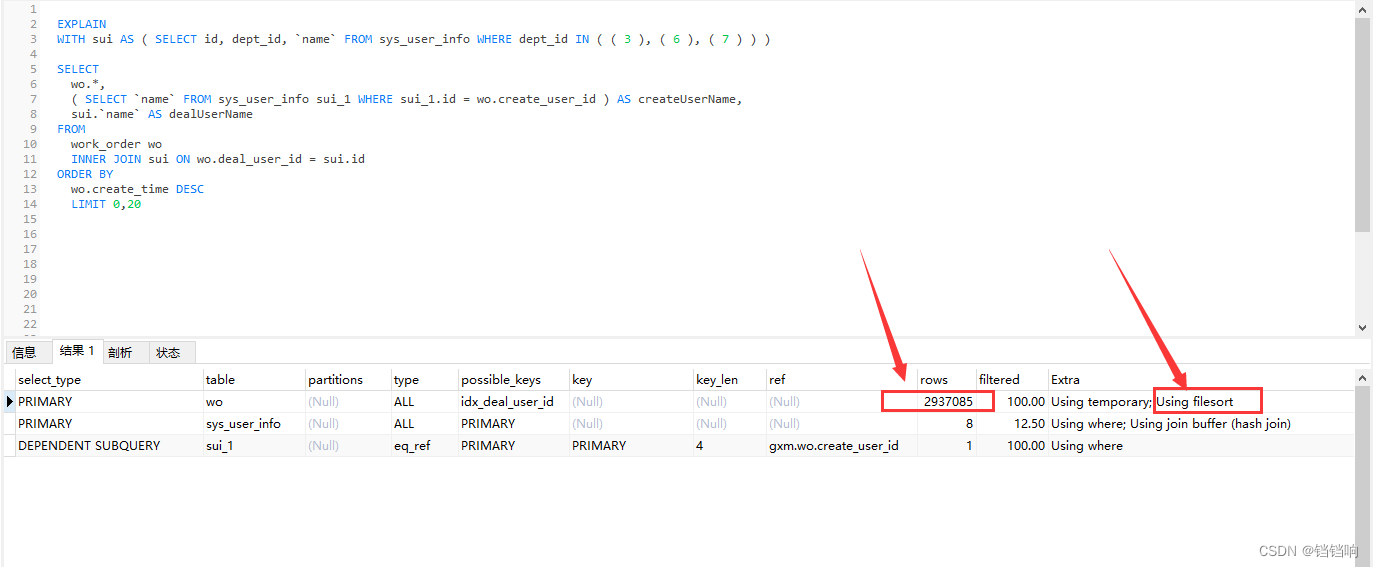
2、我使用 explain命令查看后,可以看到我们在使用时间字段排序的时候,rows是293万行?这就是很离谱了,这就说明为什么那么慢了,而且看到最后一行 filesort就知道,我们该优化这个Sql了。
这个为什么是293万,为什么会比工单表290万还大,那是因为我们使用join关联表,形成了笛卡儿积。所以,我们最好能把先过滤的表的数据形成一张子表后,再关联。
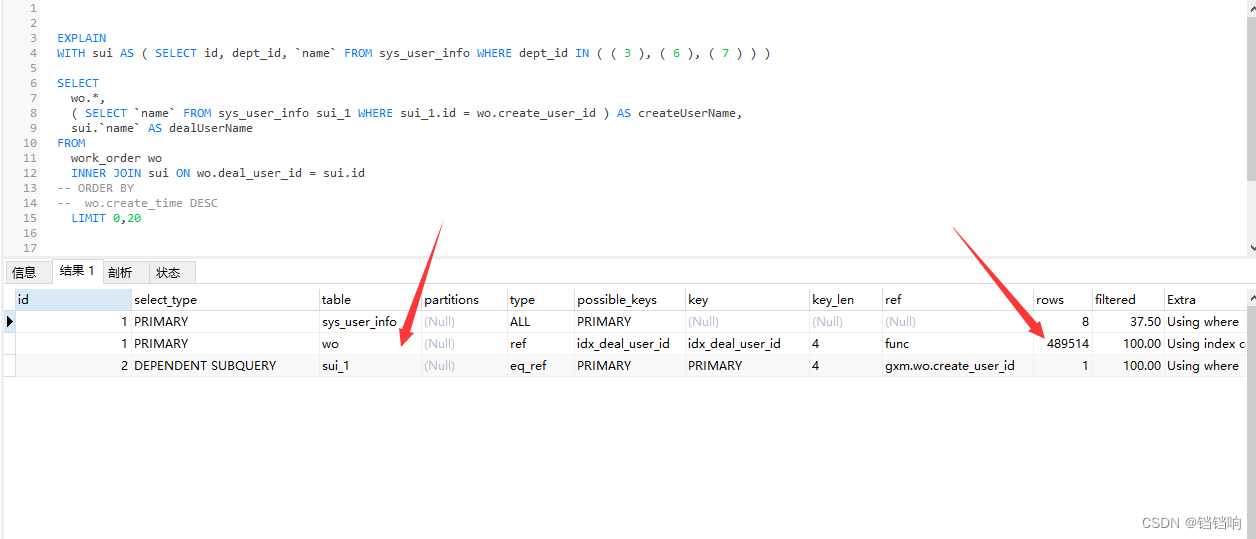
3、我们在注释时间排序后,发现只有50万左右的数据了,一下少了近 1/4。
4、所以我们得出,我们必须先让时间索引生效,在这里网上有一些不同的方式,如下
- 使用关键字
straight_join修改驱动表和被驱动表的位置 ,可以参考 MySQL中驱动表和被驱动表的解读,但是我个人是不建议改的,而且改完MySQL就不能根据实际情况更改了。 - 使用
FORCE INDEX(索引名称)来强制使用索引。
5、我这里就已第二种方式来处理,可以看到使用的日期索引,并且个数是19(从0开始)
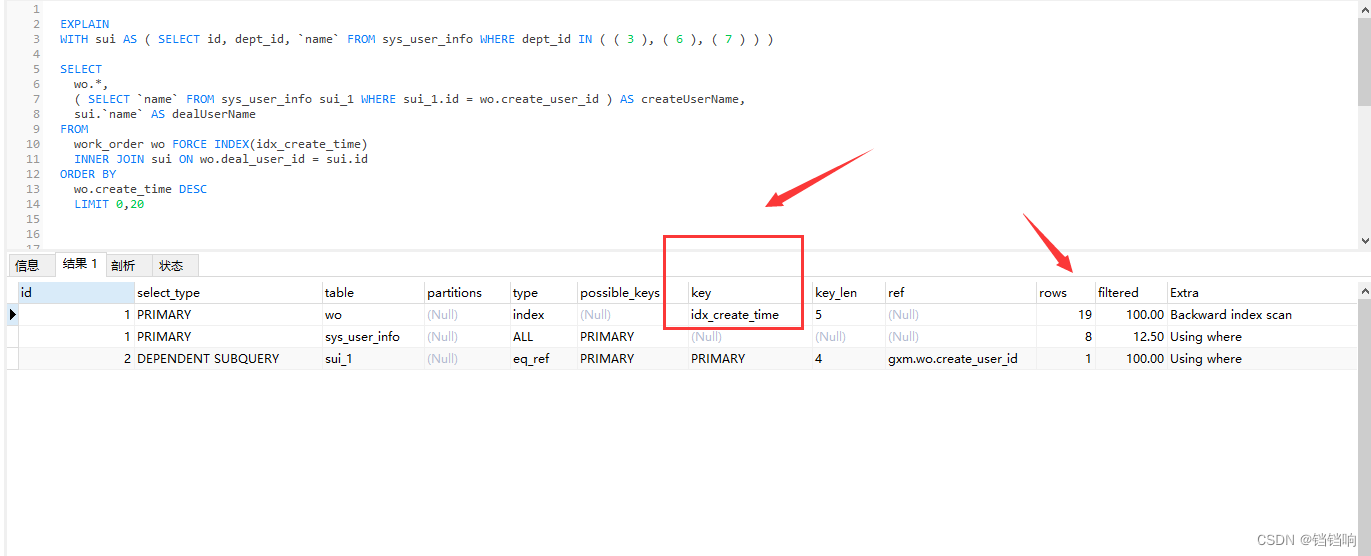
6、再看下查询速度,还是很快的。
4.2、问题的原因
1、所以总结在使用 ORDER BY wo.create_time DESC 慢的原因
- 如果我们不使用字段排序,那么使用inner join后 只需要获取第0页20条数据即可,也就是在189514条数据中找前面20条即可,所以会快很多。
- 但如果我们使用时间字段排序,这个时候我们需要对inner join的结果进行排序,而排序字段索引又没有生效(使用的是filesort),所以就很慢了。
- 至于排序字段的索引为什么不生效,我们先看下 为什么MySQL会使用
filesort,官方解释如下:
Using filesort:
MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the WHERE clause.
Mysql需要额外的一次传递,以找出如何按排序顺序检索行,通过根据联接类型浏览所有行并为所有匹配where子句的行保存排序关键字和行的指针来完成排序,然后关键字被排序,并按排序顺序检索行。
这句话直接翻译过来有点难以理解,简单说就是由于索引不满足你的sql,mysql需要对数据行进行一次额外的排序操作,这个排序操作既费空间又费时间。当数据量较少的时候并不会对应用产生多大影响,但数据量一多,就会出现非常可怕的后果,轻则服务响应变慢,重则拖垮服务,甚至引发雪崩效应导致应用宕机。
再回来看看我的sql,查询列和搜索条件应该都没有问题,那么应该order by影响了。通过搜索发现,order by 使用不当确实会导致索引失效。
五、使用 order by后查询速度很慢的可能原因。
- 由于数据库两张表的字段编码不一致导致的。
- 由于Using filesort排序导致的。
- 由于没有走索引导致的。
- 使用组合索引排序时,使用的顺序不对,需要保证顺序。
这里说一点,我们在联表查询的时候,最好相关外键都加上索引,这样会快很多。
这篇关于一次mysql联表 join 后 order by desc 慢的排查的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








