本文主要是介绍Kudu数据库详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、概要
- 2、 Kudu产品特点:
- 3 、Kudu架构
- 4、 基础概念
- 5、 服务端口
- 6、 启停命令
- 7 、kudu与impala结合
- 8、 使用限制
- 9、 使用kudu-client操作kudu
1、概要
Apache Kudu 是由 Cloudera开源的列式存储系统,可以同时提供低延迟的随机读写和高效的数据分析能力。Kudu在 HDFS 和 HBase 这两个产品中平衡了随机读写和批量分析的性能。 Kudu 支持水平扩展,并且与 Cloudera Impala 和Apache Spark等当前流行的大数据查询和分析工具结合紧密。适用于既要随机读写,又需要批量分析的大数据分析(OLAP)场景。
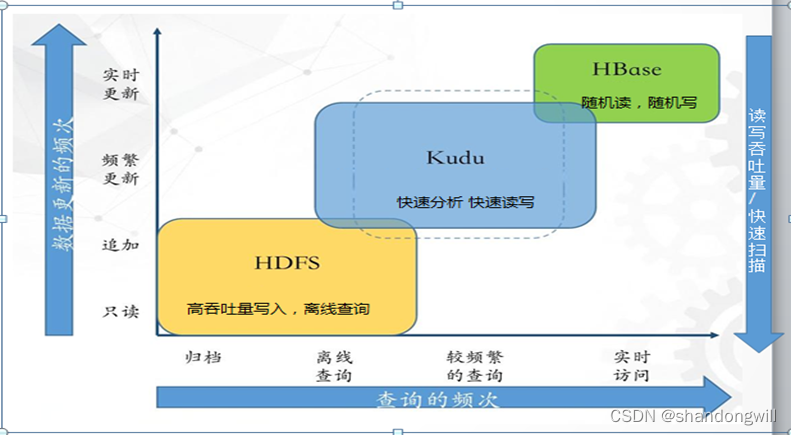
2、 Kudu产品特点:
- 同时提供低延迟的随机读写和高效的数据分析能力
- Kudu支持水平扩展
- 与Impala和Spark等当前流行的大数据查询和分析工具无缝结合
- Kudu提供了行级的插入、更新、删除API
- 提供了接近Parquet性能的批量扫描操作
- 使用同一份存储,既可以进行随机读写,也可以满足数据分析的要求
3 、Kudu架构
Kudu采用了Master-Slave形式的中心节点架构,管理节点被称作Kudu Master,数据节点被称作Tablet Server。master主要负责:管理元数据信息,监听server,当server宕机后负责tablet的重分配。Tablet server主要负责tablet的存储与和数据的增删改查。一个表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
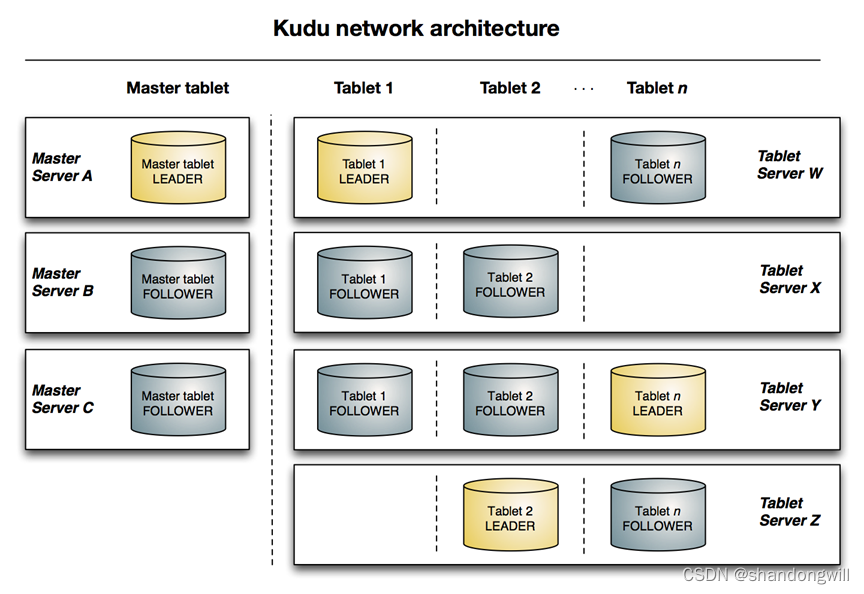
上图显示了一个具有三个 master 和多个tablet server的Kudu集群,每个服务器都支持多个tablet。Tablet server 和 Master 使用 Raft Consensus Algorithm 来保证节点的高可用。此外,tablet server 可以成为某些 tablet 的 leader,也可以是其他 tablet follower。leader以金色显示,而 follower 则显示为蓝色。
4、 基础概念
-
Table(表):一张table是数据存储在kudu的位置。Table具有schema和全局有序的primary key(主键)。Table被分为很多段,也就是tablets.
-
Tablet (段):一个tablet是一张table连续的segment,与其他数据存储引擎或关系型数据的partition相似。Tablet存在副本机制,其中一个副本为leader tablet。任何副本都可以对读取进行服务,并且写入时需要在所有副本对应的tablet server之间达成一致性。
-
Tablet server:存储tablet和为tablet向client提供服务。对于给定的tablet,一个tablet server充当leader,其他tablet server充当该tablet的follower副本。只有leader服务写请求,leader与follower为每个服务提供读请求。
-
Master:主要用来管理元数据(元数据存储在只有一个tablet的catalog table中),即tablet与表的基本信息,监听tserver的状态
-
Catalog Table: 元数据表,用来存储table(schema、locations、states)与tablet(现有的tablet列表,每个tablet及其副本所处tserver,tablet当前状态以及开始和结束键)的信息。
-
分区: Range Partitioning ( 范围分区 ), Hash Partitioning ( 哈希分区 ), Multilevel Partitioning ( 多级分区 )
哈希分区有利于最大限度地提高写入吞吐量,而范围分区可避免 tablet 无限增长的问题;hash分区和range分区结合,可提升kudu性能
5、 服务端口
Master server WEB UI界面地址http://10.68.8.65:8051/
Tablet server WEB UI界面地址http://10.68.8.65:8050/
客户端与Master通信端口7051
客户端与tablet节点的通信端口7050
6、 启停命令
systemctl start kudu-master.service
systemctl start kudu-tserver.service
systemctl stop kudu-master.service
systemctl stop kudu-tserver.service
注意:每个节点都需要用命令挨个启动
7 、kudu与impala结合
kudu与impala结合可以使用sql对kudu进行操作,简化
${IMPALA_HOME}/shell/impala-shell
创建内部表
CREATE TABLE my_table1
( id BIGINT,name STRING,PRIMARY KEY(id))
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES(‘kudu.master_addresses’ = ‘10.68.7.xx:7051’
);
创建外部表
CREATE EXTERNAL TABLE ys_user STORED AS KUDU
TBLPROPERTIES( ‘kudu.table_name’ = ‘ys_user’, ‘kudu.master_addresses’ = ‘10.68.7.xx:7051’);
查询语句
select * from default_vals;
merge语句示例:
upsert into default_vals(id,name,address,age) values(102,‘hello2’,‘山东’,22);
8、 使用限制
- 表最多可以有300列
- 单个单元格的值在编码或压缩前不能大于64KB
- 行的大小:虽然单个单元可能高达64KB,而Kudu最多支持300列,但建议单行不要大于几百KB。
- 有效的标识符:表名和列名等标识符必须是有效的UTF-8序列且不超过256个字节。
- 不可变的主键(Immutable Primary Keys):kudu不允许更新一行的主键列
- 不可更改的主键(Non-alterable Primary Key):Kudu不允许在创建表后更改主键列。
- 不可更改的分区(Non-alterable Partitioning):Kudu不允许在创建表后更改表的分区方式,删除和增加范围分区除外
- 不可更改的列类型(Non-alterable Column Types):Kudu不允许修改列的类型
- 仅支持行级事务, 不支持多行事务操作
- 主键有索引,不支持二级索引(Secondary indexes)。
9、 使用kudu-client操作kudu
创建表
public static void testCreateTable(KuduClient client, String tableName) throws KuduException {if (!client.tableExists(tableName)) {ArrayList<ColumnSchema> columnSchemas = new ArrayList<>();columnSchemas.add(new ColumnSchema.ColumnSchemaBuilder("id", Type.STRING).key(true).build());columnSchemas.add(new ColumnSchema.ColumnSchemaBuilder("int_value", Type.INT64).build());columnSchemas.add(new ColumnSchema.ColumnSchemaBuilder("bigint_value", Type.INT64).build());Schema schema = new Schema(columnSchemas);CreateTableOptions options = new CreateTableOptions();List<String> partitionList = new ArrayList<>();// kudu表的分区字段是什么 TODOpartitionList.add("id");// 按照id.hashcode % 分区数 = 分区号options.addHashPartitions(partitionList, 3);client.createTable(tableName, schema, options);}}
插入数据
public static void testInsert() throws KuduException {String master = "kudu1:7051,kudu2:7051,kudu3:7051";KuduSession session = null;try {KuduClient client = new KuduClient.KuduClientBuilder(master).build();String tableName = "my_first2";testCreateTable(client, tableName);session = client.newSession();KuduTable table = client.openTable(tableName);SessionConfiguration.FlushMode mode;Timestamp d1 = null;Timestamp d2 = null;long millis;long seconds;int recordCount = 100000;mode = SessionConfiguration.FlushMode.MANUAL_FLUSH;d1 = new Timestamp(System.currentTimeMillis());
// insertManual(session, table, recordCount);insertInAutoSync(session, table, recordCount);d2 = new Timestamp(System.currentTimeMillis());millis = d2.getTime() - d1.getTime();seconds = millis / 1000 % 60;System.out.println(mode.name() + "耗时秒数:" + seconds);} catch (KuduException e) {e.printStackTrace();} catch (Exception e) {e.printStackTrace();} finally {if (session != null) {session.close();}}}// 仅支持自动flush的测试用例public static void insertInAutoSync(KuduSession session, KuduTable table, int recordCount) throws Exception {// SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND// SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC// SessionConfiguration.FlushMode.MANUAL_FLUSHSessionConfiguration.FlushMode mode = SessionConfiguration.FlushMode.AUTO_FLUSH_SYNC;// 如果不设置,默认是1000session.setFlushMode(mode);for (int i = 0; i < recordCount; i++) {Insert insert = table.newInsert();PartialRow row = insert.getRow();UUID uuid = UUID.randomUUID();row.addString("id", uuid.toString());row.addLong("int_value", 20000L+i);row.addLong("bigint_value", 20000L);session.apply(insert);}}查询数据
public static void query() throws KuduException {String master = "kudu1:7051,kudu2:7051,kudu3:7051";String tableName = "my_first2";KuduPredicate predicate1;//创建KuduClient KuduClient client = new KuduClient.KuduClientBuilder(master).build();KuduTable table = client.openTable(tableName);KuduScannerBuilder kuduScannerBuilder = client.newScannerBuilder(client.openTable(tableName));List<String> columns = Arrays.asList("id", "int_value", "bigint_value");kuduScannerBuilder.setProjectedColumnNames(columns);//查询KuduScanner kuduScanner = kuduScannerBuilder.build();while (kuduScanner.hasMoreRows()) {RowResultIterator rowResults = kuduScanner.nextRows();int numRows = rowResults.getNumRows();totalRows=totalRows+numRows;System.out.println("numRows count is : " + numRows);Long end=System.currentTimeMillis();System.out.println("totalRows "+totalRows);}}
这篇关于Kudu数据库详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






